-nearest neighbors algorithm -
最近邻算法
In pattern recognition, the
-nearest neighbors algorithm (
-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the
closest training examples in the feature space. The output depends on whether
-NN is used for classification or regression.
在模式识别领域,
-近邻算法 (
-NN 算法) 是一种用于分类和回归的非参数统计方法。在这两种情况下,输入包含特征空间 (feature space) 中的
个最接近的训练样本。
-
In -NN classification, the output is a class membership. An object is classified by a plurality vote of its neighbors, with the object being assigned to the class most common among its nearest neighbors ( is a positive integer, typically small). If , then the object is simply assigned to the class of that single nearest neighbor.
-
In -NN regression, the output is the property value for the object. This value is the average of the values of nearest neighbors.
-
在 -NN 分类中,输出是一个分类族群。一个对象的分类是由其邻居的多数表决确定的, 个最近邻 ( 为正整数,通常较小) 中最常见的分类决定了赋予该对象的类别。若 ,则该对象的类别直接由最近的一个节点赋予。
-
在 -NN 回归中,输出是该对象的属性值。该值是其 个最近邻的值的平均值。
plurality [plʊə'rælɪtɪ];n. 多数,复数,兼职,胜出票数
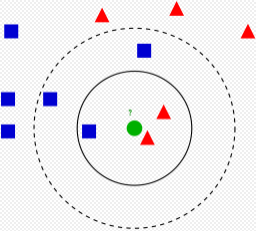
Example of
-NN classification. The test sample (green dot) should be classified either to the first class of blue squares or to the second class of red triangles. If
= 3 (solid line circle) it is assigned to the second class because there are 2 triangles and only 1 square inside the inner circle. If
= 5 (dashed line circle) it is assigned to the first class (3 squares vs. 2 triangles inside the outer circle).
近邻算法示例。测试样本 (绿色圆形) 应归入要么是第一类的蓝色方形或是第二类的红色三角形。如果
= 3 (实线圆圈) 它被分配给第二类,因为有 2 个三角形和只有 1 个正方形在内侧圆圈之内。如果
= 5 (虚线圆圈) 它被分配到第一类 ( 3 个正方形与 2 个三角形在外侧圆圈之内)。
最近邻法采用向量空间模型来分类,概念为相同类别的样本,彼此的相似度高,可以借由计算与已知类别样本之相似度,来评估未知类别样本可能的分类。
-NN is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until classification. The
-NN algorithm is among the simplest of all machine learning algorithms.
-NN 是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。
-近邻算法是所有的机器学习算法中最简单的之一。
Both for classification and regression, a useful technique can be used to assign weight to the contributions of the neighbors, so that the nearer neighbors contribute more to the average than the more distant ones. For example, a common weighting scheme consists in giving each neighbor a weight of
, where
is the distance to the neighbor.
无论是分类还是回归,衡量邻居的权重都非常有用,使较近邻居的权重比较远邻居的权重大。例如,一种常见的加权方案是给每个邻居权重赋值为
,其中
是到邻居的距离。
distant ['dɪst(ə)nt]:adj. 遥远的,冷漠的,远隔的,不友好的,冷淡的
defer [dɪ'fɜː]:vi. 推迟,延期,服从 vt. 使推迟,使延期
triangle ['traɪæŋg(ə)l]:n. 三角,三角关系,三角形之物,三人一组
The neighbors are taken from a set of objects for which the class (for
-NN classification) or the object property value (for
-NN regression) is known. This can be thought of as the training set for the algorithm, though no explicit training step is required.
邻居都取自一组已经正确分类 (在回归的情况下,指属性值正确) 的对象。虽然没要求明确的训练步骤,但这也可以当作是此算法的一个训练样本集。
explicit [ɪk'splɪsɪt; ek-];adj. 明确的,清楚的,直率的,详述的
peculiarity [pɪ,kjuːlɪ'ærɪtɪ]:n. 特性,特质,怪癖,奇特
A peculiarity of the
-NN algorithm is that it is sensitive to the local structure of the data.
