目录
3.5 ConcurrentHashMap与HashTable区别?
1.集合总图
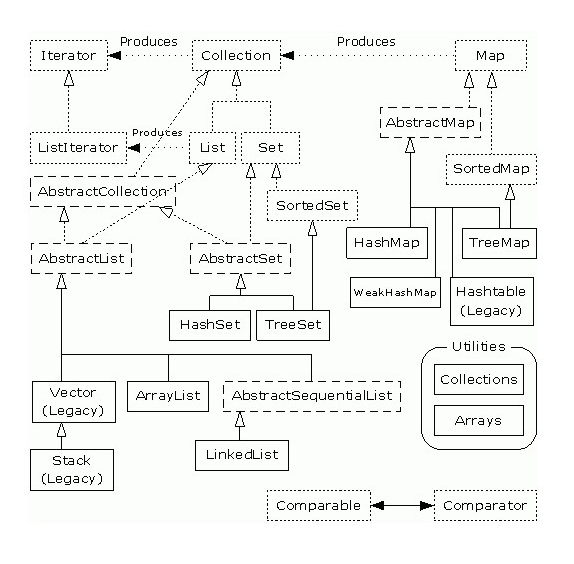
2.Collection的底层实现及应用

2.1 Collection

2.1.1 Collection使用的场景
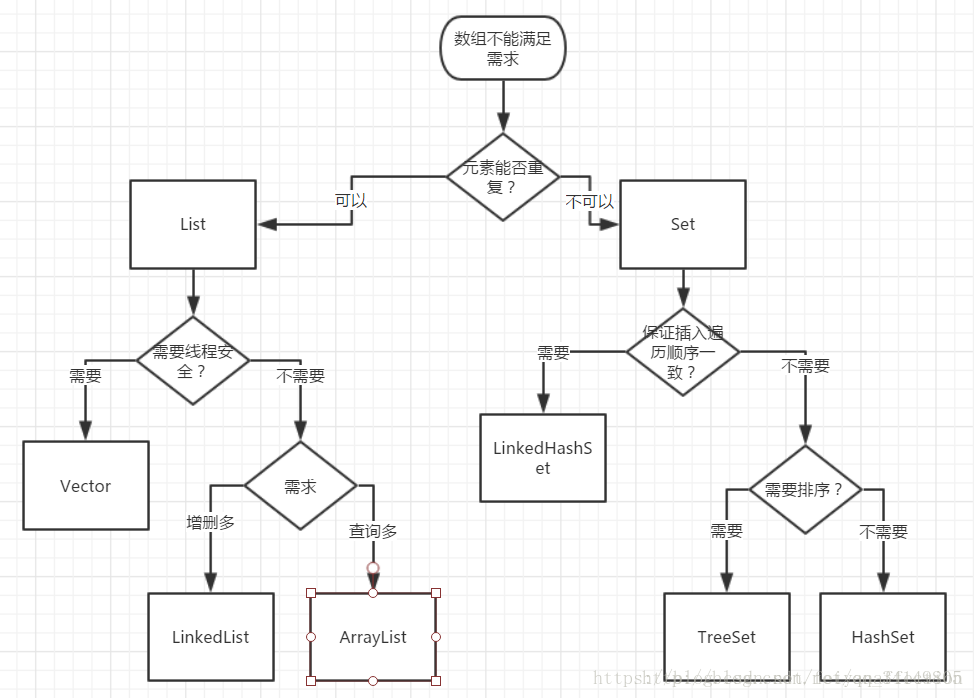
2.1.2 List
List 之 ArrayList介绍:
- ArrayList 是一个数组队列,相当于 动态数组。与Java中的数组相比,它的容量能动态增长。
- ArrayList的适用场景:数组大小动态变化,效率高,查询多,不需要线程安全。
- ArrayList起始大小为10,每次扩充为当前的1.5倍。
// 起始大小 private static final int DEFAULT_CAPACITY = 10;// 扩容 private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); }- ArrayList支持3种遍历方式:
(1) 第一种,通过迭代器遍历。即通过Iterator去遍历。 Integer value = null; Iterator iter = list.iterator(); while (iter.hasNext()) { value = (Integer)iter.next(); } (2) 第二种,随机访问,通过索引值去遍历。 由于ArrayList实现了RandomAccess接口,它支持通过索引值去随机访问元素。 Integer value = null; int size = list.size(); for (int i=0; i<size; i++) { value = (Integer)list.get(i); } (3) 第三种,for循环遍历。如下: Integer value = null; for (Integer i:list) { value = i; }- 常用方法摘要:
booleanadd(E e)
将指定的元素添加到此列表的尾部。voidclear()
移除此列表中的所有元素。Objectclone()
返回此 ArrayList 实例的浅表副本。booleancontains(Object o)
如果此列表中包含指定的元素,则返回 true。voidensureCapacity(int minCapacity)
如有必要,增加此 ArrayList 实例的容量,以确保它至少能够容纳最小容量参数所指定的元素数。Eget(int index)
返回此列表中指定位置上的元素。intindexOf(Object o)
返回此列表中首次出现的指定元素的索引,或如果此列表不包含元素,则返回 -1。booleanisEmpty()
如果此列表中没有元素,则返回 trueintlastIndexOf(Object o)
返回此列表中最后一次出现的指定元素的索引,或如果此列表不包含索引,则返回 -1。Eremove(int index)
移除此列表中指定位置上的元素。booleanremove(Object o)
移除此列表中首次出现的指定元素(如果存在)。Eset(int index, E element)
用指定的元素替代此列表中指定位置上的元素。intsize()
返回此列表中的元素数。Object[]toArray()
按适当顺序(从第一个到最后一个元素)返回包含此列表中所有元素的数组。
List 之 LinkedList介绍:
- LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用- LinkedList适用场景:队列结构和栈结构
import java.util.*; public class TEST { public static void main(String[] args) { /** 1、Queue 实现队列结构 public interface Queue<E>extends Collection<E> * 队列, 一种常用的数据结构,可以将队列看做是一种特殊的线性表,该结构遵循的先进先出原则。Java中,LinkedList实现了Queue接口,因为LinkedList进行插入、删除操作效率较高 相关方法: boolean offer(E e):将元素追加到队列末尾,若添加成功则返回true。 E poll():从队首删除并返回该元素。 E peek():返回队首元素,但是不删除 */ public class QueueDemo { public static void main(String [] args) { Queue<String> queue = new LinkedList<String>(); //追加元素 queue.offer("one"); queue.offer("two"); queue.offer("three"); queue.offer("four"); System.out.println(queue); //从队首取出元素并删除 String poll = queue.poll(); System.out.println(poll); System.out.println(queue); //从队首取出元素但是不删除 String peek = queue.peek(); System.out.println(peek); System.out.println(queue); //遍历队列,这里要注意,每次取完元素后都会删除,整个 //队列会变短,所以只需要判断队列的大小即可 while(queue.size() > 0) { System.out.println(queue.poll()); } } } /**2、Deque 实现栈结构 public interface Deque<E>extends Queue<E> 双向队列,指该队列两端的元素既能入队(offer)也能出队(poll),如果将Deque限制为只能从一端入队和出队,则可实现栈的数据结构。