python写入html文件中文乱码问题
使用open函数将爬虫爬取的html写入文件,有时候在控制台不会乱码,但是写入文件的html中的中文是乱码的
案例分析
看下面一段代码:
# 爬虫未使用cookiefrom urllib import requestif __name__ == '__main__': url = "http://www.renren.com/967487029/profile" rsp = request.urlopen(url) html = rsp.read().decode() with open("rsp.html","w")as f: # 将爬取的页面 print(html) f.write(html)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
看似没有问题,并且在控制台输出的html也不会出现中文乱码,但是创建的html文件中
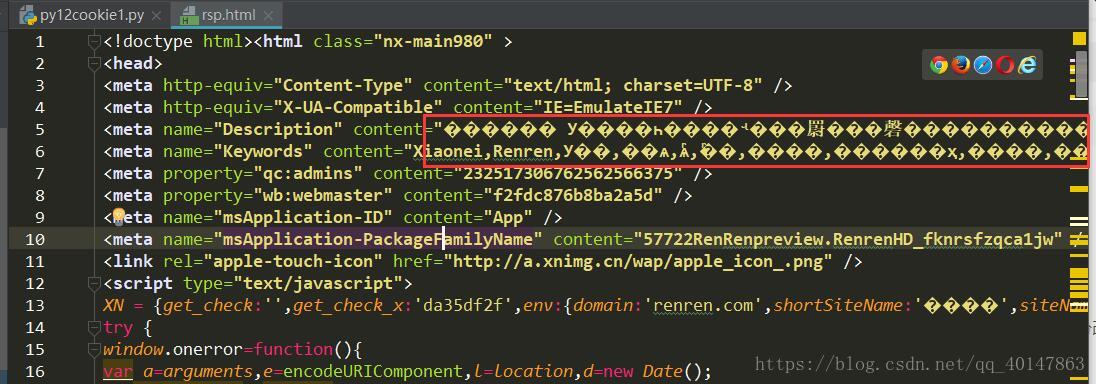
解决方案
使用open方法的一个参数,名为encoding=” “,加入encoding=”utf-8”即可
# 爬虫未使用cookiefrom urllib import requestif __name__ == '__main__': url = "http://www.renren.com/967487029/profile" rsp = request.urlopen(url) html = rsp.read().decode() with open("rsp.html","w",encoding="utf-8")as f: # 将爬取的页面 print(html) f.write(html)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
运行结果
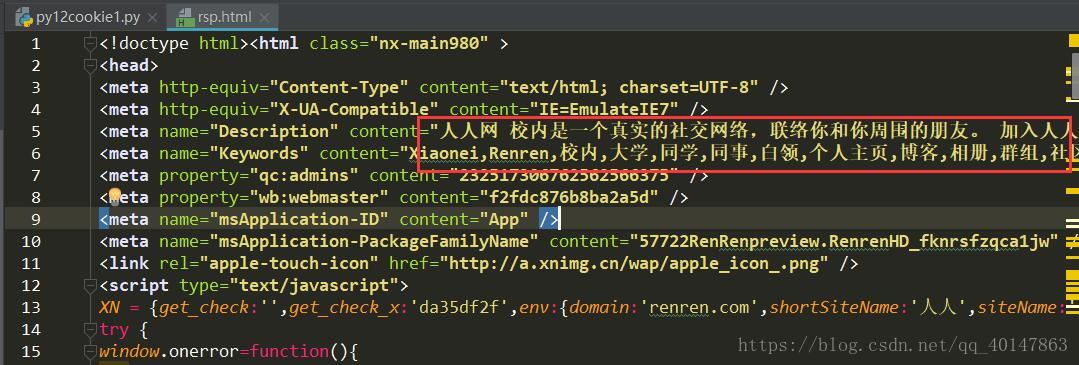
之前写过一篇 关于爬虫编程的常见错误:
https://blog.csdn.net/qq_40147863/article/details/81673694
但是编码问题很让人头疼,所以写了一篇独立的,且后续也可能会在本篇继续更多的编码问题
- 本笔记不允许任何个人和组织转载