
知识抽取与挖掘
本文是王昊奋老师《知识图谱》系列笔记第三篇。
文章目录
前一课,我们通过手工的方式 构建了一个小型的知识图谱。 但是我们其实更加希望能够通过一些算法或者工具能够自动化的从互联网大数据中抽取知识扩充三元组。
知识抽取,即从不同来源、不同结构的数据中进行知识提取,形成知识(结构化数据)存入到知识图谱。大体的任务分类与对应技术如下图所示:
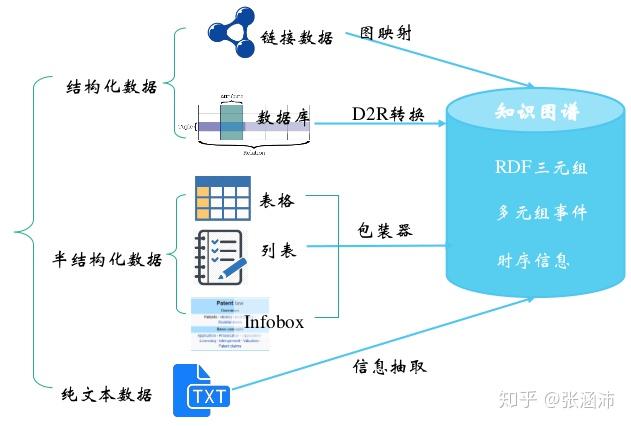
其中最重要的是非结构数据(纯文本)的抽取(第一章)
1. 知识抽取的概念and子任务(非结构化信息抽取)
非结构化信息抽取三个最重要/最受关注的子任务:
- 实体抽取
- 也就是命名实体识别,包括实体的检测(find)和分类(classify)
- 检测: 北京是忙碌的城市。 [北京]: 实体
- 分类:北京是忙碌的城市。 [北京]: 地名
- 关系抽取
- 通常我们说的三元组(triple) 抽取,一个谓词(predicate)带 2 个形参(argument),如 Founding-location(IBM,New York)
- 事件抽取
- 相当于一种多元关系的抽取
1.1 实体识别
本节知识包含太多内容(根本写不完),专门开一篇博客详细学习,相关算法与实验操作。《03.1 知识图谱 实体识别》
实体抽取或者说命名实体识别(NER)在信息抽取中扮演着重要角色,主要抽取的是文本中的原子信息元素,如人名、组织/机构名、地理位置、事件/日期、字符值、金额值等,具体的标签定义可根据任务不同而调整。实体抽取任务有两个关键词:find & classify,找到命名实体,并进行分类。

命名实体识别主要分类,一般包括 3 大类(实体类、时间类和数字类)和 7 小类(人名、地名、组织名、机构名、时间、日期、货币和百分比)。但随着 NLP 任务的不断扩充,在特定领域中会出现特定的类别,比如医药领域中,药名、疾病等类别。
1.1.1 实体识别其他应用
1.1.1.1 实体链接(共指消解 实体消歧)
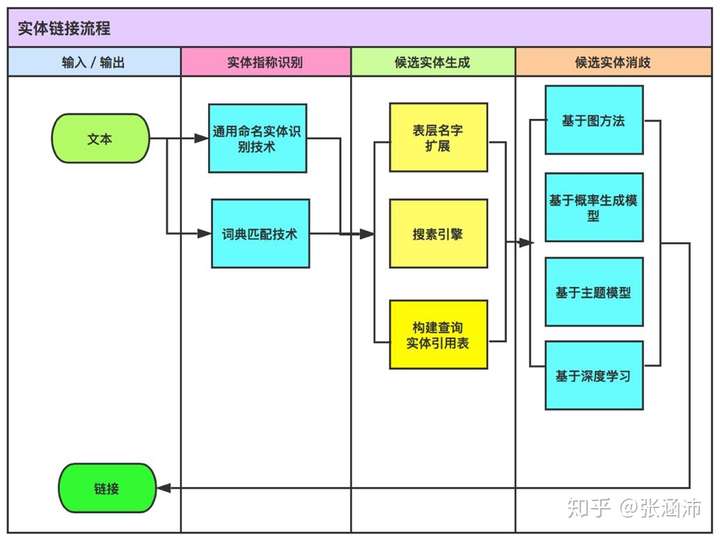
- 首先输入的是非结构化的文本数据,经由命名实体识别或词典匹配技术进行实体的指称识别。
- 由于刚刚识别出来的实体可能是实体的部分表示或另类表示,因此需要结束表层名字扩展、搜索引擎、构建查询实体引用表等技术来对候选实体进行生成。
- 经过该步骤生成的实体可能有多个候选项,因此需要对候选实体进行消岐,此处可使用基于图的方法、基于概率生成模型、基于主题模型或基于深度学习的方法。