-近邻算法的缺点是对数据的局部结构非常敏感。本算法与
-平均算法没有任何关系,请勿混淆。
Statistical setting
Suppose we have pairs taking values in , where is the class label of , so that for (and probability distributions ). Given some norm on and a point , let be a reordering of the training data such that .
Algorithm - 算法
The training examples are vectors in a multidimensional feature space, each with a class label. The training phase of the algorithm consists only of storing the feature vectors and class labels of the training samples.
训练样本是多维特征空间向量,其中每个训练样本带有一个类别标签。算法的训练阶段只包含存储的特征向量和训练样本的标签。
In the classification phase,
is a user-defined constant, and an unlabeled vector (a query or test point) is classified by assigning the label which is most frequent among the
training samples nearest to that query point.
在分类阶段,
是一个用户定义的常数。一个没有类别标签的向量 (查询或测试点) 将被归类为最接近该点的
个样本点中最频繁使用的一类。
multidimensional [,mʌltɪdɪ'mɛnʃənl];adj. 多维的,多面的
A commonly used distance metric for continuous variables is Euclidean distance. For discrete variables, such as for text classification, another metric can be used, such as the overlap metric (or Hamming distance). In the context of gene expression microarray data, for example,
-NN has been employed with correlation coefficients, such as Pearson and Spearman, as a metric. Often, the classification accuracy of
-NN can be improved significantly if the distance metric is learned with specialized algorithms such as Large Margin Nearest Neighbor or Neighbourhood components analysis.
一般情况下,将欧氏距离作为距离度量,但是这只适用于连续变量。在文本分类这种离散变量情况下,另一个度量重叠度量 (汉明距离) 可以用来作为度量。例如对于基因表达微阵列数据,
-NN 也与 Pearson 和 Spearman 相关系数结合起来使用。通常情况下,如果运用一些特殊的算法来计算度量的话,
近邻分类精度可显著提高,如运用大间隔最近邻居或者邻里成分分析法。
gene expression:基因表达,基因表现
microarray [,maikrəuə'rei]:n. 微阵列,微阵列芯片
A drawback of the basic majority voting classification occurs when the class distribution is skewed. That is, examples of a more frequent class tend to dominate the prediction of the new example, because they tend to be common among the
nearest neighbors due to their large number. One way to overcome this problem is to weight the classification, taking into account the distance from the test point to each of its
nearest neighbors. The class (or value, in regression problems) of each of the
nearest points is multiplied by a weight proportional to the inverse of the distance from that point to the test point. Another way to overcome skew is by abstraction in data representation. For example, in a self-organizing map (SOM), each node is a representative (a center) of a cluster of similar points, regardless of their density in the original training data.
-NN can then be applied to the SOM.
多数表决分类会在类别分布偏斜时出现缺陷。出现频率较多的样本将会主导测试点的预测结果,因为他们比较大可能出现在测试点的
邻域而测试点的属性又是通过
邻域内的样本计算出来的。解决这个缺点的方法之一是在进行分类时将样本到
个近邻点的距离考虑进去。
近邻点中每一个的分类 (对于回归问题来说,是数值) 都乘以与测试点之间距离的成反比的权重。另一种克服偏斜的方式是通过数据表示形式的抽象。例如,在自组织映射 (SOM) 中,每个节点是相似的点的一个集群的代表 (中心),而与它们在原始训练数据的密度无关。
-NN 可以应用到 SOM 中。
majority [mə'dʒɒrɪtɪ]:n. 多数,成年
skew [skjuː]:n. 斜交,歪斜 adj. 斜交的,歪斜的 vt. 使歪斜 vi. 偏离,歪斜,斜视
dominate ['dɒmɪneɪt]:vt. 控制,支配,占优势,在...中占主要地位 vi. 占优势,处于支配地位
proportional [prə'pɔːʃ(ə)n(ə)l]:adj. 比例的,成比例的,相称的,均衡的 n. 比例项
inverse ['ɪnvɜːs; ɪn'vɜːs]:n. 相反,倒转 adj. 相反的,倒转的
Parameter selection - 参数选择
The best choice of
depends upon the data; generally, larger values of
reduces effect of the noise on the classification, but make boundaries between classes less distinct. A good
can be selected by various heuristic techniques (see hyperparameter optimization). The special case where the class is predicted to be the class of the closest training sample (i.e. when
= 1) is called the nearest neighbor algorithm.