对于栈而言,有入栈(push)和出栈(pop),遵循先进后出原则 常用方法如下: void push(E e):将给定元素”压入”栈中。存入的元素会在栈首。即:栈的第一个元素 E pop():将栈首元素删除并返回。 E peek():返回栈顶元素,但是不删除 */ public class DequeDemo { public static void main(String[] args) { Deque<String> deque = new LinkedList<String>(); deque.push("a"); deque.push("b"); deque.push("c"); System.out.println(deque); //获取栈首元素后,元素不会出栈 String str = deque.peek(); System.out.println(str); System.out.println(deque); while(deque.size() > 0) { //获取栈首元素后,元素将会出栈 System.out.println(deque.pop()); } System.out.println(deque); } } } }LinkedList常用的3种遍历方式:
(1) 第一种,通过迭代器遍历。即通过Iterator去遍历。 for(Iterator iter = list.iterator(); iter.hasNext();) iter.next(); (2) 通过快速随机访问遍历LinkedList int size = list.size(); for (int i=0; i<size; i++) { list.get(i); } (3) 通过另外一种for循环来遍历LinkedList for (Integer integ:list) ;
2.1.3 Set
Set 之 HashSet介绍:
- HashSet底层数据结构采用哈希表实现,元素无序且唯一,线程不安全,效率高,可以存储null元素,元素的唯一性是靠所存储元素类型是否重写hashCode()和equals()方法来保证的,如果没有重写这两个方法,则无法保证元素的唯一性。
- 实现唯一性的过程:首先会使用hash()算法函数对每个对象生成一个int类型hashCode散列值,然后跟已经存储的元素的hashCode值比较,如果hashCode不相等,则所存储的两个对象一定不相等,此时存储当前的新的hashCode值的元素对象;如果hashCode相等,存储元素的对象还是不一定相等,此时会调用equals()方法判断两个对象的内容是否相等,如果内容相等,那么就是同一个对象,无需存储;如果比较的内容不相等,那么就是不同的对象,就该存储了,此时就要采用哈希的解决地址冲突算法,在当前hashCode值处类似一个新的链表, 在同一个hashCode值的后面存储存储不同的对象,这样就保证了元素的唯一性。
- HashSet的适用场景:去重,高效查找
- HashSet和其他集合的转换
import java.util.*; public class TEST { public static void main(String[] args) { /** * ArrayList 转换成 HashSet ArrayList<Integer> arrayList = new ArrayList<>(); arrayList.add(1); arrayList.add(1); arrayList.add(2); arrayList.add(2); arrayList.add(2); arrayList.add(3); HashSet<Integer> hashSet = new HashSet<>(arrayList); System.out.println(hashSet.size()); for (int i : hashSet) System.out.println(i); */ /** * Array 转换成 HashSet Integer[] arr = new Integer[4]; arr[0] = 1; arr[1] = 1; arr[2] = 1; arr[3] = 1; HashSet<Integer> hashSet = new HashSet<Integer>(Arrays.asList(arr)); System.out.println(hashSet.size()); for (int i : hashSet) System.out.println(i); */ /** * HashSet 转成 [] HashSet<Integer> hashSet = new HashSet<>(); hashSet.add(1); hashSet.add(3); hashSet.add(2); Object[] array= hashSet.toArray(); for (Object i : array) System.out.println(i); */ } }HashSet方法摘要
