For
x
=
(
x
1
,
x
2
,
⋅
⋅
⋅
,
x
d
)
x = (x_1 ,x_2 ,··· ,x_d )
x = ( x 1 , x 2 , ⋅ ⋅ ⋅ , x d )
∑
i
=
1
d
w
i
x
i
>
t
h
r
e
s
h
o
l
d
\sum_{i=1}^{d}w_ix_i>threshold
∑ i = 1 d w i x i > t h r e s h o l d
Y
:
{
+
1
,
−
1
}
Y:\{+1, -1\}
Y : { + 1 , − 1 }
h
(
x
)
=
s
i
g
n
(
(
∑
i
=
1
d
w
i
x
i
)
−
t
h
r
e
s
h
o
l
d
)
=
w
0
=
−
t
h
r
e
s
h
o
l
d
,
x
0
=
+
1
s
i
g
n
(
(
∑
i
=
1
d
w
i
x
i
)
+
w
0
∗
x
0
)
=
s
i
g
n
(
(
∑
i
=
0
d
w
i
x
i
)
)
=
s
i
g
n
(
w
T
x
)
h(x)=sign((\sum_{i=1}^{d}w_ix_i)-threshold) \stackrel{w_0 = -threshold, x_0 = +1}{\xlongequal{\quad\quad\quad\quad\quad\quad\quad}} sign((\sum_{i=1}^{d}w_ix_i)+w_0*x_0) \\ = sign((\sum_{i=0}^{d}w_ix_i)) = sign(w^Tx)
h ( x ) = s i g n ( ( i = 1 ∑ d w i x i ) − t h r e s h o l d )
w 0 = − t h r e s h o l d , x 0 = + 1 s i g n ( ( i = 1 ∑ d w i x i ) + w 0 ∗ x 0 ) = s i g n ( ( i = 0 ∑ d w i x i ) ) = s i g n ( w T x ) perceptron ’ hypothesis historically
R
2
R^2
R 2
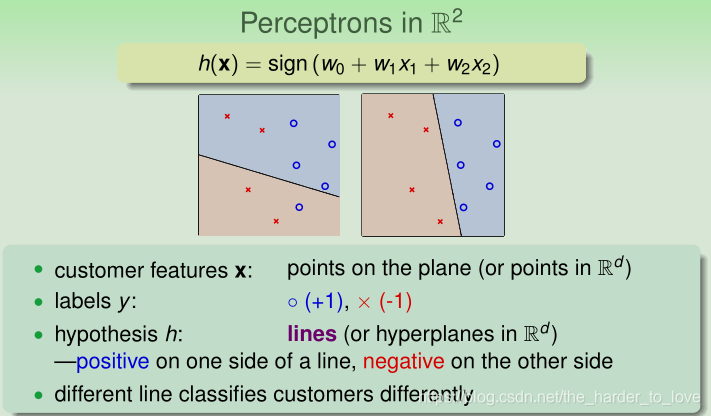
perceptrons(感知器) ⇔ linear (binary) classifiers
Consider using a perceptron to detect spam messages. free, drug, fantastic, deal
✓
\checkmark
✓
Explanation
PLA算法就是要在Perceptrons(Perceptron Hypothesis Set)找到合适的Perceptron,而Perceptron由
w
w
w
w
w
w
Cyclic PLA算法如下所示
w
w
w
w
0
w_0
w 0
w
w
w
w
t
w_t
w t
x
n
(
t
)
x_{n(t)}
x n ( t )
y
n
(
t
)
y_{n(t)}
y n ( t )
s
i
g
n
(
w
t
T
x
n
(
t
)
)
≠
y
n
(
t
)
sign(w_t^Tx_{n(t)}) \ne y_{n(t)}
s i g n ( w t T x n ( t ) ) ̸ = y n ( t )
correct the mistake by
w
(
t
+
1
)
←
w
t
+
y
n
(
t
)
x
n
(
t
)
w_{(t+1)} ← w_t + y_{n(t)}x_{n(t)}
w ( t + 1 ) ← w t + y n ( t ) x n ( t )
… until no more mistakes last w (called
w
P
L
A
w_{PLA}
w P L A
PLA算法的精髓在于找到与感知器分类不正确的点,然后通过不正确的点修正感知器,直到所有的样本点分类正确。
w
(
t
+
1
)
←
w
t
+
y
n
(
t
)
x
n
(
t
)
w_{(t+1)} ← w_t + y_{n(t)}x_{n(t)}
w ( t + 1 ) ← w t + y n ( t ) x n ( t )
Let’s try to think about why PLA may work. Let n = n(t), according to the rule of PLA below, which formula is true?
