上一篇:《STL源码剖析》笔记-hash_multiset、hash_multimap
STL提供了很多算法,以下列出部分常用的简单算法,一些稍微复杂的算法会在本文后面进行说明。
int main(int argc, char* argv[])
{
std::vector<int> vec = {0,1,2,3,4,5,6,7,8,9};
// accumulate:计算指定容器区域中,以0为初始值的和
int result = std::accumulate(vec.begin(), vec.end(), 0);
std::cout << result << std::endl; // 45
// equal:用对比两个容器在begin到end范围内是否相等,第二个容器超出的部分不考虑
// 结合容器size比较,可以判断两个容器是否完全相等
std::vector<int> vec2 = {0,1,2,3,4,5,6,7,8,9};
if (vec.size() == vec2.size() &&
std::equal(vec.begin(), vec.end(), vec2.begin()))
{
std::cout << "vec == vec2" << std::endl; // vec == vec2
}
// fill:将指定容器区域中所有元素填满成指定值
std::fill(vec2.begin(), vec2.end(), 0);
for (auto i : vec2)
{
std::cout << i; // 0000000000
}
std::cout << std::endl;
// fill_n:将容器指定位置开始的n个元素填满成指定值
std::fill_n(vec2.begin(), 5, 1);
for (auto i : vec2)
{
std::cout << i; // 1111100000
}
std::cout << std::endl;
// iter_swap: 交换两个迭代器的值
std::iter_swap(vec2.begin(), vec2.end() - 1);
for (auto i : vec2)
{
std::cout << i; // 0111100001
}
std::cout << std::endl;
// max、min:比较两个值的大小并返回结果,可以指定比较规则
result = *std::max(vec.begin(), vec.begin() + 1);
std::cout << result << std::endl; // 1
// count:返回指定容器区域中和指定值相等的元素个数
std::cout << std::count(vec.begin(), vec.end(), 1) << std::endl; // 1
// count_if:返回指定容器区域中,指定操作返回结果为true的元素个数
auto num = std::count_if(vec.begin(), vec.end(), [](int i)->bool{ return i >= 5; });
std::cout << num << std::endl; // 5
// find:找到指定容器区域中,第一个指定值的迭代器,没有找到返回end
auto pos = std::find(vec.begin(), vec.end(), 5);
if (pos != vec.end())
{
std::cout << *pos << std::endl; // 5
}
// find_if:找到指定容器区域中,第一个指定操作返回结果为true的迭代器,没有找到返回end
pos = std::find_if(vec.begin(), vec.end(), [](int i)->bool{ return i > 5; });
if (pos != vec.end())
{
std::cout << *pos << std::endl; // 6
}
// find_first_of: 找到指定容器区域中,第一个和指定容器区域中相匹配的连续元素段的迭代器,没有找到返回end
std::vector<int> vec3 = {1,2,3,4,5,1,6,7,8,1,9};
pos = std::find_first_of(vec3.begin(), vec3.end(), vec3.begin(), vec3.begin() + 2);
if (pos != vec.end())
{
std::cout << *(pos + 1) << std::endl; // 2
}
// find_end: 找到指定容器区域中,最后一个和指定容器区域中相匹配的连续元素段的迭代器,没有找到返回end
pos = std::find_end(vec3.begin(), vec3.end(), vec3.begin(), vec3.begin() + 1);
if (pos != vec.end())
{
std::cout << *(pos + 1) << std::endl; // 9
}
// for_each:遍历指定容器区域
std::for_each(vec.begin(), vec.end(), [](int i) { std::cout << i; }); // 0123456789
std::cout << std::endl;
// max_element、min_element:返回指定容器区域最大值/最小值的迭代器
std::cout << *max_element(vec.begin(), vec.end()) << std::endl; // 9
