一、多线程的创建
import threading
import time
def say_hi(n):
time.sleep(0.2)
print('running on number', n)
if __name__ == "__main__":
start_time = time.time()
for i in range(10):
t = threading.Thread(target=say_hi, args=(i,))
t.start()
while threading.active_count() != 1:
pass
stop_time = time.time()
print('the sum time:%s' % (stop_time-start_time))
python中的多线程:首先导入threading,再通过Thread()方法创建一个子线程。通过start()方法启动线程。上面代码中创建了10个子线程。然后计算了所消费的时间。threading.active_count()是计算当前线程的个数,代码中当只剩中下主线程的时候,退出循环。
二、继承式的创建多线程方式
import threading
class MyThread(threading.Thread):
def __init__(self, num):
threading.Thread.__init__(self)
self.num = num
def run(self):
print('running on number:%s'%self.num)
if __name__ == '__main__':
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
继承式的多线程调用,这里的t1.start()是调用类里面的run方法。
三、多线程中的join方法
import threading
import time
def run(num, sleep_time):
print('task:%s is starting..' % num)
time.sleep(sleep_time)
print('task:%s is done' % num)
def main():
t1 = threading.Thread(target=run, args=(1, 2))
t2 = threading.Thread(target=run, args=(2, 3))
t1.start()
t2.start()
t1.join() #等待t1线程执行完毕。
print('main thread')
if __name__ == '__main__':
main()
# 执行结果
# task:1 is starting..
# task:2 is starting..
# task:1 is done
# main thread
# task:2 is done
这里可以看出两个重点:一是t1.join()指等待t1线程执行完毕才能执行其他线程。二是,只有当子线程完全执行完毕时,程序都会退出。所以当主线程执行完成,并没有退出程序,而是等待所有的子线程执行完成。
四、守护线程setDeamo
三中说到多线程中:不管主线程有没有执行完毕,只有当所有的线程退出时,程序才退出。那能不能让主线程执行完成,就退出程序,子线程不管有没有执行完成都会随主线程退出而退出。就好像子线程是主线程的守护者一样。主线程死了,所有的守护子线程不管阳寿有没有尽都要陪葬。
import threading
import time
def run():
for i in range(5):
print('test', i)
time.sleep(0.5)
if __name__ == '__main__':
t = threading.Thread(target=run, args=())
t.setDaemon(True)
t.start()
print('main thread')
# 执行结果:
# test 0
# main thread
方法就是将子线程调用setDeamo(True)方法,将它设为主线程的守护线程。
五、多线程的共享数据。
在同一个进程中,主线程创建出的所有子线程的数据都是可以共享的。下面的代码展示多个子线程同时修改主线程的全局变量。
from multiprocessing import Process
import threading
import time
num = 100
def fun1():
global num
for i in range(5):
num += 1
def fun2():
global num
print('num:%s' % num)
if __name__ == '__main__':
# t = threading.Thread(target=fun1)
# t.start()
# time.sleep(1)
# t2 = threading.Thread(target=fun2)
# t2.start()
p = Process(target=fun1)
p.start()
time.sleep(1)
p2 = Process(target=fun2)
p2.start()
# 执行结果:
#若为多线程执行,则为:num:105
#若为多进程执行,则为:num:100
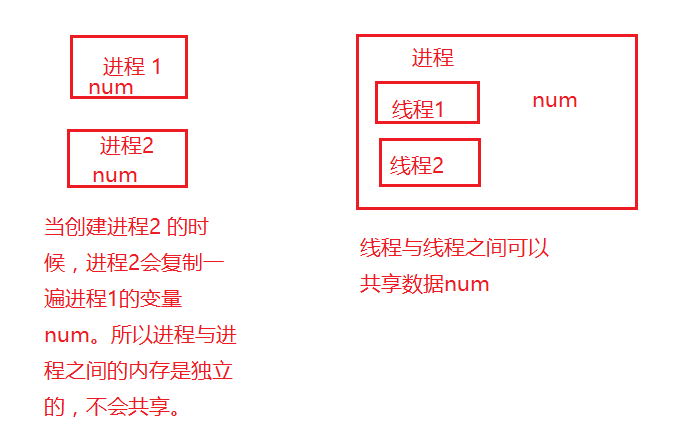
这里体现了多线程与多进程的一个区别,假如一个主进程产生了5个子进程,5个进程的资源是独立的,不会分享的,即进程不会共享内存,各自独立。假如一个主线程产生5个子线程,线程之间可以共享内存,资源共享。
六、多线程利用共享数据修改全局变量造成的混乱。
import threading
import time
num = 0
def fun1():
global num
for i in range(1000000):
num += 1
print('fun1---num:%s' % num)
def fun2():
global num