booleanadd(E e)
如果此 set 中尚未包含指定元素,则添加指定元素。voidclear()
从此 set 中移除所有元素。Objectclone()
返回此 HashSet 实例的浅表副本:并没有复制这些元素本身。booleancontains(Object o)
如果此 set 包含指定元素,则返回 true。booleanisEmpty()
如果此 set 不包含任何元素,则返回 true。Iterator<E>iterator()
返回对此 set 中元素进行迭代的迭代器。booleanremove(Object o)
如果指定元素存在于此 set 中,则将其移除。intsize()
返回此 set 中的元素的数量(set 的容量)。HashSet遍历方法:
//1、迭代器遍历: Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } //2、for遍历set for (String s : set) { System.out.println(s); }
Set 之 TreeSet介绍:
- TreeSet底层数据结构采用红黑树(平衡二叉树)来实现,元素唯一且已经排好序;唯一性同样需要重写hashCode和equals()方法,二叉树结构保证了元素的有序性。根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造)。
- 重点描述TreeSet的两种排序方式:(内容较多,另起一篇)点击查看
- TreeSet方法摘要
booleanadd(E e)
将指定的元素添加到此 set(如果该元素尚未存在于 set 中)。Eceiling(E e)
返回此 set 中大于等于给定元素的最小元素;如果不存在这样的元素,则返回null。voidclear()
移除此 set 中的所有元素。Objectclone()
返回TreeSet实例的浅表副本。booleancontains(Object o)
如果此 set 包含指定的元素,则返回true。Efirst()
返回此 set 中当前第一个(最低)元素。Efloor(E e)
返回此 set 中小于等于给定元素的最大元素;如果不存在这样的元素,则返回null。booleanisEmpty()
如果此 set 不包含任何元素,则返回true。booleanremove(Object o)
将指定的元素从 set 中移除(如果该元素存在于此 set 中)。intsize()
返回 set 中的元素数(set 的容量)。- TreeSet遍历
//1、迭代器遍历: Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } //2、for遍历set for (String s : set) { System.out.println(s); }
3. Map的底层实现及应用
Map用于保存具有映射关系的数据,Map里保存着两组数据:key和value,它们都可以使任何引用类型的数据,但key不能重复。所以通过指定的key就可以取出对应的value。

3.1 HashMap
- public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
- 基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
- 假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性能。迭代 collection 视图所需的时间与 HashMap 实例的“容量”(桶的数量)及其大小(键-值映射关系数)成比例。所以,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
- HashMap 的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂。(扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入)
*查看源码: // 初始容量 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16// 默认加载因子 static final float DEFAULT_LOAD_FACTOR = 0.75f;//扩容 newCap = oldCap << 1 - 通常,默认加载因子 (.75) 在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
- 如果很多映射关系要存储在 HashMap 实例中,则相对于按需执行自动的 rehash 操作以增大表的容量来说,使用足够大的初始容量创建它将使得映射关系能更有效地存储。
- 注意,此实现不是同步的。如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须 保持外部同步。
3.2 TreeMap