// reverse:将指定容器区域中的元素倒序排列
std::reverse(vec.begin(), vec.end());
for (auto i : vec) { std::cout << i; } // 9876543210
std::cout << std::endl;
return 0;
}
copy
SGI STL中的copy为了尽量提高效率,使用了各种办法。
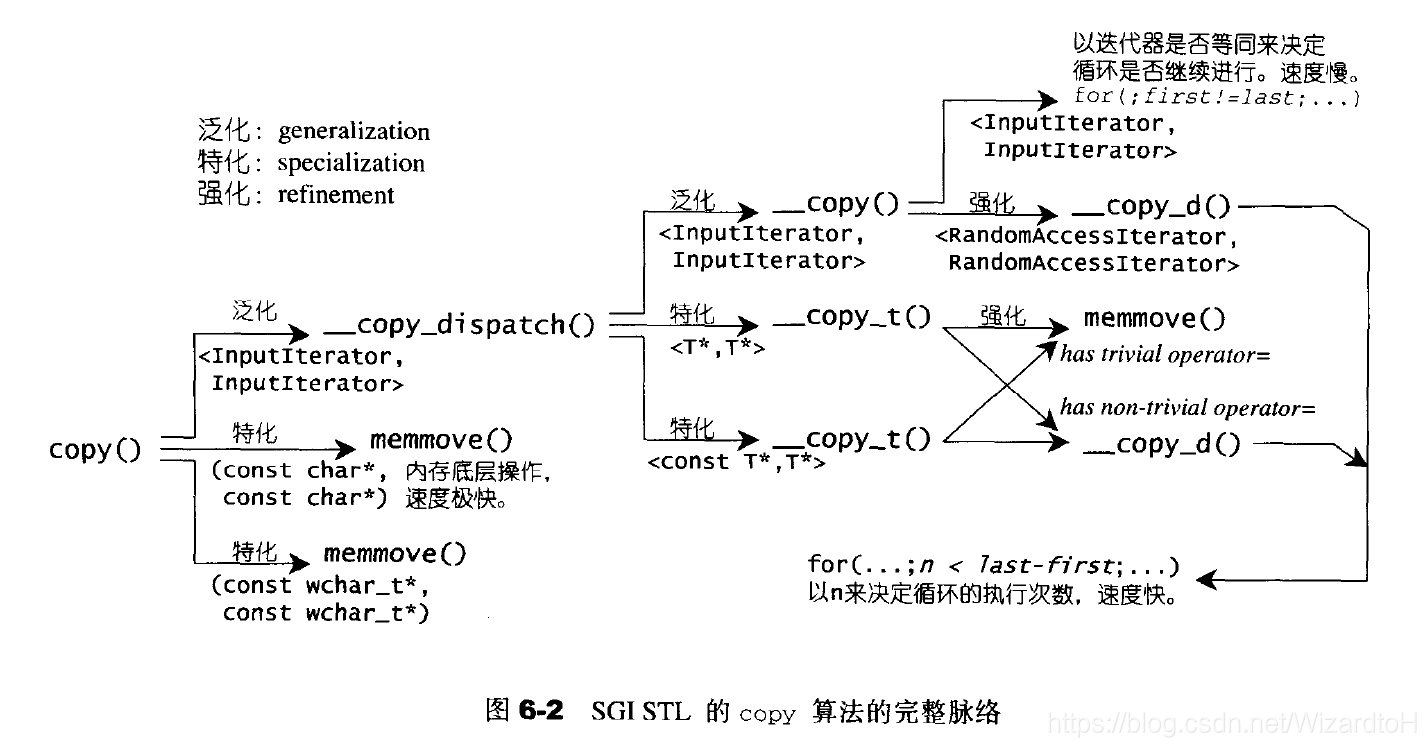
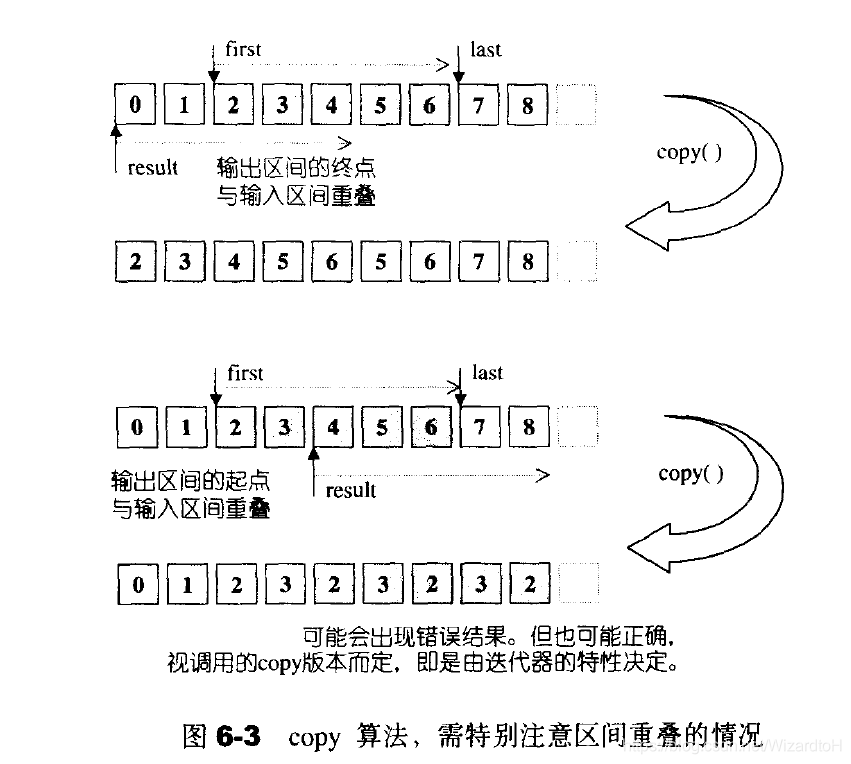
copy函数的赋值操作可能是向前推进的,不断累加直到最后,因为函数还可能因为效率问题调用memcpy或是memmove等底层函数。
copy有一个完全泛化版本和两个重载函数。
// 完全泛化版本
template<class InputIterator, class OutputIterator >
inline OutputIterator copy()(InputIterator first, InputIterator last,OutputIterator result)
{
return __copy_dispatch<InputIterator, OutputIterator >(first, last, result);
};
// 针对原生指针的版本
inline char *copy(const char *first, constchar *last, char *result)
{
memmove(result, first, last - first);
return result + (last - first);
}
inline wchar_t *copy(const wchar_t *first,const wchar_t *last, wchar_t *result)
{
memmove(result, first, sizeof(wchar_t)*( last - first));
return result + (last - first);
}
而__copy_dispatch又有一个完全泛化版本和两个偏特化版本。
// 完全泛化版本
template<class InputIterator, class OutputIterator >
struct __copy_dispatch
{
OutputIterator operator()(InputIterator first, InputIterator last,OutputIterator result )
{
return __copy (first, last, result,iterator_category(first));
}
};
// 完全泛化版本的底层实现--begin
// 对于InputIterator
template <class InputIterator, class OutputIterator>
inline OutputIterator __copy(InputIterator first, InputIterator last, OutputIteratorresult, input_iterator_tag)
{
// 判断迭代器是否遍历完成,速度较慢
for (; first != last; ++result, ++first)
*result = *first;
return result;
}
// 对于RandomAccessIterator
template <classRandomAccessIterator, class OutputIterator>
inline OutputIterator __copy (RandomAccessIteratorfirst, RandomAccessIterator last, OutputIterator result, random_access_iterator_tag)
{
return __copy_d(first, last, result, distance_type(first));
}
// 提炼出来便于其他地方使用功能
template <classRandomAccessIterator, class OutputIterator, class Distance>
inline OutputIterato __copy_d(RandomAccessIteratorfirst, RandomAccessIterator last, OutputIterator result, Distance*)
{
// 使用distance来判断是否完成遍历,速度快
for (Distance n = last - first; n > 0; --n, ++result, ++first)
*result = *first;
return result;
}
// 完全泛化版本的底层实现--end
// 偏特化版本1,两个参数都是T*指针形式
template<class T>
struct __copy_dispatch<T*, T*>
{
T* operator()(T* first, T* last, T* result)
{
typedef typename __type_traits<T>::has_trivial_assignment_operatort;
return __copy_t(first, last, result, t());
}