s
i
g
n
(
w
t
T
x
n
)
≠
y
n
,
w
(
t
+
1
)
←
w
t
+
y
n
x
n
sign(w_t^Tx_{n}) \ne y_{n},\quad w_{(t+1)} ← w_t + y_{n}x_{n}
s i g n ( w t T x n ) ̸ = y n , w ( t + 1 ) ← w t + y n x n
w
t
+
1
T
x
n
=
y
n
w_{t+1}^Tx_{n} = y_{n}
w t + 1 T x n = y n
s
i
g
n
(
w
t
+
1
T
x
n
)
=
y
n
sign(w_{t+1}^Tx_{n}) = y_{n}
s i g n ( w t + 1 T x n ) = y n
y
n
w
t
+
1
T
x
n
≥
y
n
w
t
T
x
n
y_{n}w_{t+1}^Tx_{n} \geq y_{n}w_{t}^Tx_{n}
y n w t + 1 T x n ≥ y n w t T x n
✓
\checkmark
✓
y
n
w
t
+
1
T
x
n
<
y
n
w
t
T
x
n
y_{n}w_{t+1}^Tx_{n} < y_{n}w_{t}^Tx_{n}
y n w t + 1 T x n < y n w t T x n
Explanation
x
n
x_{n}
x n
y
n
y_{n}
y n
w
t
w_t
w t
w
t
+
1
w_{t+1}
w t + 1
Δ
w
=
y
n
x
n
\Delta w = y_{n}x_{n}
Δ w = y n x n
x
n
x_{n}
x n
y
n
y_{n}
y n
y
n
w
t
+
1
T
x
n
−
y
n
w
t
T
x
n
=
(
w
t
+
1
T
−
w
t
T
)
y
n
x
n
=
x
n
T
y
n
T
y
n
x
n
=
y
n
T
y
n
=
+
1
x
n
T
x
n
≥
0
y_{n}w_{t+1}^Tx_{n} - y_{n}w_{t}^Tx_{n} = (w_{t+1}^T-w_{t}^T)y_{n}x_{n} = x_{n}^Ty_{n}^Ty_{n}x_{n} \stackrel{y_{n}^Ty_{n}= +1}{\xlongequal{\quad\quad\quad}} x_{n}^Tx_{n} \ge 0
y n w t + 1 T x n − y n w t T x n = ( w t + 1 T − w t T ) y n x n = x n T y n T y n x n
y n T y n = + 1 x n T x n ≥ 0
if PLA halts (i.e. no more mistakes), (necessary condition) D allows some w to make no mistake call such D linear separable.