- public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, Serializable
- 基于红黑树(Red-Black tree)的
NavigableMap实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的Comparator进行排序,具体取决于使用的构造方法。 - 此实现为 containsKey、get、put 和 remove 操作提供受保证的 log(n) 时间开销。这些算法是 Cormen、Leiserson 和 Rivest 的 Introduction to Algorithms 中的算法的改编。
- 注意,如果要正确实现 Map 接口,则有序映射所保持的顺序(无论是否明确提供了比较器)都必须与 equals 一致。。这是因为 Map 接口是按照 equals 操作定义的,但有序映射使用它的 compareTo(或 compare)方法对所有键进行比较,因此从有序映射的观点来看,此方法认为相等的两个键就是相等的。即使排序与 equals 不一致,有序映射的行为仍然是 定义良好的,只不过没有遵守 Map 接口的常规协定。
- 注意,此实现不是同步的。如果多个线程同时访问一个映射,并且其中至少一个线程从结构上修改了该映射,则其必须 外部同步。
3.3 Hashtable
- public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, Serializable
- 此类实现一个哈希表,该哈希表将键映射到相应的值。任何非
null对象都可以用作键或值。 - 为了成功地在哈希表中存储和获取对象,用作键的对象必须实现
hashCode方法和equals方法。 Hashtable的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。- 通常,默认加载因子(.75)在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
- 初始容量主要控制空间消耗与执行
rehash操作所需要的时间损耗之间的平衡。如果初始容量大于 Hashtable 所包含的最大条目数除以加载因子,则永远 不会发生rehash操作。但是,将初始容量设置太高可能会浪费空间。
3.4 HashMap和Hashtable的比较
- 底层技术:HashMap是数组+链表;Hashtable也是数组+链表。
- 线程安全:HashMap是线程不安全的;Hashtable是线程安全的,在修改数据时将锁住整个Hashtable,效率低。
- K-V空值:HashMap的key和value都可以为null,但是最多只能有一个key值为null;Hashtable的key和value不可以为null。因此HashMap去掉了HashTable的contains方法,但是加上了containsValue()和containsKey()方法。
- 初始容量:HashMap:初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂。(扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入);Hashtable:初始size为11,扩容:newsize = olesize*2+1
- hash方法:HashMap计算hash时对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸;Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模。
3.5 ConcurrentHashMap与HashTable区别?
ConcurrentHashMap是一个线程安全的,那么我么看一下ConcurrentHashMap如何进行操作的。
ConcurrentHashMap与HashTable区别?
HashTable
put()源代码
从代码可以看出来在所有put 的操作的时候 都需要用 synchronized 关键字进行同步。并且key 不能为空。
这样相当于每次进行put 的时候都会进行同步 当10个线程同步进行操作的时候,就会发现当第一个线程进去 其他线程必须等待第一个线程执行完成,才可以进行下去。性能特别差。
CurrentHashMap
分段锁技术:ConcurrentHashMap相比 HashTable而言解决的问题就是 的 它不是锁全部数据,而是锁一部分数据,这样多个线程访问的时候就不会出现竞争关系。不需要排队等待了。
从图中可以看出来ConcurrentHashMap的主干是个Segment数组。
这就是为什么ConcurrentHashMap支持允许多个修改同时并发进行,原因就是采用的Segment分段锁功能,每一个Segment 都想的于小的hash table并且都有自己锁,只要修改不再同一个段上就不会引起并发问题。
final Segment<K,V>[] segments;
1
使用ConConcurrentHashMap时候 有时候会遇到跨段的问题,跨段的时候【size()、 containsValue()】,可能需要锁定部分段或者全段,当操作结束之后,又回按照 顺序 进行 释放 每一段的锁。注意是按照顺序解锁的。,每个Segment又包含了多个HashEntry.
