#文本清理问题会涉及到包括文本解析与数据处理等一系列问题。在非常简单情形下,可能会选择使用字符串函数
#(str.upper(),str.lower())将文本转为标准格式。使用str.replace()或者re.sub()的简单
#替换操作能删除或者改变指定的字符序列。同时可以使用2.9的unicodedata.normalize()函数将
#unicode文本标准化。若你想去除整个区间上的字符或者去除变音符,str.translate()
s = 'pýtĥöñ\fis\tawesome\r\n'
print(s)
![]()
python各种转义字符含义:https://blog.csdn.net/qq_21997625/article/details/89293551
#第一步是清理空白字符,先创建一个小的转换表格然后使用translate()方法
remap ={
ord('\t'):' ', #ord函数返回字符ascii码
ord('\f'):' ',
ord('\r'):None #Deleted
}
a = s.translate(remap) #按照上面dict中的转换
#空白字符\t和\f已经被重新映射到一个空格。回车字符r直接被删除
print(a)![]()
#可以以这个表格为基础进一步构建更大的表格,比如要删除所有的和音字符:
import unicodedata
import sys
cmb_chars=dict.fromkeys(c for c in range(sys.maxunicode)
if unicodedata.combining(chr(c)))
#dict.fromkeys()方法构造一个字典,每个unicode和音符作为键,对应值全为None
b=unicodedata.normalize('NFD',a)
#normalize将原始输入标准化为分解形式字符。然后再调用translate函数删除所有重音符
print(b)
print(b.translate(cmb_chars)) #转换后的正常字符
#同样的技术也可以被用来删除其他类型的字符(比如控制字符等)
#这个例子构造一个将所有unicode数字字符映射到对应的ASCII字符的表格上
digitmap = {c:ord('0')+unicodedata.digit(chr(c))
for c in range(sys.maxunicode)
if unicodedata.category(chr(c))=='Nd'}
print(len(digitmap))
x = '\u0661\u0662\u0663'
print(x.translate(digitmap))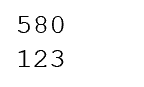
#另一种清理文本的技术涉及到I/O解码与编码函数。思路是先对文本做一些初步清理,再
#结合encode()或者decode()操作清除或者修改它。
print(a)
b=unicodedata.normalize('NFD',a)
print(b.encode('ascii','ignore').decode('ascii'))
#这里normalize操作将原来文本分解为单独的和音符。接下来ascii编码/解码只是简单一下子丢弃掉那些字符
#一般文本字符清理性能很重要,代码越简单运行越快。replace通常最快。。
def clean_spaces(s): #清理空白字符
s=s.replace('\r','')
s=s.replace('\t',' ')
s=s.replace('\f',' ')
return s
#若执行复杂字符的重新映射或者删除操作,translate()方法会很快