如何选择一个最佳的
值取决于数据。一般情况下,在分类时较大的
值能够减小噪声的影响,但会使类别之间的界限变得模糊。一个较好的
值能通过各种启发式技术来获取。
heuristic [,hjʊ(ə)'rɪstɪk];adj. 启发式的,探索的 n. 启发式教育法
distinct [dɪ'stɪŋ(k)t]:adj. 明显的,独特的,清楚的,有区别的
optimization [,ɒptɪmaɪ'zeɪʃən]:n. 最佳化,最优化
special ['speʃ(ə)l]:n. 特使,特派人员,特刊,特色菜,专车,特价商品 adj. 特别的,专门的,专用的
The accuracy of the
-NN algorithm can be severely degraded by the presence of noisy or irrelevant features, or if the feature scales are not consistent with their importance. Much research effort has been put into selecting or scaling features to improve classification. A particularly popular approach is the use of evolutionary algorithms to optimize feature scaling. Another popular approach is to scale features by the mutual information of the training data with the training classes.
噪声和非相关性特征的存在,或特征尺度与它们的重要性不一致会使
近邻算法的准确性严重降低。对于选取和缩放特征来改善分类已经作了很多研究。一个普遍的做法是利用进化算法优化功能扩展,还有一种较普遍的方法是利用训练样本的互信息进行选择特征。
presence ['prez(ə)ns]:n. 存在,出席,参加,风度,仪态
irrelevant [ɪ'relɪv(ə)nt]:adj. 不相干的,不切题的
evolutionary [ˌeːvə'luːʃənərɪ]:adj. 进化的,发展的,渐进的
mutual ['mjuːtʃʊəl; -tjʊəl]:adj. 共同的,相互的,彼此的
particularly [pə'tɪkjʊləlɪ]:adv. 特别地,独特地,详细地,具体地,明确地,细致地
In binary (two class) classification problems, it is helpful to choose
to be an odd number as this avoids tied votes. One popular way of choosing the empirically optimal
in this setting is via bootstrap method.
在二元 (两类) 分类问题中,选取
为奇数有助于避免两个分类平票情形。在此问题下,选取最佳经验
值的方法是自助法。
vote [vəʊt]:n. 投票,选举,选票,得票数 vt. 提议,使投票,投票决定,公认 vi. 选举,投票
Decision boundary - 决策边界
Nearest neighbor rules in effect implicitly compute the decision boundary. It is also possible to compute the decision boundary explicitly, and to do so efficiently, so that the computational complexity is a function of the boundary complexity.
近邻算法能用一种有效的方式隐含的计算决策边界。另外,它也可以显式的计算决策边界,以及有效率的这样做计算,使得计算复杂度是边界复杂度的函数。
implicitly [ɪm'plɪsɪtlɪ]:adv. 含蓄地,暗中地
explicitly [ɪk'splɪsɪtli]:adv. 明确地,明白地
Metric learning
The
-nearest neighbor classification performance can often be significantly improved through (supervised) metric learning. Popular algorithms are neighbourhood components analysis and large margin nearest neighbor. Supervised metric learning algorithms use the label information to learn a new metric or pseudo-metric.
通过 (监督的) 度量学习,通常可以显着改善
最近邻分类性能。流行的算法是邻域成分分析和大边距最近邻。监督度量学习算法使用标签信息来学习新度量或伪度量。
pseudo ['sjuːdəʊ]:n. 伪君子,假冒的人 adj. 冒充的,假的
metric ['metrɪk]:adj. 公制的,米制的,公尺的 n. 度量标准
Data reduction
Data reduction is one of the most important problems for work with huge data sets. Usually, only some of the data points are needed for accurate classification. Those data are called the prototypes and can be found as follows:
数据减少是处理大量数据集的最重要问题之一。通常,只需要一些数据点来进行准确分类。这些数据称为原型,可以通过以下方式找到:
-
Select the class-outliers, that is, training data that are classified incorrectly by -NN (for a given )
-
Separate the rest of the data into two sets: (i) the prototypes that are used for the classification decisions and (ii) the absorbed points that can be correctly classified by -NN using prototypes. The absorbed points can then be removed from the training set.