transient volatile HashEntry<K,V>[] table;
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
//其他省略
}
需要注意的是 Segment 是一种可重入锁(继承ReentrantLock)
那么我简单说一下ReentrantLock 与synchronized有什么区别?
synchronized 是一个同步锁 synchronized (this)
同步锁 当一个线程A 访问 【资源】的代码同步块的时候,A线程就会持续持有当前锁的状态,如果其他线程B-E 也要访问【资源】的代码同步块的时候将会收到阻塞,因此需要排队等待A线程释放锁的状态。(如图情况1)但是注意的是,当一个线程B-E 只是不能方法 A线程 【资源】的代码同步块,仍然可以访问其他的非资源同步块。
ReentrantLock 可重入锁 通常两类:公平性、非公平性
公平性:根据线程请求锁的顺序依次获取锁,当一个线程A 访问 【资源】的期间,线程A 获取锁资源,此时内部存在一个计数器num+1,在访问期间,线程B、C请求 资源时,发现A 线程在持有当前资源,因此在后面生成节点排队(B 处于待唤醒状态),假如此时a线程再次请求资源时,不需要再次排队,可以直接再次获取当前资源 (内部计数器+1 num=2) ,当A线程释放所有锁的时候(num=0),此时会唤醒B线程进行获取锁的操作,其他C-E线程就同理。(情况2)
非公平性:当A线程已经释放所之后,准备唤醒线程B获取资源的时候,此时线程M 获取请求,此时会出现竞争,线程B 没有竞争过M线程,测试M获取的线程因此,M会有限获得资源,B继续睡眠。(情况2)
synchronized 是一个非公平性锁。 非公平性 会比公平性锁的效率要搞很多原因,不需要通知等待。
ReentrantLock 提供了 new Condition可以获得多个Condition对象,可以简单的实现比较复杂的线程同步的功能.通过await(),signal()以实现。
ReentrantLock 提供可以中断锁的一个方法lock.lockInterruptibly()方法。
Jdk 1.8 synchronized和 ReentrantLock 比较的话,官方比较建议用synchronized。
在了解Segment 机制之后我们继续看一下ConcurrentHashMap核心构造方法代码。
// 跟HashMap结构有点类似
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;//负载因子
this.threshold = threshold;//阈值
this.table = tab;//主干数组即HashEntry数组
}
构造方法
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
//MAX_SEGMENTS 为1<<16=65536,也就是最大并发数为65536
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
//ssize 为segments数组长度,concurrentLevel计算得出
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
//segmentShift和segmentMask这两个变量在定位segment时会用到
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//计算cap的大小,即Segment中HashEntry的数组长度,cap也一定为2的n次方.
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
//创建segments数组并初始化第一个Segment,其余的Segment延迟初始化
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0);
this.segments = ss;
}
从以上代码可以看出ConcurrentHashMap有比较重要的三个参数:
loadFactor 负载因子 0.75
threshold 初始 容量 16
concurrencyLevel 实际上是Segment的实际数量。
ConcurrentHashMap如何发生ReHash?