- 经过实体消岐后得到的唯一实体候选后就可以与知识库中的实体进行连接了。
举个例子:
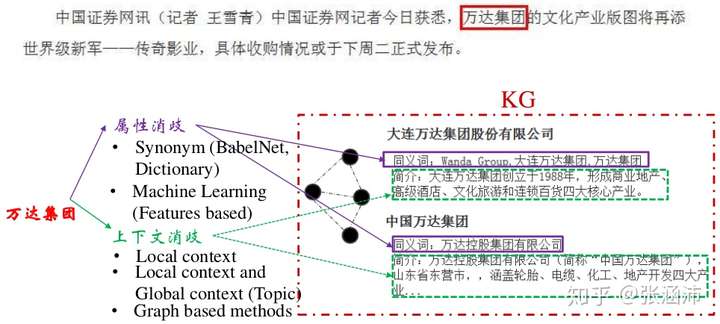
1.1.1.2 其他应用
- 命名实体作为索引和超链接
- 情感分析的准备步骤,在情感分析的文本中需要识别公司和产品,才能进一步为- 情感词归类
- 关系抽取(Relation Extraction)的准备步骤
- QA 系统,大多数答案都是命名实体
1.1.2 实体识别算法
1.1.2.1 方法一般流程
-
Training标准流程:
- 收集代表性的训练文档
- 为每个 token 标记命名实体(不属于任何实体就标 Others O)
- 设计适合该文本和类别的特征提取方法
- 训练一个 sequence classifier 来预测数据的 label
-
Testing标准流程:
- 收集测试文档
- 运行 sequence classifier 给每个 token 做标记
- 输出命名实体
1.1.2.2 编码方式
看一下最常用的两种 sequence labeling 的编码方式:IO encoding和IOB encoding
- IO encoding 简单的为每个 实体 标注为 实体标签(PER只是众多中的一个 代表人 person),如果不是 实体 就标为 O(other),所以一共需要 C+1 个类别(label)。
- 而 IOB encoding 需要 2C+1 个类别(label),B 代表 begining,表示实体 开始的位置,I 代表 continue,承接上一个 NE,如果连续出现两个 B,自然就表示上一个 B 已经结束了。

在 Stanford NER 里,用的其实是 IO encoding,有两个原因:
- 一是 IO encoding 运行速度更快,
- 二是在实践中,两种编码方式的效果差不多。
IO encoding 确定 boundary 的依据是,如果有连续的 token 类别不为 O,那么类别相同,同属一个 NE;类别不相同,就分割,相同的 sequence 属同一个 NE。而实际上,两个 NE 是相同类别这样的现象出现的很少,如上面的例子,Sue,Mengqiu Huang 两个同是 PER 类别,并不多见,更重要的是,在实践中,虽然 IOB encoding 能规定 boundary,而实际上它也很少能做对,它也会把 Sue Mengqiu Huang 分为同一个 PER,这主要是因为更多的类别会带来数据的稀疏。
