从jena 到 fuseki完成本地知识图谱数据库的搭建
1. 下载jena,fuseki(恰好他们在同一个网页)
从官网下载最新版Jena,传送门

我存放的目录如下:
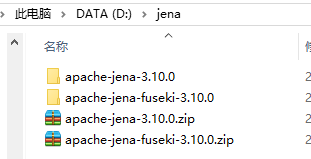
下载完自然是要解压,这个不用说也知道
2、配置环境变量
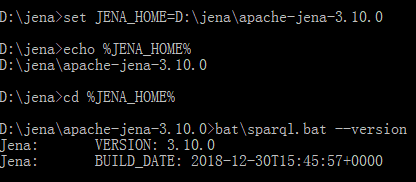
打开命令行,输入一下指令(windows下的)
set JENA_HOME=D:\jena\apache-jena-3.10.0 (这个是我的目录)
echo %JENA_HOME% //显示是否设置成功
cd %JENA_HOME% //切换到里面路径
bat\sparql.bat --version //查看版本
输入命令(linux,好像不行)
export JENA_HOME=.../apache-jena-3.10.0 前面根据实际情况填写
bin/sparql --version
这个不影响,如果我们想在linux下面跑,我们可以把windows下建好的数据库拷贝过去
3、加载rdf文件
假设RDF文件路径为d:\rdf.nt,需要构建的数据库的路径为d:\tdb
在cmd中进入bat文件夹,输入如下命令
tdbloader.bat --loc=d:\tdb d:\rdf.nt
如果有多个文件,则在这行命令之后(不换行)每隔一个空格输入一个RDF文件。
4、安装fuseki,提供网页上的查询服务
按步骤1找到下载,并解压
切换到路径:D:\jena\apache-jena-fuseki-3.10.0
fuseki-server --mem /DatasetPathName
fuseki-server --file=FILE /DatasetPathName
fuseki-server --loc=DB /DatasetPathName
fuseki-server --config=ConfigFile
有四种运行指令,用途如下:

因为我们上面建好另一个tdb ,所以采用第三条命令
fuseki-server --loc=path1 /db
path1 是数据库的路径可以为绝对路径 /db是网上的服务器名称 db的名字可以改为任意的,但是必须以/开头
最后一个参数是HTTP接口的对应访问路径,例如通过localhost:3030进行SPARQL查询。

然后可以通过query进行查询
5、用python写代码查询
from SPARQLWrapper import SPARQLWrapper, JSON
sparql = SPARQLWrapper("http://localhost:3030/db/query")
sparql.setQuery("""
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?s ?p
WHERE { ?s ?p "6717859" .}
LIMIT 3
""")
sparql.setReturnFormat(JSON)
results = sparql.query().convert()
for result in results["results"]["bindings"]:
print(result["s"]["value"])
print(result['p']['value'])
这是一个比较简单的查询,要用到SPARQLWrapper JSON 两个包,主要是查询 三元组第三个值为6717859的前两个值,然后转化为json的格式,最后的结果都 可以通过result[varname][“value”]来访问对应的变量的值。
具体rdf的语法见rdf语法:
具体的查询语法可参考下面的博客sparql查询语法:
认真的同学可能会发现,我们的服务只能是localhost访问,无法被其他人访问,那么 要怎么修改呢.很简单,把apche-jena-fuseki-3.10.0/run 下面的shiro.ini 的做一下修改
/$/** = localhostFilter改为
#/$/** = localhostFilter 即注释即可
然后再运行,发现可以用本地网络的ip地址可以访问,即http://192.168.0.106:3030
比如我网络的当前ip地址如上,然后发现,连同样的wifi的设备都可以访问,但是外 网就不行。
但是我想让所有设备都可以访问,那怎么办呢???
解决方案就是,把fuseki-server 放到云服务器运行
把本地知识图谱数据放到云服务器上,以便在任何主机上都可以访问
(途中需要身份验证的,自行验证即可)
1、申请阿里云的一个服务器
点击下面链接购买云服务器ECS(如果你还没有账号,请注册一个账号)
(1)基础配置:
对与新手,我建议是买一个便宜的体验一下就好
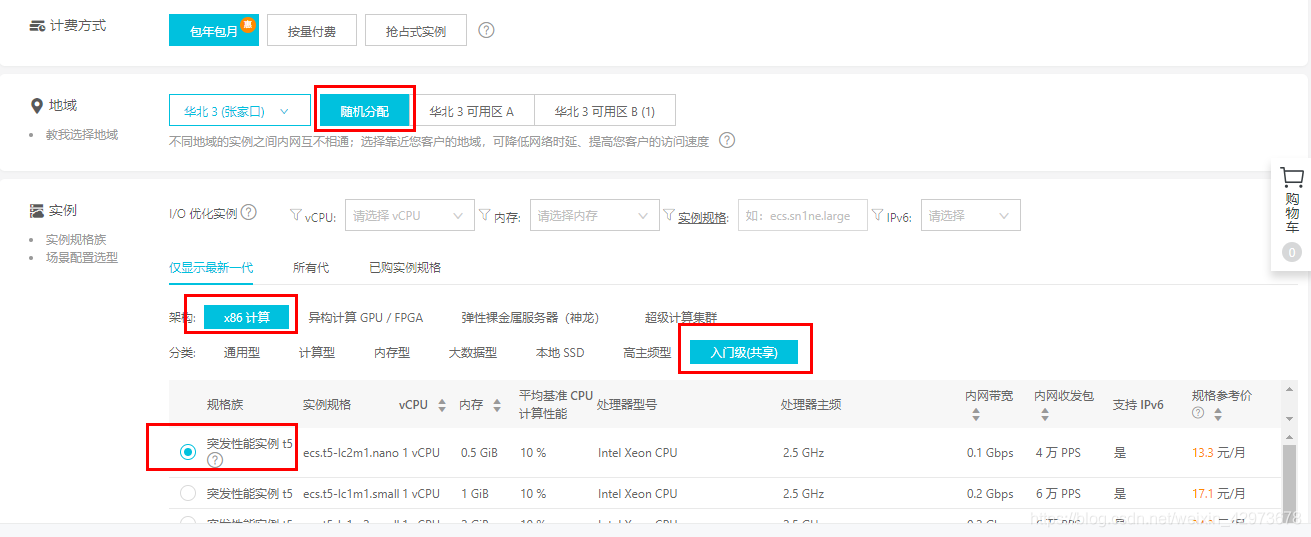
这是最便宜的了