-
选择类异常值,即训练数据被 -NN 错误分类 (对于给定的 )。
-
将其余数据分成两组:(i) 用于分类决策的原型和 (ii) 可以使用原型通过 -NN 正确分类的吸收点。然后可以从训练集中移除吸收的点。
prototypes ['prəutətaip]:n. 原型,技术原型,雏型
absorb [əb'zɔːb; -'sɔːb]:vt. 吸收,吸引,承受,理解,使...全神贯注
outlier ['aʊtlaɪə]:n. 异常值,露宿者,局外人,离开本体的部分
Properties - 属性
The naive version of the algorithm is easy to implement by computing the distances from the test example to all stored examples, but it is computationally intensive for large training sets. Using an approximate nearest neighbor search algorithm makes
-NN computationally tractable even for large data sets. Many nearest neighbor search algorithms have been proposed over the years; these generally seek to reduce the number of distance evaluations actually performed.
原始朴素的算法通过计算测试点到存储样本点的距离是比较容易实现的,但它属于计算密集型的,特别是当训练样本集变大时,计算量也会跟着增大。多年来,许多用来减少不必要距离评价的近邻搜索算法已经被提出来。使用一种合适的近邻搜索算法能使
近邻算法的计算变得简单许多。
-NN has some strong consistency results. As the amount of data approaches infinity, the two-class
-NN algorithm is guaranteed to yield an error rate no worse than twice the Bayes error rate (the minimum achievable error rate given the distribution of the data). Various improvements to the
-NN speed are possible by using proximity graphs.
近邻算法具有较强的一致性结果。随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍。对于一些
值,
近邻保证错误率不会超过贝叶斯的。
tractable ['træktəb(ə)l]:adj. 易于管教的,易驾驭的,易处理的,驯良的
consistency [kən'sɪst(ə)nsɪ]:n. 一致性,稠度,相容性
infinity [ɪn'fɪnɪtɪ]:n. 无穷,无限大,无限距
naive [naɪ'iːv; nɑː'iːv]:adj. 天真的,幼稚的
Feature extraction
When the input data to an algorithm is too large to be processed and it is suspected to be redundant (e.g. the same measurement in both feet and meters) then the input data will be transformed into a reduced representation set of features (also named features vector). Transforming the input data into the set of features is called feature extraction. If the features extracted are carefully chosen it is expected that the features set will extract the relevant information from the input data in order to perform the desired task using this reduced representation instead of the full size input. Feature extraction is performed on raw data prior to applying
-NN algorithm on the transformed data in feature space.
当算法的输入数据太大而无法处理并且怀疑它是冗余的 (例如,在英尺和米中都是相同的测量),那么输入数据将被转换为简化的表示集 (也称为特征向量)。将输入数据转换为特征集称为特征提取。如果仔细选择提取的特征,则期望特征集将从输入数据中提取相关信息,以便使用该缩减的表示而不是全尺寸输入来执行期望的任务。在对特征空间中的变换数据应用
-NN 算法之前,对原始数据执行特征提取。
suspect [ˈsʌspekt; (for v.) səˈspekt]:n. 嫌疑犯 adj. 可疑的,不可信的 vt. 怀疑,猜想 vi. 怀疑,猜想
An example of a typical computer vision computation pipeline for face recognition using -NN including feature extraction and dimension reduction pre-processing steps (usually implemented with OpenCV):
- Haar face detection
- Mean-shift tracking analysis
- PCA or Fisher LDA projection into feature space, followed by -NN classification
使用 -NN 进行人脸识别的典型计算机视觉计算流水线示例,包括特征提取和降维预处理步骤 (通常使用 OpenCV 实现)。
Dimension reduction
For high-dimensional data (e.g., with number of dimensions more than 10) dimension reduction is usually performed prior to applying the
-NN algorithm in order to avoid the effects of the curse of dimensionality.