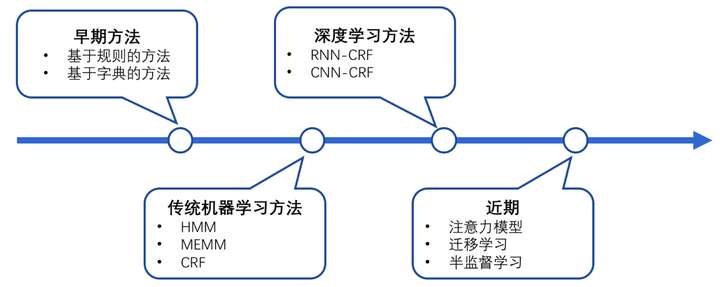
1.1.2.4 机器学习算法
NER一直是NLP领域中的研究热点,从早期基于词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER研究进展的大概趋势大致如下图所示。
NLP 的很多数据都是序列类型,需要使用序列模型解决。像 sequence of characters, words, phrases, lines, sentences,我们可以把这些任务当做是给每一个 item 打标签,如下图:

- 常见的序列模型有 有向图模型 如 HMM,假设特征之间相互独立,找到使得 P(X,Y) 最大的参数,属于生成式模型;
- 无向图模型 如 CRF,没有特征独立的假设,找到使得 P(Y|X) 最大的参数,判别式模型。
1.1.2.5 实验1:用CRF做实体识别实验。
本节知识包含太多内容(根本写不完),专门开一篇博客详细学习,相关算法与实验操作。《03.1 知识图谱 实体识别》
1.1.2.6 深度学习方法
NER 中模型发展的历史:有一些,大致如下:MLP->LSTM->LSTM/CNN+CRF->BiLSTM+CRF- >BiLSTM+CNN+CRF。
本节知识包含太多内容(根本写不完),专门开一篇博客详细学习,相关算法与实验操作。《03.1 知识图谱 实体识别》
1.2 关系抽取
关系抽取是从文本中抽取出两个或多个实体之间的语义关系。它是信息抽取研究领域的任务之一。如:
王健林谈儿子王思聪:我期望他稳重一点。
-> 父子关系 (王健林, 王思聪)
关系抽取 主要方法有下面几类:
- 基于模板的方法(hand-written patterns)
- 基于触发词/字符串
2.基于依存句法
- 基于触发词/字符串
- 监督学习(supervised machine learning)
- 机器学习
- 深度学习(Pipeline vs Joint Model)
- 半监督/无监督学习(semi-supervised and unsupervised)
- Bootstrapping
- Distant supervision
- Unsupervised learning from the web
1.2.1 基于模板的方法
基于模板的方法在小规模数据集上容易实现且构建简单,缺点为难以维护、可移植性差、模板有可能需要专家构建。
1.2.1.1 基于触发词的Pattern