linear separable
D
D
D perfect
w
f
\mathbf{w_f}
w f
s
i
g
n
(
w
f
T
x
n
)
=
y
n
sign(w_f^Tx_{n}) = y_{n}
s i g n ( w f T x n ) = y n
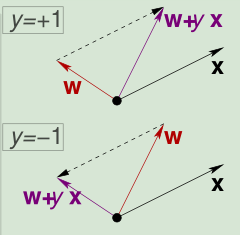
Fun Time中我们推导出感知器每次修正,
y
n
w
t
+
1
T
x
n
≥
y
n
w
t
T
x
n
y_{n}w_{t+1}^Tx_{n} \ge y_{n}w_{t}^Tx_{n}
y n w t + 1 T x n ≥ y n w t T x n
w
t
w_t
w t
w
f
w_f
w f
Δ
w
f
T
w
t
+
1
\Delta w_f^Tw_{t+1}
Δ w f T w t + 1
∵
w
f
i
s
p
e
r
f
e
c
t
f
o
r
x
n
∴
y
n
(
t
)
w
t
T
x
n
(
t
)
≥
m
i
n
n
 
y
n
(
t
)
w
t
T
x
n
(
t
)
>
0
w
t
T
w
n
(
t
)
↑
b
y
u
p
d
a
t
i
n
g
w
i
t
h
a
n
y
(
x
n
(
t
)
,
y
n
(
t
)
)
w
f
T
w
t
+
1
=
w
f
T
(
w
t
+
y
n
(
t
)
x
n
(
t
)
)
≥
w
f
T
w
t
+
min
n
y
n
w
f
T
x
n
>
w
f
T
w
t
+
0
\because w_f \ is \ perfect \ for \ x_n \\ \therefore y_{n(t)}w_t^Tx_{n(t)} \ge \mathop{min}\limits_n \, y_{n(t)}w_t^Tx_{n(t)} > 0 \\ \mathbf{w_t^Tw_{n(t)} \uparrow} \ by \ updating \ with \ any \ (x_{n(t)}, y_{n(t)}) \\ \begin{aligned} \mathbf{w}_{f}^{T} \mathbf{w}_{t+1} &= \mathbf{w}_{f}^{T}\left(\mathbf{w}_{t}+y_{n(t)} \mathbf{x}_{n(t)}\right) \\ & \geq \mathbf{w}_{f}^{T} \mathbf{w}_{t}+\min _{n} y_{n} \mathbf{w}_{f}^{T} \mathbf{x}_{n} \\ &>\mathbf{w}_{f}^{T} \mathbf{w}_{t}+0 \end{aligned}
∵ w f i s p e r f e c t f o r x n ∴ y n ( t ) w t T x n ( t ) ≥ n m i n y n ( t ) w t T x n ( t ) > 0 w t T w n ( t ) ↑ b y u p d a t i n g w i t h a n y ( x n ( t ) , y n ( t ) ) w f T w t + 1 = w f T ( w t + y n ( t ) x n ( t ) ) ≥ w f T w t + n min y n w f T x n > w f T w t + 0
感知器每次修正,
w
f
T
w
t
+
1
>
w
f
T
w
t
\mathbf{w}_{f}^{T} \mathbf{w}_{t+1} > \mathbf{w}_{f}^{T} \mathbf{w}_{t}
w f T w t + 1 > w f T w t
w
t
w_t
w t
w
f
w_f
w f
但是我们希望的逼近是夹角的逼近,而不是数值的增大。计算
Δ
∣
∣
w
t
∣
∣
2
\Delta||w_t||^2
Δ ∣ ∣ w t ∣ ∣ 2
∥
w
t
+
1
∥
2
=
∥
w
t
+
y
n
(
t
)
x
n
(
t
)
∥
2
=
∥
w
t
∥
2
+
2
y
n
(
t
)
w
t
T
x
n
(
t
)
+
∥
y
n
(
t
)
x
n
(
t
)
∥
2
又
sign
(
w
t
T
x
n
(
t
)
)
≠
y
n
(
t
)
⇔
y
n
(
t
)
w
t
T
x
n
(
t
)
≤
0
≤
∥
w
t
∥
2
+
0
+
∥
y
n
(
t
)
x
n
(
t
)