对于高维数据 (例如,维度数大于 10),通常在应用
-NN 算法之前执行维度减少,以避免维数灾难的影响。
fisher ['fɪʃə]:n. 渔夫,渔船,食鱼貂
prior ['praɪə]:adj. 优先的,在先的,在前的 n. 小修道院院长,大修道院的副院长,会长,犯罪前科
equidistant [,iːkwɪ'dɪst(ə)nt; e-]:adj. 等距的,距离相等的
canonical [kə'nɒnɪk(ə)l]:adj. 依教规的,权威的,牧师的 n. 牧师礼服
The curse of dimensionality in the
-NN context basically means that Euclidean distance is unhelpful in high dimensions because all vectors are almost equidistant to the search query vector (imagine multiple points lying more or less on a circle with the query point at the center; the distance from the query to all data points in the search space is almost the same).
-NN 上下文中维数的诅咒基本上意味着欧几里德距离在高维度上是无用的,因为所有向量几乎与搜索查询向量等距 (想象多个点或多或少地位于圆上,查询点位于中心,查询到搜索空间中所有数据点的距离几乎相同。)
Feature extraction and dimension reduction can be combined in one step using principal component analysis (PCA), linear discriminant analysis (LDA), or canonical correlation analysis (CCA) techniques as a pre-processing step, followed by clustering by
-NN on feature vectors in reduced-dimension space. In machine learning this process is also called low-dimensional embedding.
使用主成分分析 (PCA),线性判别分析 (LDA) 或典型相关分析 (CCA )技术作为预处理步骤,然后通过
-NN 对特征进行聚类,可以在一个步骤中组合特征提取和降维,缩小空间中的向量。在机器学习中,这个过程也称为低维嵌入。
For very-high-dimensional datasets (e.g. when performing a similarity search on live video streams, DNA data or high-dimensional time series) running a fast approximate
-NN search using locality sensitive hashing, “random projections”, “sketches” or other high-dimensional similarity search techniques from the VLDB toolbox might be the only feasible option.
对于非常高维数据集 (例如当对实时视频流,DNA 数据或高维时间序列执行相似性搜索时) 使用局部敏感散列、随机投影、草图或运行快速近似
-NN 搜索 来自 VLDB 工具箱的其他高维相似性搜索技术可能是唯一可行的选择。
feasible ['fiːzɪb(ə)l]:adj. 可行的,可能的,可实行的
- Selection of class-outliers
- CNN for data reduction
The weighted nearest neighbour classifier - 加权最近邻分类器
The
-nearest neighbour classifier can be viewed as assigning the
nearest neighbours a weight
and all others 0 weight. This can be generalised to weighted nearest neighbour classifiers. That is, where the
th nearest neighbour is assigned a weight
, with
. An analogous result on the strong consistency of weighted nearest neighbour classifiers also holds.
-最近邻分类器可以被视为
最近邻居分配权重
以及为所有其他邻居分配 0 权重。这可以推广到加权最近邻分类器。也就是说,第
近的邻居被赋予权重
,其中
。关于加权最近邻分类器的强一致性的类似结果也成立。
analogous [ə'næləgəs]:adj. 类似的,同功的,可比拟的
generalise ['dʒenərəlaɪz]:vt. 概括,归纳,普及 vi. 推广,笼统地讲,概括 (等于 generalize)
The 1-nearest neighbor classifier
The most intuitive nearest neighbour type classifier is the one nearest neighbour classifier that assigns a point
to the class of its closest neighbour in the feature space, that is
.
最直观的最近邻类型分类器是
= 1 最近邻分类器,它将点
分配给特征空间中其最近邻居的类,即
。
As the size of training data set approaches infinity, the one nearest neighbour classifier guarantees an error rate of no worse than twice the Bayes error rate (the minimum achievable error rate given the distribution of the data).