首先定义一套种子模板,如:

其中的触发词为老婆、妻子、配偶等。根据这些触发词找出夫妻关系这种关系,同时通过命名实体识别给出关系的参与方。
1.2.1.2 基于依存分析的Pattern
以动词为起点,构建规则,对节点上的词性和边上的依存关系进行限定。一般情况下是形容词+名字或动宾短语等情况,因此相当于以动词为中心结构做的Pattern。其执行流程为:
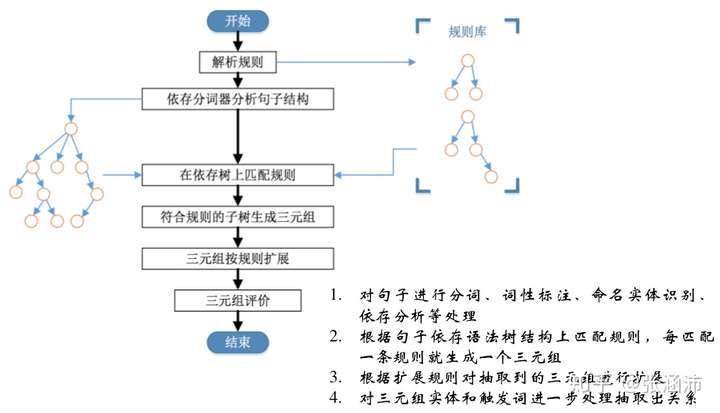
1.2.2 监督学习
在给定实体对的情况下,根据句子上下文对实体关系进行预测,执行流程为:
- 预先定义好关系的类别。
- 人工标注一些数据。
- 设计特征表示。
- 选择一个分类方法。(SVM、NN、朴素贝叶斯)
- 评估方法。
其优点为准确率高,标注的数据越多越准确。缺点为标注数据的成本太高,不能扩展新的关系。
监督学习关系抽取有两种模式:管道模型Pipeline model和联合模型joint model。
- 管道模型Pipeline model(一环接一环)
即识别实体和关系分类是完全分离的两个过程,不会相互影响,关系的识别依赖于实体识别的效果,这样的好处的各模型相互独立,设计上较为容易,但误差会逐层传递,步骤太多有可能导致后续不可用。
- 联合模型joint model
将实体识别和关系分类一起做,在一个模型中完成。

如上图论文中,识别“出生地关系 born in ” 把实体识别模型(biLSTM+CRF)与关系抽取模型(树形依存关系LSTM) 一起训练,缺点是参数多训练慢,优势是精度高。
1.2.3 非监督学习
前面的监督学习效果虽好,但有标注数据集的获取困难。因此可以借助半监督学习的方法,此处又分为远程监督学习和Bootstrapping方法两种。
- 所谓远程监督方法就是知识库与非结构化文本对齐来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应能力。
- Bootstrapping是通过在文本中匹配实体对和表达关系短语模式,寻找和发现新的潜在关系三元组。
1.2.3.1 远程监督
远程监督流程为:
- 从知识库中抽取存在关系的实体对。
- 从非结构化文本中抽取含有实体对的句子作为训练样例。
该方法认为若两个实体如果在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。例子如下:
现在 有一条纯文本“乔布斯是苹果公司的联合创始人和CEO”我们没有任何标签;
