1、python各种函数包的由来
首先python是一门开源的,有广泛社群支持的语言。比如我想求一个线性回归,要算矩阵求逆或者矩阵相乘,但这个矩阵的求逆,或者矩阵的相乘,肯定不是我一个人碰到,那既然大家都需要用python来解决这个问题,那我就看看大家有没有好的方法,那在网上一搜,发现别的在做某些分析的时候也用到了矩阵求逆,那我就把它的方式借鉴过来,或者直接把他的代码粘过来就可以用。随着这样的共享越来越多,也就构成了我们开源的一个社群,当在做非常高层的分析的时候,发现这个世界不止我一个人在做,前面已经有很多人需要这样的算法。会有前人已经用过了,那么他们在用的时候就会发现,哎呀,这个方法如果不把他写成代码很麻烦,写完了之后呢觉得这个未来可能还有人用,于是呢,他就总结成了一套函数库,放到了网上。
2、python的数据科学函数包
numpy,对数值以及高维数组进行计算管理的一个非常好用的一个函数包,里面包含了一系列非常常用的数据处理方面的函数,可谓是python里面做数据科学的重中之重,核心之核心
pandas,可以理解为python里面的excel表格,他可以对数据进行管理以及一些统计计算,pandas的开发其实依托于numpy (python data analisis library)
matplotlib,绘图(让结果可视化 )seaborn,依托于matplotlib的python可视化库,可以让数据可视化更加的方便、美观,让图画得更好看
要注意的是一旦导入了seaborn,matplotlib的默认作图风格就会被覆盖成seaborn的格式,seaborn相比于matplotlib拥有更好的默认风格3、将可选的函数列表弄出来——tab键
4、看函数具体的参数信息——鼠标光标移进去,shift+tab
---------------------------------------------numpy---------------------------------------------------------
5、np.zeros(n) / np.zeors(n,n) np.ones(n) / np.ones(n,n)
np.linspace(0,10,3) 线型空间切割
以0为初始,以为10截止,把这个线段平均分成3个点(2个部分)
np.eye(n) 生成n维单位矩阵
np.random.rand() / np.random.rand(n,n) 生成一个0-1的随机数(小数)/ 生成一个n行n列的
np.random.randint(n,m) 生成一个n-m的随机整数
np.random.seed(50)
np.random.randint(1,100,10) 如果大家的random.seed都是50的话,那么在不同电脑执行这条语句的结果都是一样的
array.max() / min() 求数列最大值
