介绍一下爬取网页的神器,火车头采集器的使用教程
下面以电商网站tophatter电商网站为例
-
新建任务

-
向导添加

-
批量网址

地址设为上图格式
地址参数为1开始 (就是商品的id编号) 我从115697202开始测的后面1000条 基本100条无效 -
点击设置

-
填写任务名保存

-
内容采集
设置需要爬取的字段
这里采用前后截取,购买过的可以使用json提取。

所有字段格式与上图相同
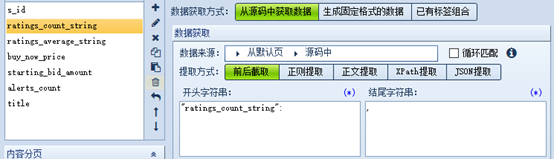
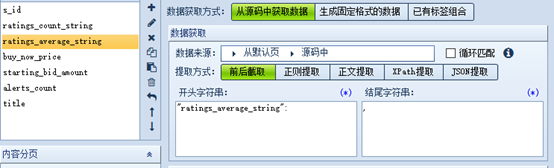
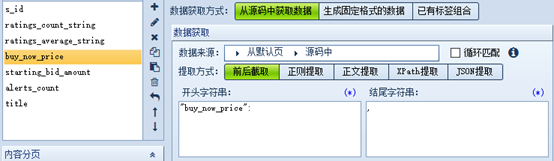

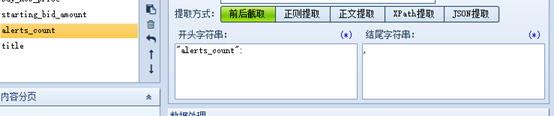
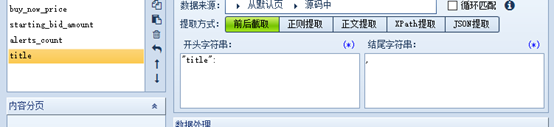
保存并退出
字段来源:https://tophatter.com/api/v1/lots/115697202 -
主界面开始任务

-
等待采集完成后
点击数据 复制内容到excel即可