但是在我们的知识库中存在“创始人(乔布斯,苹果公司)”这样一条规则。
那么就认为出现乔布斯和苹果公司的句子就是表述创始人这项关系。
因此可构建训练正例:“乔布斯是苹果公司的联合创始人和CEO”。 的分类标签为“创始人”。
远程监督可以利用丰富的知识库信息,减少一定的人工标注,但它的假设过于肯定,如乔布斯被赶出苹果公司。这句话表达的就不是创始人的例子,因此会引入大量的噪声,存在语义漂移现象。同时由于是在知识库中抽取存在的实体关系对,因此很难发现新的关系。
1.2.3.2 Bootstrapping
不手写模版 而是学习模版:利用已知的“关系”所拥有的模版,去搜索新的模版。
这个方法在很多任务中都有提到,其执行流程为:
- 我们知道《姚明,叶莉》为“夫妻”关系。第一步从文档中抽取出所有包含种子实体(姚明叶莉)的新闻,并将实体置换为placehold:
- 姚明老婆 叶莉 简历身高曝光
- X 老婆 Y 简历身高曝光
- 姚明 与妻子 叶莉 外出赴约
- X 与妻子 Y 外出赴约
- 在剩下的文档中检索 所有满足上面第二和第四模式的句子,比如,我们找到了《小猪,伊万》也是“夫妻”关系。
- 小猪 与妻子 伊万 外出赴约
- 根据Pattern抽取出的新文档种子实体(找出所有 同时包括小猪伊万 的句子),迭代多轮直到不符合条件。
该方法的优点为构建成本低,适合大规模的构建,同时还可以发现新的(隐含的)关系。缺点为对初始给定的种子集敏感,存在语义漂移现象,结果的准确率较低等。
1.3 事件抽取
从自然语言中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与者等。如:
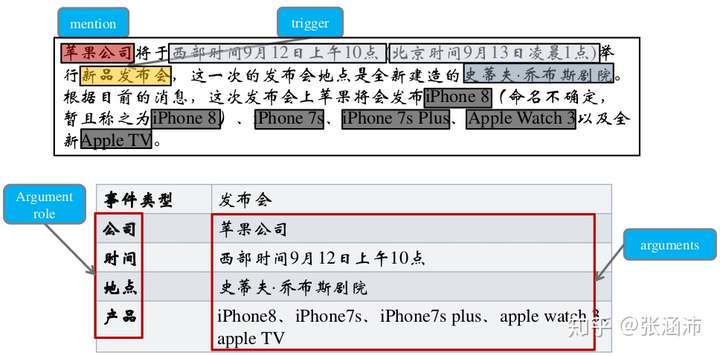
事件抽取任务最基础的部分包括:
- 识别事件触发词trigger及事件类型 type
- 抽取事件元素event argument 同时判断其角色role
- 抽出描述事件的词组或句子
此外,事件抽取任务还包括:
- 事件属性标注
- 事件共指消解
对于事件抽取,也可分为Pipeline方法和联合训练的方法。
1.3.1 管道模型Pipeline model(一环接一环)
有监督的事件抽取方法的标准流程一种pipeline的方法,将事件抽取任务转化为多阶段的分类问题,需要的分类器包括:
- 事件触发次分类器(Trigger Classifier)
- 用于判断词汇是否是是事件触发词,以及事件的类别
- 元素分类器(Argument Classifier)