array.argmax() / argmin() 求数列最大值所在的位置
array.reshape(n,m) 把原来的数组变成n行m列的矩阵(注意原来数组的元素必须=n*m)
np.sqrt(arr) / np.exp(arr) 对数组(的每个数)求开方/求幂
6、np.random.rand()和np.random.randn()
- rand函数根据给定维度生成[0,1)之间的数据,包含0,不包含1
- randn函数返回一个或一组样本,具有标准正态分布。
randn生成的值会有大于1的,还有负的
7、python数组的复制,也是指针的复制,修改新数组的值,就数组的值也会跟着变
用arr2=arr.copy()
8、多维矩阵切割
直接用坐标选出即可
9、取出数组中大于某个值的数 arr[arr > n]
而如果直接 arr>n ,会返回一个布尔类型的数组
10、为什么np.zeros((5,5)) 这是一个圆括号 ,是一个tuple,而np.random怎么就不加圆括号了呢
这就体现了numpy作为一个开源函数库,他的好与不好,没有一个统一的规范性的标准
就可能numpy.ones是一个人开发的,他觉得我如果生成维度的话我可能输入一个tuple,对这个纬度的管控就会更好
而开发random的人呢,可能会觉得生成一个tuple是没有必要的,就造成了现在的这种现象
----------------------------------------pandas------------------------------------------
11、pandas数据的存储相对来说比较简单,它就只有两种非常重要的数据类型,一种叫series,一种叫dataframe
series是指那些一维的数据,dataframe是指那些二维的数据。也就是说任何一个datafarame其实是好多个series罗列出来的12、pd.Series(data,index)
13、pd.DataFrame(data,index,columns)
14、做数据科学的时候,往往把feature放在列上,每一列叫做一个feature
每一行叫做一个observation像不同的列记录所有人的身高、所有人的体重,所有人的收入,而每一行是一个不同的人
并且如果直接引用的话,会默认选择列
若要选择行 df.loc('A')
15、添加列
删除列 df.drop('new',axis) //0是指行的维度,1是指列的维度
但是这样删除只是返回一个临时的结果,实际df中并没有删除列,这是相当于一个double check的机制。可以不在原数据进行操作,df2=df.drop('new',axis)
如果的确要删的话 df.drop('new',axis=1,inplace= True)
16、选择满足相关条件的数据
选择W列的值大于0的数据