};
// 偏特化版本2,第一个参数为const T*指针形式,第二个参数为T*形式
template<class T>
struct __copy_dispatch<const T*, T*>
{
T* operator()(const T* first, const T*last, T*result, t())
{
typedef typename__type_traits<T>::has_trivial_assignment_operator t;
return _copy_t(first, last, result, t());
}
}
// 偏特化版本的底层实现--begin
template <class T>
inline T* __copy_t(const T* first, const T* last, T* result, __true_type) {
// 有平凡的赋值操作符,直接使用最快的memmove
memmove(result, first, sizeof(T) * (last -first));
return result + (last - first);
}
template <class T>
inline T* __copy_t(const T* first, const T* last, T* result, __false_type) {
// 没有平凡的赋值操作符
return __copy_d(first, last, result, (ptrdiff_t*) 0);
}
// 偏特化版本的底层实现--end
binary_search
binary_searcht提供了对有序容器区间的二分法查找,查找之前需要先排序,找到返回true否则返回false。
// 使用值比较的版本
template <class ForwardIterator, class T>
bool binary_search(ForwardIterator first, ForwardIterator last, const T& value) {
ForwardIterator i = lower_bound(first, last, value); // lower_bound的作用是找到小于等于value的第一个元素,没有的话返回last
return i != last && !(value < *i);
}
// 使用方法比较的版本
template <class ForwardIterator, class T, class Compare>
bool binary_search(ForwardIterator first, ForwardIterator last, const T& value, Compare comp) {
ForwardIterator i = lower_bound(first, last, value, comp);
return i != last && !comp(value, *i);
}
sort
sort算法支持对两个RandomAccessIterators区间内的元素进行排序,由于所有关系型容器都有自动排序的功能所以不需要sort算法;而stack、queue都有特定的出入口,list则不是RandomAccessIterators,所以也不能使用sort算法,最后满足的容器只有vector和deque。
sort算法不是简单采用一种排序算法,数据量大时采用快速排序、分段递归排序,数据量比较小时采用插入排序,递归层次较深就采用堆排序。
// 版本一,默认递增排序
template <class RandomAccessIterator>
inline void sort(RandomAccessIterator first, RandomAccessIterator last) {
if (first != last) {
__introsort_loop(first, last, value_type(first), __lg(last - first) * 2);
// 经过__introsort_loop后,会有多个元素个数少于16的区间,再用插入排序
// 这些区间内部没有完全排序,但是互相之间已经经过快速排序保证了互相整体的排序正确
__final_insertion_sort(first, last);
}
}
// 版本二,使用对比方法进行对比,后续只对版本一进行说明
template <class RandomAccessIterator, class Compare>
inline void sort(RandomAccessIterator first, RandomAccessIterator last, Compare comp) {
if (first != last) {
__introsort_loop(first, last, value_type(first), __lg(last - first) * 2, comp);
__final_insertion_sort(first, last, comp);
}
}
// 计算分割层次,n >>= 1作用和n = n/2一样
template <class Size>
inline Size __lg(Size n) {
Size k;
for (k = 0; n > 1; n >>= 1) ++k;
return k;
}
template <class RandomAccessIterator, class T, class Size>