2)网络与安全组配置:
一般默认就好,这里有个要注意的地方
一般初次,需要新建一个安全组,可以如下设置

名字都可以随便写,完成之后,在配置规则处设置一下端口

然后点击添加安全组规则,如下设置,设置端口为3030 是因为fuseki用到的端口是3030,所以要开通。授权对像为0.0.0.0/0 表示所有设备都可以访问

(3)系统配置,选择自定义密码就行,实例名称随便,这个就是后面你主机的名字

后面一直按,付钱就是了
2、管理主机

从上面可以看到,主机的公网ip地址,这个要记住
点击远程链接,它会弹出一个密码,请记住这个密码,以后你连接都要输入这个密码,所以一定要存档。
注意登陆名为用户名root
密码为对应的密码,第三步系统配置的时候设置的,然后可以当作linux的终端使用了,linux终端可以做什么,他就可以做什么。

3、远程管理云服务器主机
想想,只有网上的这个终端,还是比较麻烦的,比如我要传动东西进去,那么,怎么传呢。接下来就介绍winscp和putty的好处了。
下载winscp与安装
下载putty与安装
注意按照putty的时候,默认路径安装就好,不然到时winscp找不到
启动winscp

协议不用改,sftp,主机名用云服务器的ip地址,端口号是22
用户名是主机的用户名,为root 密码为用户登陆密码
登陆即可

然后就可以看见云服务器上面的结构了,那么可以随意把本机的东西复制到云主机上。
点击红框,出现跟linux一样的终端命令行,可以远程操控主机了。
终于,可以方便地在本机上操控远程的服务器了。
4、在云主机上安装jdk
由于jena运行需要依赖java环境,也就是jdk,所以我们必须先在主机上按照jdk。
可以在本地下载好jdk,利用winscp放到云主机上
Jdk下载地址:
下载linux 对应的版本就好,我下载所放的目录如下:
/root/java/jdk-8u201-linux-x64.tar.gz
安装步骤:
(1) 解压
切换到/root/java 目录下
tar -zxvf jdk-8u201-linux-x64.tar.gz 的到文件夹 jdk1.8.0_201
可以新建一个等同简短的目录
ln -s /root/java/jdk1.8.0_201 /root/jdk
(2)配置环境变量
vim /etc/profile //修改文件
添加如下内容:
JAVA_HOME=/root/java/jdk1.8.0_201
CLASSPATH=$ JAVA_HOME/lib/
PATH=$ PATH:$ JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
按下esc ,输入:wq退出
(3)重启机器或者执行命令
source /etc/profile
(4)查看版本信息
java -version
5、重新部署fuseki
把在本地建好的数据库 tdb复制到云主机上
把fuseki 和jena 都复制到云主机上
如同windows下所述,运行fuseki-server -loc=/root/tdb /db
然后就可以在本地输入云主机上的ip,进行网页查询访问
例如我的是:47.92.51.224:3030 即可
终于写完了,完结撒花