ConcurrentLevel 一旦设定的话,就不会改变。ConcurrentHashMap当元素个数大于临界值的时候,就会发生扩容。但是ConcurrentHashMap与其他的HashMap不同的是,它不会对Segmengt 数量增大,只会增加Segmengt 后面的链表容量的大小。即对每个Segmengt 的元素进行的ReHash操作。
我们再看一下核心的ConcurrentHashMapput ()方法:
public V put(K key, V value) {
Segment<K,V> s;
//concurrentHashMap不允许key/value为空
if (value == null)
throw new NullPointerException();
//hash函数对key的hashCode重新散列,避免差劲的不合理的hashcode,保证散列均匀
int hash = hash(key);
//返回的hash值无符号右移segmentShift位与段掩码进行位运算,定位segment
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
主要注意的是 当前put 方法 当前key 为空的时候 ,代码报错。
这个代码主要是把Key 通过Hash函数计算出hash值 现计算出当前key属于那个Segment 调用Segment.put 分段方法Segment.put()
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :scanAndLockForPut(key, hash, value);
//tryLock()是ReentrantLock获取锁一个方法。如果当前线程获取锁成功 返回true,如果别线程获取了锁返回false不成功时会遍历定位到的HashEnry位置的链表(遍历主要是为了使CPU缓存链表),若找不到,则创建HashEntry。tryLock一定次数后(MAX_SCAN_RETRIES变量决定),则lock。若遍历过程中,由于其他线程的操作导致链表头结点变化,则需要重新遍历。
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;//定位HashEntry,可以看到,这个hash值在定位Segment时和在Segment中定位HashEntry都会用到,只不过定位Segment时只用到高几位。
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
//若c超出阈值threshold,需要扩容并rehash。扩容后的容量是当前容量的2倍。这样可以最大程度避免之前散列好的entry重新散列。扩容并rehash的这个过程是比较消耗资源的。
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
Put 时候 ,通过Hash函数将即将要put 的元素均匀的放到所需要的Segment 段中,调用Segment的put 方法进行数据。
Segment的put 是加锁中完成的。如果当前元素数大于最大临界值的的话将会产生rehash. 先通过 getFirst 找到链表的表头部分,然后遍历链表,调用equals 比配是否存在相同的key ,如果找到的话,则将最新的Key 对应value值。如果没有找到,新增一个HashEntry 它加到整个Segment的头部。
我们先看一下Get 方法的源码:
//计算Segment中元素的数量
transient volatile int count;
***********************************************************
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
***********************************************************
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
********************************************************
V get(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
return null;
}
1.读取的时候 传递Key值,通过Hash函数计算出 对应Segment 的位置。
2.调用segmentFor(int hash) 方法,用于确定操作应该在哪一个segment中进行 ,通过 右无符号位运算 右移segmentShift位在与运算 segmentMask【偏移码】 获得需要操作的Segment
确定了需要操作的Segment 再调用 get 方法获取对应的值。通过count 值先判断当前值是否为空。在调用getFirst()获取头节点,然后遍历列表通过equals对比的方式进行比对返回值。
ConcurrentHashMap为什么读的时候不加锁?
ConcurrentHashMap是分段并发分段进行读取数据的。
Segment 里面有一个Count 字段,用来表示当前Segment中元素的个数 它的类型是volatile变量。所有的操作到最后都会 在最后一部更新count 这个变量,由于volatile变量 happer-before的特性。导致get 方法能够几乎准确的获取最新的结构更新。
再看一下ConcurrentHashMapRemove()方法:
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
调用Segment 的remove 方法,先定位当前要删除的元素C,此时需要把A、B元素全部复制一遍,一个一个接入到D上。
remove 也是在加锁的情况下进行的。
volatile 变量
我们发现 对于CurrentHashMap而言的话,源码里面又很多地方都用到了这个变量。比如HashEntry 、value 、Segment元素个数Count。
volatile 属于JMM 模型中的一个词语。首先先简单说一下 Java内存模型中的 几个概念:
原子性:保证 Java内存模型中原子变量内存操作的。通常有 read、write、load、use、assign、store、lock、unlock等这些。
可见性:就是当一个线程对一个变量进行了修改,其他线程即可立即得到这个变量最新的修改数据。
有序性:如果在本线程内观察,所有操作都是有序的;如果在一个线程中观察另一个线程,所有操作都是无序的。
先行发生:happen-before 先行发生原则是指Java内存模型中定义的两项操作之间的依序关系,如果说操作A先行发生于操作B,其实就是说发生操作B之前.
传递性
volatile 变量 与普通变量的不同之处?
volatile 是有可见性,一定程度的有序性。
volatile 赋值的时候新值能够立即刷新到主内存中去,每次使用的时候能够立刻从内存中刷新。
4. 感谢:
https://blog.csdn.net/feiyanaffection/article/details/81394745
https://blog.csdn.net/qq_35181209/article/details/74503362
https://blog.csdn.net/wz249863091/article/details/52843060
https://www.cnblogs.com/heyonggang/p/9112731.html
https://blog.csdn.net/jinhuoxingkong/article/details/51191106
https://blog.csdn.net/u013317445/article/details/82181179
https://blog.csdn.net/xiaofei__/article/details/53138681