MySQL学习之索引之争
其他
2019-04-25 09:11:01
阅读次数: 0
MySQL学习之索引之争
为什么要用索引?
- 使用索引后减少了存储引擎需要扫描的数据量,加快查询速度
- 索引可以把随机I/O变为顺序I/O
- 索引可以帮助我们对所搜结果进行排序以避免使用磁盘临时表
MySQL的索引常见的有Hash和B-Tree两种形式,两种索引类型应用场景根据其特性各有不同
一、hash类型的索引特征
- Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
- 虽然 Hash 索引效率高,但是 Hash索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
- Hash 索引仅仅能满足"=",“IN"和”<>"查询,不能使用范围查询。
- Hash 索引无法被用来避免数据的排序操作。
- Hash 索引不能利用部分索引键查询。
- Hash 索引在任何时候都不能避免表扫描。
- Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
二、B-Tree类型的索引特征
- B树是一种多路自平衡搜索树,它类似普通的二叉树,但是B树允许每个节点有更多的子节点。B树的示意图为:
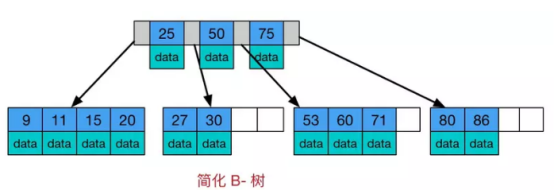
B树的特点:
- (1)所有键值分布在整个树中
- (2)任何关键字出现且只出现在一个节点中
- (3)搜索有可能在非叶子节点结束
- (4)在关键字全集内做一次查找,性能逼近二分查找算法
- B+树是B树的变体,也是一种多路平衡查找树,B+树的示意图为:

B+树与B树的不同在于:
- (1)所有关键字存储在叶子节点,非叶子节点不存储真正的data
- (2)为所有叶子节点增加了一个链指针
三、为什么mysql的索引使用B+树而不是B树呢?
- B+树更适合外部存储(一般指磁盘存储),由于内节点(非叶子节点)不存储data,所以一个节点可以存储更多的内节点,每个节点能索引的范围更大更精确。也就是说使用B+树单次磁盘IO的信息量相比较B树更大,IO效率更高。
- mysql是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以B+树对索引列上的区间范围查询很友好。而B树每个节点的key和data在一起,无法进行区间查找。
四、使用场景
B-TREE索引
B-TREE索引的特点
- B-TREEB-TREE以B+树结构存储数据,大大加快了数据的查询速度
- B-TREE索引在范围查找的SQL语句中更加适合(顺序存储)
B-TREE索引使用场景
- 全值匹配的查询SQL,如 where act_id= ‘1111_act’
- 联合索引汇中匹配到最左前缀查询,如联合索引 KEY idx_actid_name(act_id,act_name) USING BTREE,只要条件中使用到了联合索引的第一列,就会用到该索引,但如果查询使用到的是联合索引的第二列act_name,该SQL则便无法使用到该联合索引(注:覆盖索引除外)
- 匹配模糊查询的前匹配,如where act_name like ‘11_act%’
- 匹配范围值的SQL查询,如where act_date > ‘9865123547215’(not in和<>无法使用索引)
- 覆盖索引的SQL查询,就是说select出来的字段都建立了索引
HASH索引
HASH的特点
- Hash索引基于Hash表实现,只有查询条件精确匹配Hash索引中的所有列才会用到hash索引
- 存储引擎会为Hash索引中的每一列都计算hash码,Hash索引中存储的即hash码,所以每次读取都会进行两次查询
- Hash索引无法用于排序
- Hash不适用于区分度小的列上,如性别字段
转载自blog.csdn.net/hacker_Lees/article/details/85707841