首页
移动开发
物联网
服务端
编程语言
企业开发
数据库
业界资讯
其他
搜索
scrapy爬取伯乐在线文章数据
其他
2019-04-24 09:08:07
阅读次数: 0
创建项目
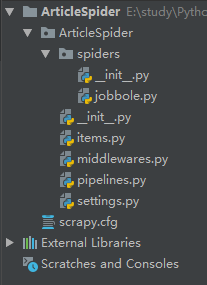
切换到ArticleSpider目录下创建爬虫文件
猜你喜欢
转载自
www.cnblogs.com/bkwxx/p/10760340.html
scrapy爬取伯乐在线文章数据
Scrapy爬取伯乐在线文章
Scrapy爬取伯乐在线的所有文章
Scrapy爬取伯乐在线所有文章
爬虫实战——Scrapy爬取伯乐在线所有文章
scrapy入门:爬取伯乐在线
【Scrapy教程】01 初学者笔记(爬取伯乐在线文章实战)
基于scrapy的分布式爬虫(5):伯乐在线文章爬取
使用scrapy爬取伯乐在线多线程存为MySQL数据库
重磅!PYTHON实战使用SCRAPY框架爬取伯乐在线 5000多条数据
Scrapy分布式爬虫打造搜索引擎- (二)伯乐在线爬取所有文章
爬取伯乐在线文章(三)爬取所有页面的文章
爬取伯乐在线文章(四)将爬取结果保存到MySQL
Scrapy分布式爬虫打造搜索引擎——(二) scrapy 爬取伯乐在线
Python爬虫爬取伯乐在线
Scrapy爬取伯乐在线采用两种入库方法
Python爬虫之scrapy--01爬取伯乐网文章
爬取伯乐在线文章(二)通过xpath提取源文件中需要的内容
第三天,爬取伯乐在线文章代码,编写items.py,保存数据到本地json文件中
伯乐在线文章URL
Python爬虫-爬取伯乐在线美女邮箱
Python爬虫爬取伯乐在线网站信息
scrapy爬取某个手机app的文章数据
使用scrapy框架进行抓取伯乐在线所有文章(一)
scrapy定向爬取jobbole文章
python爬虫系列(3.4-使用xpath和lxml爬取伯乐在线)
scrapy爬取动态数据
Scrapy全站数据爬取
scrapy图片数据爬取
bs4主要知识点介绍及实例解析---利用bs4爬取伯乐在线(分别存储在数据库和xls表中)
今日推荐
NetBSD 禁止提交由 AI 生成的代码
Apache Doris 2.0.10 版本正式发布!
开源日报 | 大模型开战;大模型独角兽被曝卖身;周鸿祎建议谷歌开源所有产品;最大开源AI社区提供1000万美元共享GPU
开源日报 | Chrome内置Gemini的意义不在于Gemini;中国AI追随之路的五大误区;ECharts创始人“下海”养鱼;谷歌I/O开发者大会什么都有,只是没有惊喜
微软回应中国区AI团队“打包赴美”传闻
基于大语言模型的开源知识库问答系统 MaxKB GitHub Star 数量突破 5,000 个!
周排行
static方法和非static方法的区别(java)
如何查找计算机专业paper
java.lang.ClassFormatError: Incompatible magic value 0 in class file com/sitecha
跳跃游戏II
stm32_之【建立工程】
TeaWeb v0.0.9 发布,统计底层优化、主机监控功能改进
事件分发 -----控制字体大小
JavaScript DOM练习(动态表格添加) December 25,2019
JSF Scope & CDI
实现从零搭建一个登录注册页面(附源代码)
每日归档
更多
2024-05-19(0)
2024-05-18(4)
2024-05-17(34)
2024-05-16(6)
2024-05-15(24)
2024-05-14(0)
2024-05-13(18)
2024-05-12(0)
2024-05-11(38)
2024-05-10(38)