∥
2
≤
∥
w
t
∥
2
+
max
n
∥
y
n
x
n
∥
2
≤
∥
w
t
∥
2
+
max
n
∥
x
n
∥
2
\begin{aligned} \left\|\mathbf{w}_{t+1}\right\|^{2} &=\left\|\mathbf{w}_{t}+y_{n(t)} \mathbf{x}_{n(t)} \right\|^{2} \\ &=\left\|\mathbf{w}_{t}\right\|^{2}+2 y_{n(t)} \mathbf{w}_{t}^{T} \mathbf{x}_{n(t)}+\left\|y_{n(t)} \mathbf{x}_{n(t)}\right\|^{2} \\ 又 \ \operatorname{sign} & \left(\mathbf{w}_{t}^{T} \mathbf{x}_{n(t)}\right) \neq y_{n(t)} \Leftrightarrow y_{n(t)} \mathbf{w}_{t}^{T} \mathbf{x}_{n(t)} \leq 0 \\ & \leq\left\|\mathbf{w}_{t}\right\|^{2}+0+\left\|y_{n(t)} \mathbf{x}_{n(t)}\right\|^{2} \\ & \leq\left\|\mathbf{w}_{t}\right\|^{2}+\max _{n}\left\|y_{n} \mathbf{x}_{n}\right\|^{2} \\ & \leq\left\|\mathbf{w}_{t}\right\|^{2}+\max _{n}\left\| \mathbf{x}_{n}\right\|^{2} \end{aligned}
∥ w t + 1 ∥ 2 又 s i g n = ∥ ∥ w t + y n ( t ) x n ( t ) ∥ ∥ 2 = ∥ w t ∥ 2 + 2 y n ( t ) w t T x n ( t ) + ∥ ∥ y n ( t ) x n ( t ) ∥ ∥ 2 ( w t T x n ( t ) ) ̸ = y n ( t ) ⇔ y n ( t ) w t T x n ( t ) ≤ 0 ≤ ∥ w t ∥ 2 + 0 + ∥ ∥ y n ( t ) x n ( t ) ∥ ∥ 2 ≤ ∥ w t ∥ 2 + n max ∥ y n x n ∥ 2 ≤ ∥ w t ∥ 2 + n max ∥ x n ∥ 2
m
a
x
n
∥
x
n
∥
2
\mathop{max} \limits_{n}\left\|\mathbf{x}_{n}\right\|^{2}
n m a x ∥ x n ∥ 2
实际上
w
0
=
0
w_0=0
w 0 = 0
cos
θ
=
w
f
T
∥
w
f
∥
w
T
∥
w
T
∥
≥
T
⋅
c
o
n
s
t
a
n
t
\cos\theta=\frac{\mathbf{w}_{f}^{T}}{\left\|\mathbf{w}_{f}\right\|} \frac{\mathbf{w}_{T}}{\left\|\mathbf{w}_{T}\right\|} \geq \sqrt{T} \cdot constant
cos θ = ∥ w f ∥ w f T ∥ w T ∥ w T ≥ T
⋅ c o n s t a n t 证明:
R
2
=
max
n
∥
x
n
∥
2
ρ
=
min
n
y
n
w
f
T
x
n
∥
w
f
∥
∵
w
0
=
0
w
f
T
w
T
≥
T
min
n
y
n
w
f
T
x
n
∥
w
T
∥
2
≤
T
max
n
∥
x
n
∥
2
c
o
s
θ
=
w
f
T
∥
w
f
∥
w
T
∥
w
T
∥
=
1
∥
w
f
∥
w
f
T
w
T
∥
w
T
∥
=
1
∥
w
f
∥
T
min
n
y
n
w
f
T
x
n
T
max
n
∥
x
n
∥
2
≥
T
ρ
R
∴
cos
θ
=
w
f
T
∥
w
f
∥
w
T
∥
w
T
∥
≥
T
⋅
c
o
n
s
t
a
n
t
,
 
其
中
 
c
o
n
s
t
a
n
t
=
ρ
R