void __introsort_loop(RandomAccessIterator first, RandomAccessIterator last, T*, Size depth_limit) {
while (last - first > __stl_threshold) { // __stl_threshold为16
// 分割层次超过__lg计算出的层次,则改用堆排序,保证效率不会变成最坏情况
// 堆排序最坏情况为O(nlogn),快速排序最坏情况为O(n^2)
if (depth_limit == 0) {
partial_sort(first, last, last); // 堆排序
return;
}
--depth_limit;
// 通过median-of-3,选择头、尾和中间位置元素中的中位数作为快速排序的枢轴,进行快速排序分割
// 这样能够尽量较少最坏情况的出现
RandomAccessIterator cut = __unguarded_partition(first, last, T(__median(*first, *(first + (last - first)/2), *(last - 1))));
__introsort_loop(cut, last, value_type(first), depth_limit); // 对右半段进行递归
last = cut; // 对左半段进行循环调用
}
}
// 快速排序
template <class RandomAccessIterator, class T>
RandomAccessIterator __unguarded_partition(RandomAccessIterator first, RandomAccessIterator last, T pivot) {
while (true) {
while (*first < pivot) ++first; // 从头开始找到第一个大于等于枢轴的元素
--last;
while (pivot < *last) --last; // 从尾开始找到第一个小于等于枢轴的元素
if (!(first < last)) return first; // 如果first在last右侧(说明所有小的值都在枢轴左边,大的值都在枢轴右边),此次排序结束,返回first
iter_swap(first, last); // 否则交换first、last(把小的值换到左边,打的值换到右边),继续排序
++first;
}
}
template <class RandomAccessIterator>
void __final_insertion_sort(RandomAccessIterator first, RandomAccessIterator last) {
if (last - first > __stl_threshold) {
// 元素数量大于16,用插入排序处理前16个元素
__insertion_sort(first, first + __stl_threshold);
// 插入排序处理剩下的元素,因为__insertion_sort中会涉及整体移动,所以元素太多会影响效率
__unguarded_insertion_sort(first + __stl_threshold, last);
}
else
// 元素数量小于16
__insertion_sort(first, last);
}
template <class RandomAccessIterator>
void __insertion_sort(RandomAccessIterator first, RandomAccessIterator last) {
if (first == last) return;
// 从第二个元素开始,对每一个元素进行处理
for (RandomAccessIterator i = first + 1; i != last; ++i)
__linear_insert(first, i, value_type(first));
}
template <class RandomAccessIterator, class T, class Compare>
inline void __linear_insert(RandomAccessIterator first, RandomAccessIterator last, T*) {
T value = *last; // 从尾部开始处理
if (comp(value, *first)) { // 头比尾部小,直接将整个区间向右移动,并把尾部元素的值赋值给first
copy_backward(first, last, last + 1);
*first = value;
}
else
__unguarded_linear_insert(last, value); // 否则,进行随机插入排序
}
template <class RandomAccessIterator>
inline void __unguarded_insertion_sort(RandomAccessIterator first, RandomAccessIterator last) {
__unguarded_insertion_sort_aux(first, last, value_type(first));
}
template <class RandomAccessIterator, class T, class Compare>
void __unguarded_insertion_sort_aux(RandomAccessIterator first, RandomAccessIterator last) {