随着训练数据集的大小接近无穷大,
= 1 最近邻分类器保证错误率不低于贝叶斯错误率的两倍 (给定数据分布的最小可实现错误率)。
intuitive [ɪn'tjuːɪtɪv]:adj. 直觉的,凭直觉获知的
Error rates
There are many results on the error rate of the
nearest neighbour classifiers. The
-nearest neighbour classifier is strongly (that is for any joint distribution on
) consistent provided
diverges and
converges to zero as
.
关于
个最近邻分类器的错误率有很多结果。
-最近邻分类器是强 (对于
上的任何联合分布) 一致地提供
发散并且
收敛为零作为
。
consistent [kən'sɪst(ə)nt]:adj. 始终如一的,一致的,坚持的
diverge [daɪ'vɜːdʒ; dɪ-]:vi. 分歧,偏离,分叉,离题 vt. 使偏离,使分叉
converge [kən'vɜːdʒ]:vt. 使汇聚 vi. 聚集,靠拢,收敛
-NN regression - -NN 回归
In -NN regression, the -NN algorithm is used for estimating continuous variables. One such algorithm uses a weighted average of the nearest neighbors, weighted by the inverse of their distance. This algorithm works as follows:
- Compute the Euclidean or Mahalanobis distance from the query example to the labeled examples.
- Order the labeled examples by increasing distance.
- Find a heuristically optimal number of nearest neighbors, based on RMSE. This is done using cross validation.
- Calculate an inverse distance weighted average with the -nearest multivariate neighbors.
在 -NN 回归中, -NN 算法用于估计连续变量。其中一种算法使用 最近邻的加权平均值,由它们距离的倒数加权。该算法的工作原理如下:
- 计算从查询示例到标记示例的 Euclidean or Mahalanobis distance。
- 通过增加距离来排序标记的示例。
- 基于 RMSE,找到最近邻的启发式最优数 。这是通过交叉验证完成的。
- 用 -最近的多变量邻域计算一个距离倒数加权平均值。
Mahalanobis distance:马氏距离,马哈拉诺比斯距离
heuristically:启发式地
-NN outlier - -NN 异常值
The distance to the
th nearest neighbor can also be seen as a local density estimate and thus is also a popular outlier score in anomaly detection. The larger the distance to the
-NN, the lower the local density, the more likely the query point is an outlier. To take into account the whole neighborhood of the query point, the average distance to the
-NN can be used. Although quite simple, this outlier model, along with another classic data mining method, local outlier factor, works quite well also in comparison to more recent and more complex approaches, according to a large scale experimental analysis.
到第
个最近邻的距离也可以看作是一个局部密度估计,因此也是异常检测中常见的离群值。到
-NN 的距离越大,局部密度越低,查询点越可能是离群值。为了考虑到查询点的整个邻域,可以使用到
-NN 的平均距离。根据大规模的实验分析,这种异常值模型和另一种经典的数据挖掘方法,即局部异常值因子,虽然很简单,但与较新和更复杂的方法相比,也能很好地工作。
popular ['pɒpjʊlə]:adj. 流行的,通俗的,受欢迎的,大众的,普及的
anomaly [ə'nɒm(ə)lɪ]:n. 异常,不规则,反常事物
Validation of results
A confusion matrix or matching matrix is often used as a tool to validate the accuracy of
-NN classification. More robust statistical methods such as likelihood-ratio test can also be applied.
混淆矩阵或匹配矩阵常被用作验证
-NN 分类精度的工具。也可以采用更为稳健的统计方法,如似然比检验。
confusion matrix:混淆矩阵
robust [rə(ʊ)'bʌst]:adj. 强健的,健康的,粗野的,粗鲁的
statistical [stə'tɪstɪk(ə)l]:adj. 统计的,统计学的
likelihood ['laɪklɪhʊd]:n. 可能性,可能
References
locality-sensitive hashing,LSH:局部敏感哈希
https://en.wikipedia.org/wiki/Locality-sensitive_hashing