选择W列的值大于0的数据的Y的数据
选择W列的值大于0并且Y列的值大于1的数据
17、将另一列的数据当做行名
df.set_index('state')
同样,如果确定要修改,还需要 df.set_index('state',inplace=True)
18、将数据转化成DataFrame
19、分组计算
平均值
最大值
标准差 //standard deviation
能计算的都给你计算一遍
------------------------------------ Matplotlib---------------------------------------------
20、让matplotlib画的图显示出来
21、绘图
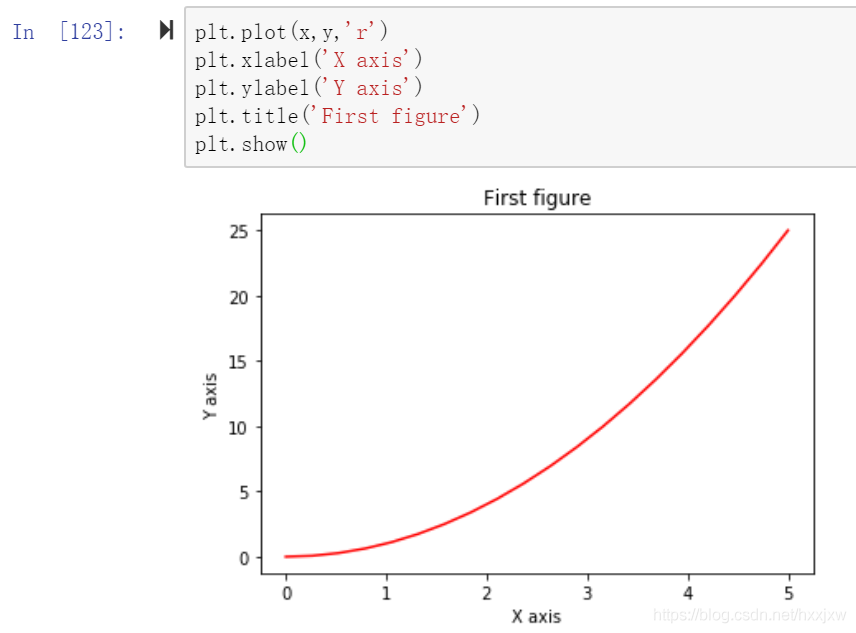
改变颜色 plt.plot(x,y,'r')
横轴名称 plt.xlabel('X axis')
纵轴名称 plt.ylabel('Y axis')
图像标题 plt.title('First figure')
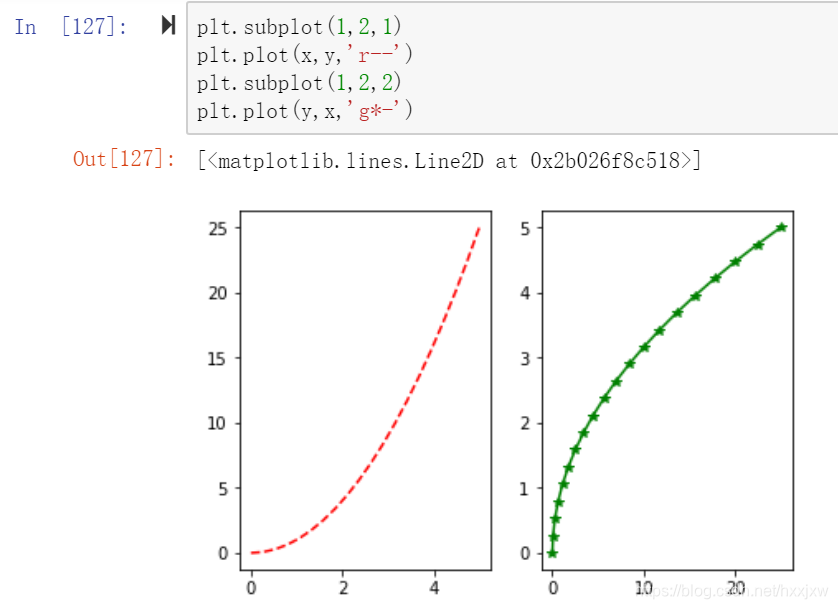
画子图 sublplot
一个画布上画多个图
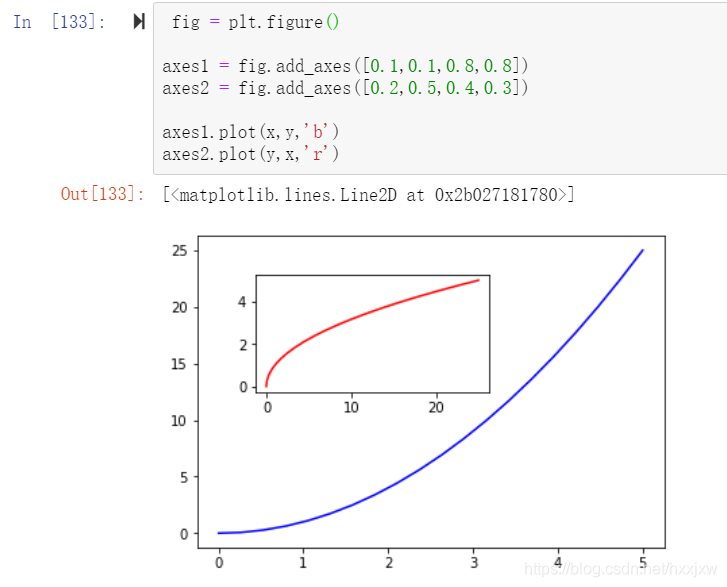
fig = plt.figure() 是在告诉你我准备画画了,现在已经有一块木头的画板已经立起来了
axes1 = fig.add_axes([0.1,0.1,0.8,0.8]) 是说我在木头的画板上已经贴了一张纸了,这张纸距离左边框10%的单位,距离右边框,10%的单位,总长度80%的单位,总宽度80%的单位
axes2 = fig.add_axes([0.2,0.5,0.4,0.3]) 然后再贴第2张纸然后说每张纸上画什么
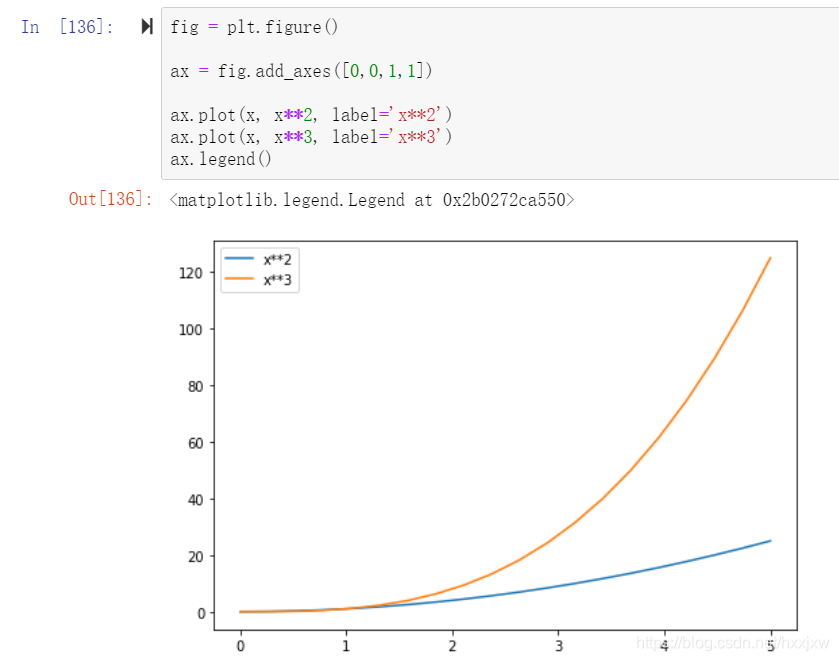
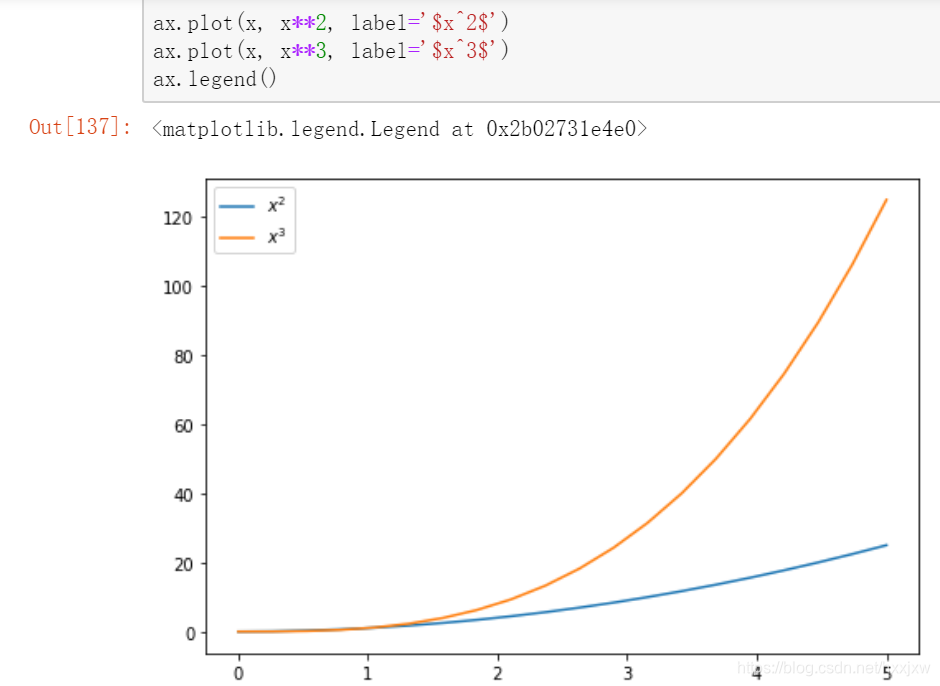
一张图上画多条线 + 图例
LaTex数学排版语言,python里面也能用
22、终极小笔记
所有线型,以及绘线可调控可操作的参数
fig, ax = plt.subplots(figsize=(12,6))
ax.plot(x, x+1, color="red", linewidth=0.25)
ax.plot(x, x+2, color="red", linewidth=0.50)
ax.plot(x, x+3, color="red", linewidth=1.00)
ax.plot(x, x+4, color="red", linewidth=2.00)# possible linestype options ‘-‘, ‘–’, ‘-.’, ‘:’, ‘steps’