R^2 = \max _{n} \|\mathbf{x}_{n}\|^{2} \quad \rho = \frac{\min \limits _{n} y_{n} \mathbf{w}_{f}^{T} x_n}{\mathbf{\| w_f \|}} \\ \\ \because \mathbf{w_0 = 0} \quad \mathbf{w}_{f}^{T}\mathbf{w}_{T} \geq T\min \limits _{n} y_{n} \mathbf{w}_{f}^{T} \mathbf{x}_{n} \quad \left\|\mathbf{w}_{T}\right\|^{2} \leq T\max \limits _{n}\left\| \mathbf{x}_{n}\right\|^{2} \\ cos\theta=\frac{\mathbf{w}_{f}^{T}}{\left\|\mathbf{w}_{f}\right\|} \frac{\mathbf{w}_{T}}{\left\|\mathbf{w}_{T}\right\|} = \frac{1}{\left\|\mathbf{w}_{f}\right\|} \frac{\mathbf{w}_{f}^{T} \mathbf{w}_{T}}{\left\|\mathbf{w}_{T}\right\|} = \frac{1}{\left\|\mathbf{w}_{f}\right\|} \frac{T\min \limits _{n} y_{n} \mathbf{w}_{f}^{T} \mathbf{x}_{n}}{\sqrt{T}\sqrt{\max \limits _{n}\left\| \mathbf{x}_{n}\right\|^{2}}} \geq \sqrt{T}\frac{\rho}{R} \\ \therefore \cos\theta=\frac{\mathbf{w}_{f}^{T}}{\left\|\mathbf{w}_{f}\right\|} \frac{\mathbf{w}_{T}}{\left\|\mathbf{w}_{T}\right\|} \geq \sqrt{T} \cdot constant,\, 其中\, constant = \frac{\rho}{R}
R 2 = n max ∥ x n ∥ 2 ρ = ∥ w f ∥ n min y n w f T x n ∵ w 0 = 0 w f T w T ≥ T n min y n w f T x n ∥ w T ∥ 2 ≤ T n max ∥ x n ∥ 2 c o s θ = ∥ w f ∥ w f T ∥ w T ∥ w T = ∥ w f ∥ 1 ∥ w T ∥ w f T w T = ∥ w f ∥ 1 T
n max ∥ x n ∥ 2
T n min y n w f T x n ≥ T
R ρ ∴ cos θ = ∥ w f ∥ w f T ∥ w T ∥ w T ≥ T
⋅ c o n s t a n t , 其 中 c o n s t a n t = R ρ
Let’s upper-bound T, the number of mistakes that PLA ‘corrects’.
D
e
f
i
n
e
 
R
2
=
max
n
∥
x
n
∥
2
ρ
=
min
n
y
n
w
f
T
x
n
∥
w
f
∥
Define \, R^2 = \max _{n} \|\mathbf{x}_{n}\|^{2} \quad \rho = \frac{\min \limits _{n} y_{n} \mathbf{w}_{f}^{T} x_n}{\mathbf{\| w_f \|}}
D e f i n e R 2 = n max ∥ x n ∥ 2 ρ = ∥ w f ∥ n min y n w f T x n
We want to show that
T
≤
□
T \leq \square
T ≤ □
□
\square
□
R
ρ
\frac{R}{\rho}
ρ R
R
2
ρ
2
\frac{R^2}{\rho^2}
ρ 2 R 2
✓
\checkmark
✓
R
ρ
2
\frac{R}{\rho^2}
ρ 2 R
ρ
2
R
2
\frac{\rho^2}{R^2}
R 2 ρ 2 Explanation
T
ρ
R
≤
w
f
T
∥
w
f
∥
w
T
∥
w
T
∥
=
c
o
s
θ
≤
1
∴
T
≥
ρ
2
R
2