- 判别词组是否是事件的元素
- 元素角色分类器(Role Classifier)
- 判定元素的角色类别
- 属性分类器(attribute classifier)
- 判定事件的属性
- 可报告性分类器(Reportable-Event Classifier)
- 判定是否存在值得报告的事件实例
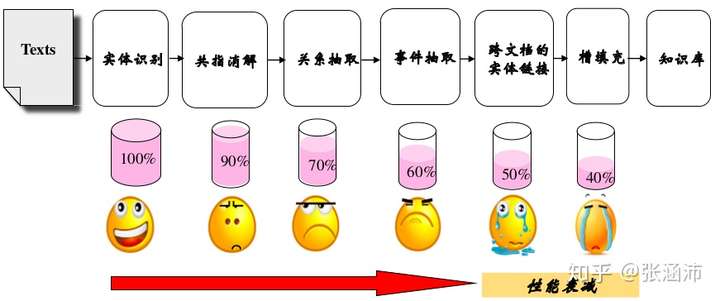
可以看到,这个流程还是蛮长的,因此Pipeline存在的误差传递问题在这里格外严重,因此我们需要联合训练:
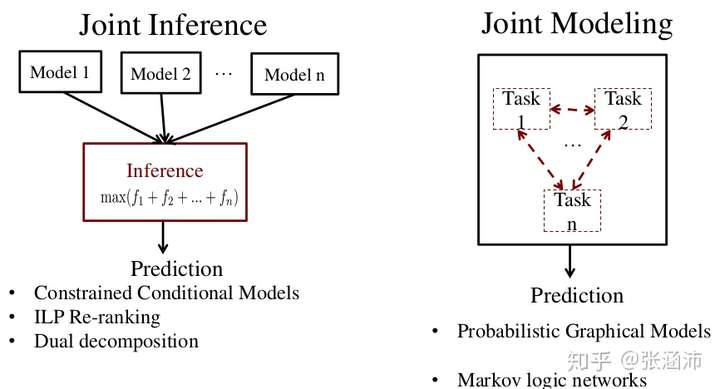
1.3.2 联合模型joint model
- 使用一个模型同时抽取所有新的联合。
- 将问题建模成结构预测问题,使用搜索方法进行求解。
- 避免了误差传播导致的性能下降
- 全局特征可以从整体结构中学习得到,从而使用全局信息量提升局部预测。
2. 结构化数据的知识抽取
所谓结构化数据就是指类似于关系库中表格那种形式的数据,他们往往各项之间存在明确的关系名称和对应关系。
因此我们可以简单的将其转化为RDF或其他形式的知识库内容。
一种常用的W3C推荐的映射语言是R2RML(RDB2RDF)。一种映射结果如下图所示:

现有的工具免费的有D2R,Virtuoso、MOrph等。
3. 半结构化数据的知识抽取
半结构化数据是指类似于百科、商品列表等那种本身存在一定结构但需要进一步提取整理的数据。
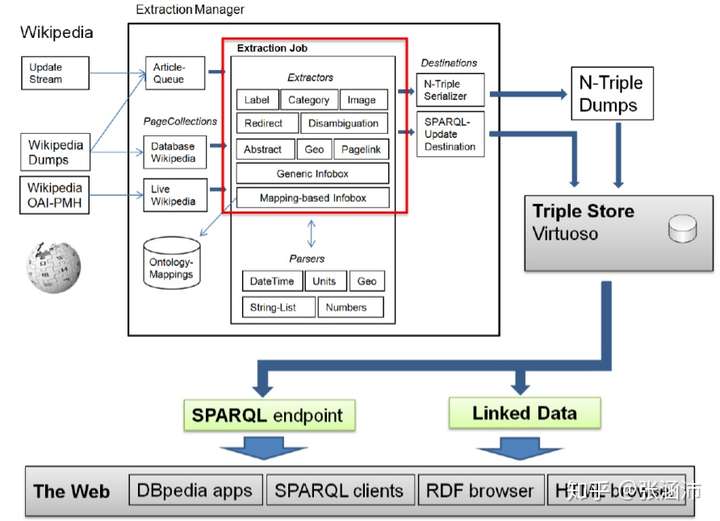
3.1 百科类知识抽取
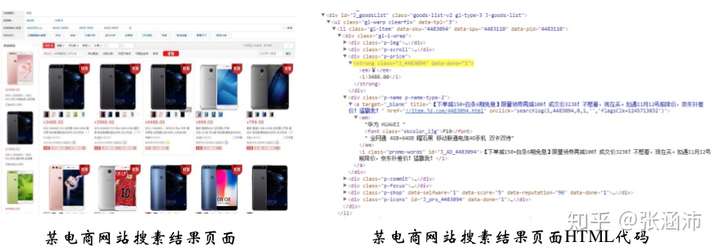
3.2 Web网页数据抽取:包装器生成
现在我们的目标网站是部分结构化的,如:
包装器是一个能够将数据从HTML网页中抽取出来,并且将它们还原为结构化的数据的软件程序(爬虫)。使用它提取信息流程为:
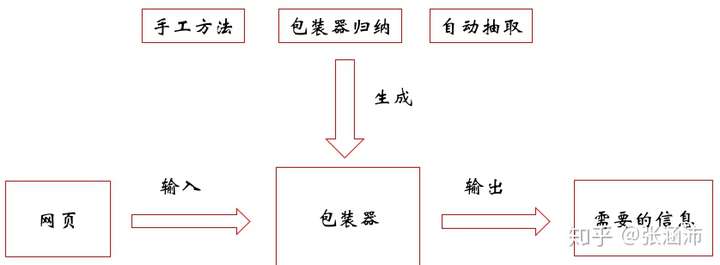
对于一般的有规律的页面,我们可以使用正则表达式的方式写出XPath和CSS选择器表达式来提取网页中的元素。但这样的通用性很差,因此也可以通过包装器归纳这种基于有监督学习的方法,自动的从标注好的训练样例集合中学习数据抽取规则,用于从其他相同标记或相同网页模板抽取目标数据。
对于监督学习我们知道标注数据是它的短板,因此我们想到自动抽取的方法。网站中的数据通常是用很少的一些模板来编码的,通过挖掘多个数据记录中的重复模式来寻找这些模板是可能的。