ax.plot(x, x+5, color="green", lw=3, linestyle='-')
ax.plot(x, x+6, color="green", lw=3, ls='-.')
ax.plot(x, x+7, color="green", lw=3, ls=':')# custom dash
line, = ax.plot(x, x+8, color="black", lw=1.50)
line.set_dashes([5, 10, 15, 10]) # format: line length, space length, ...# possible marker symbols: marker = '+', 'o', '*', 's', ',', '.', '1', '2', '3', '4', ...
ax.plot(x, x+ 9, color="blue", lw=3, ls='-', marker='+')
ax.plot(x, x+10, color="blue", lw=3, ls='--', marker='o')
ax.plot(x, x+11, color="blue", lw=3, ls='-', marker='s')
ax.plot(x, x+12, color="blue", lw=3, ls='--', marker='1')# marker size and color
ax.plot(x, x+13, color="purple", lw=1, ls='-', marker='o', markersize=2)
ax.plot(x, x+14, color="purple", lw=1, ls='-', marker='o', markersize=4)
ax.plot(x, x+15, color="purple", lw=1, ls='-', marker='o', markersize=8, markerfacecolor="red")
ax.plot(x, x+16, color="purple", lw=1, ls='-', marker='s', markersize=8,
markerfacecolor="yellow", markeredgewidth=3, markeredgecolor="green");
23、读入csv文件
USAhousing = pd.read_csv("USA_Housing.csv")
数据科学与大数据分析workshop 笔记
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/hxxjxw/article/details/89075645
















猜你喜欢
转载自blog.csdn.net/hxxjxw/article/details/89075645
今日推荐
周排行