\sqrt{T}\frac{\rho}{R} \leq \frac{\mathbf{w}_{f}^{T}}{\left\|\mathbf{w}_{f}\right\|} \frac{\mathbf{w}_{T}}{\left\|\mathbf{w}_{T}\right\|} = cos\theta\leq 1 \\ \therefore T \geq \frac{\rho^2}{R^2}
T
R ρ ≤ ∥ w f ∥ w f T ∥ w T ∥ w T = c o s θ ≤ 1 ∴ T ≥ R 2 ρ 2
保证
过程
结果
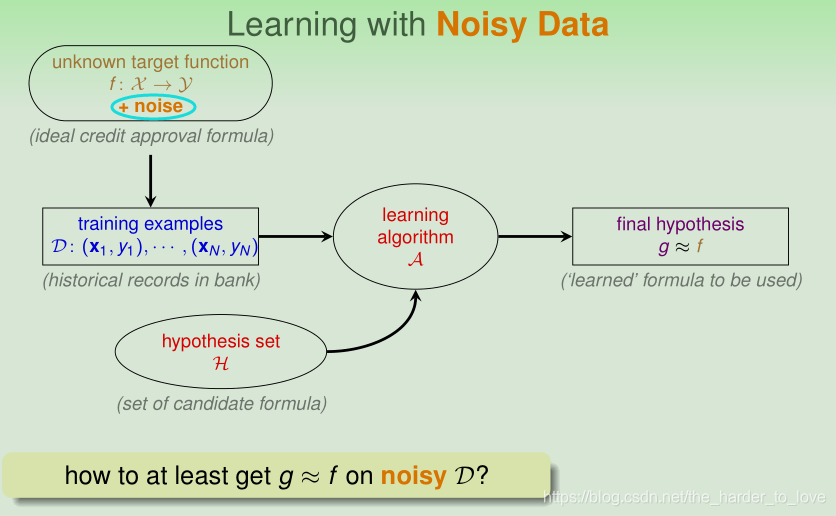
假设数据存在噪音(noise),线性不可分,此时我们想得到一个大致完全分类的感知器。Pocket PLA :modify PLA algorithm (black lines) by keeping best weights in pocket
w
w
w
w
0
w_0
w 0
w
w
w
w
t
w_t
w t
x
n
(
t
)
x_{n(t)}
x n ( t )
y
n
(
t
)
y_{n(t)}
y n ( t )
s
i
g
n
(
w
t
T
x
n
(
t
)
)
≠
y
n
(
t
)
sign(w_t^Tx_{n(t)}) \ne y_{n(t)}
s i g n ( w t T x n ( t ) ) ̸ = y n ( t )
correct the mistake by
w
(
t
+
1
)
←
w
t
+
y
n
(
t
)
x
n
(
t
)
w_{(t+1)} ← w_t + y_{n(t)}x_{n(t)}
w ( t + 1 ) ← w t + y n ( t ) x n ( t )
if
w
t
+
1
w_ {t+1}
w t + 1
w
^
\hat{\mathbf{w}}
w ^
w
^
\hat{\mathbf{w}}
w ^
w
t
+
1
w_ {t+1}
w t + 1
w
(
t
+
1
)
←
w
t
+
y
n
(
t
)
x
n
(
t
)
w_{(t+1)} ← w_t + y_{n(t)}x_{n(t)}
w ( t + 1 ) ← w t + y n ( t ) x n ( t )
… until engough iterations
w
^
\hat{\mathbf{w}}
w ^
w
P
o
c
k
e
t
w_{Pocket}
w P o c k e t
Pocket PLA算法:
w
t
w_{t}
w t
w
^
\hat{\mathbf{w}}
w ^
w
^
\hat{\mathbf{w}}
w ^
Should we use pocket or PLA? Since we do not know whether D is linear separable in advance, we may decide to just go with pocket instead of PLA. If D is actually linear separable, what’s the difference between the two? pocket on D is slower than PLA
✓
\checkmark
✓
Explanation
Perceptron Hypothesis Set
Perceptron Learning Algorithm (PLA)
s
i
g
n
(
w
t
T
x
n
(
t
)
)
≠
y
n
(
t
)
sign(w_t^Tx_{n(t)}) \ne y_{n(t)}
s i g n ( w t T x n ( t ) ) ̸ = y n ( t )
w
(
t
+
1
)
←
w
t
+
y
n
(
t
)
x
n
(
t
)
w_{(t+1)} \leftarrow w_t + y_{n(t)}x_{n(t)}
w ( t + 1 ) ← w t + y n ( t ) x n ( t )
g
←
w
T
g \leftarrow w_T
g ← w T
Guarantee of PLA
Non-Separable Data
w
t
w_{t}
w t
w
^
\hat{\mathbf{w}}
w ^
g
←
w
^
g \leftarrow \hat{\mathbf{w}}
g ← w ^
PLA
A
A
A
D
D
D
《Machine Learning Foundations》(机器学习基石)—— Hsuan-Tien Lin (林轩田)