// 对每一个元素进行处理
for (RandomAccessIterator i = first; i != last; ++i)
__unguarded_linear_insert(i, T(*i));
}
// sort排序调用最多的函数
template <class RandomAccessIterator, class T>
void __unguarded_linear_insert(RandomAccessIterator last, T value) {
RandomAccessIterator next = last;
--next;
// 从指定位置开始对比元素的值,如果比value大就交换位置,直到value不小于该值
while (value < *next) {
*last = *next;
last = next;
--next;
}
*last = value;
}
partial_sort
在sort算法中用到了partial_sort算法,该算法接收3个参数,是序列中middle-first个最小元素按照递增顺序排序,其余元素不保证有顺序,主要使用堆算法实现(https://blog.csdn.net/WizardtoH/article/details/82747371)。
template <class RandomAccessIterator>
inline void partial_sort(RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last) {
__partial_sort(first, middle, last, value_type(first));
}
template <class RandomAccessIterator, class T>
void __partial_sort(RandomAccessIterator first, RandomAccessIterator middle,
RandomAccessIterator last, T*) {
make_heap(first, middle); // 先将[first,middle)区间汇总的元素构造成max-heap
// 将[middle,last)区间中的元素和heap中的最大值比较(第一个元素)
// 如果小于最大值,就互换位置,并调整heap的结构
// [middle,last)中所有元素都对比后,[first,middle)将是最小的一系列元素(递减排序)
for (RandomAccessIterator i = middle; i < last; ++i)
if (*i < *first)
__pop_heap(first, middle, i, T(*i), distance_type(first));
// sort_heap递增排序
sort_heap(first, middle);
}
nth_element
nth_element算法的作用是重新排序,使得[nth,last)内没有任何一个元素小于[first,nth)内的元素,
但对于[first,nth)和[nth,last)两个子区间内的元素次序则无任何保证。
template <class RandomAccessIterator, class Compare>
inline void nth_element(RandomAccessIterator first, RandomAccessIterator nth, RandomAccessIterator last) {
__nth_element(first, nth, last, value_type(first));
}
template <class RandomAccessIterator, class T>
void __nth_element(RandomAccessIterator first, RandomAccessIterator nth, RandomAccessIterator last, T*) {
while (last - first > 3) { // 长度大于三
// 进行快速排序分割,让nth左右两端的元素到对的位置
RandomAccessIterator cut = __unguarded_partition(first, last, T(__median(*first, *(first + (last - first) / 2), *(last - 1))));
if (cut <= nth) // 右段起点小于nth,继续对右段进行快速排序分割
first = cut;
else // 右段起点大于nth,继续对左段进行快速排序分割
last = cut;
}
// 当nth所在区段元素小于等于3时(不需要再分割了),使用插入排序排序后,就符合条件了
__insertion_sort(first, last);
}
set算法
set相关算法共有4个,只支持set/multiset。
- set_union:求并集,并集中值相同的元素可以多个,个数以两个集合中数量较大的一个为准。
- set_intersection:求交集,交集中值相同的元素也可以多个,个数以两个集合中数量较小的一个为准。
- set_difference:求差集,差集中值相同的元素也可以多个,个数为前一个集合减去后一个集合中的数量,最小为0。
- set_summetric_difference:求对称差集,就是相互的差集的并集。