for i in range(1000000):
num += 1
print('fun2---num:%s' % num)
if __name__ == '__main__':
t1 = threading.Thread(target=fun1)
t2 = threading.Thread(target=fun2)
t1.start()
time.sleep(2)
t2.start()
print('main thread---num:%s' % num)
#执行结果:
# fun1---num:1000000
# main thread---num:1047944
# fun2---num:2000000
上面代码中启动了fun1,fun2线程修改全局变量。t1线程先执行,然后主线程睡了2秒,再启动t2线程。最后num为2000000,是正确的结果。那么如果主线程不睡2秒。两个线程同时修改执行,会出现什么情况呢?会不会造成修改混乱呢?好,我们把sleep去除。
import threading
import time
num = 0
def fun1():
global num
for i in range(1000000):
num += 1
print('fun1---num:%s' % num)
def fun2():
global num
for i in range(1000000):
num += 1
print('fun2---num:%s' % num)
if __name__ == '__main__':
t1 = threading.Thread(target=fun1)
t2 = threading.Thread(target=fun2)
t1.start()
#time.sleep(2)
t2.start()
print('main thread---num:%s' % num)
#执行结果:
# main thread---num:323562
# fun1---num:1312655
# fun2---num:1345219
上面的代码执行结果表明,最后的num不是2000000,说明两个线程之间争斗的改数据造成了混乱。
七、多线程利用共享数据修改全局变量造成的混乱的原因探索
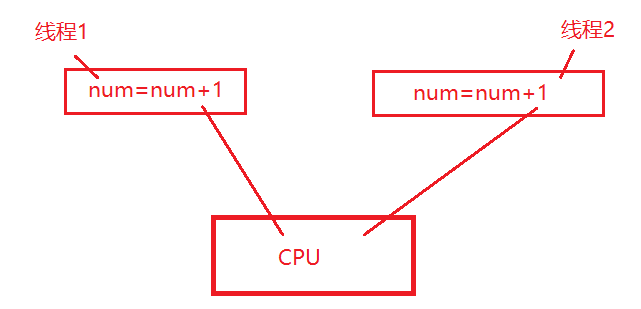
我们知道python中的多线程,CPU是通过上下文切换来执行的,由
于执行的快,给我们造成了两个线程同时执行的假象。如图,线程1若要修改num成功,要完成num+1计算以及将计算后的结果赋值给num两个步骤。假如num初始为0,CPU在执行线程1,在执行完num+1计算得1后就切换到执行线程二中去了,然后线程二执行完num+1的计算得1结果后又切换到线程1中执行赋值num=1,然后又切换到线程2中执行赋值num=1。可以看出,CPU已经执行完线程1,线程2了。结果num=1,而不是num=2。从而造成了混乱。
八、多线程利用共享数据修改全局变量造成的混乱的解决办法
我们可双利用threading中的Lock()模块,即互斥锁来解决这个问题。每当CPU要执行一个变量的修改操作时,我们会给它上锁,其他线程只能干等着。
import threading
num = 0
def fun1():
global num
for i in range(1000000):
mutex.acquire()
num += 1
mutex.release()
print('fun1---num:%s' % num)
def fun2():
global num
for i in range(1000000):
mutex.acquire()
num += 1
mutex.release()
print('fun2---num:%s' % num)
if __name__ == '__main__':
mutex = threading.Lock()
t1 = threading.Thread(target=fun1)
t2 = threading.Thread(target=fun2)
t1.start()
t2.start()
print('main thread---num:%s' % num)
#执行结果:
# main thread---num:80412
# fun2---num:1855919
# fun1---num:2000000
首先threading定义了一把锁mutex。当执行到fun2中的mutex.acquire()时,可以上锁,继续走。另一个线程执行到mutex.acquire()时,发现fun2已经给其上锁,于是它就阻塞等待其解锁再上锁。
总的来说,当定义锁mutex的时候,可以用mutex.acquire()来给它上锁,那么其他有mutex.acquire的方法会阻塞等待。只有当mutex.release()来打开锁之后才能重新上锁。
九、互斥锁造成的死锁问题
当我们在定义了多把锁的时候,就可能不小心造死锁的问题。死锁的情况如下:
import threading
import time
def fun1():
if mutexA.acquire():
print('fun1 is working')
time.sleep(1)
if mutexB.acquire():
print('fun1 is working')
mutexB.release()
mutexA.release()
def fun2():
if mutexB.acquire():
print('fun2 is working')
time.sleep(1)
if mutexA.acquire():
print('fun2 is working')
mutexA.release()
mutexB.release()
mutexA = threading.Lock()
mutexB = threading.Lock()
if __name__ == '__main__':
t1 = threading.Thread(target=fun1)
t2 = threading.Thread(target=fun2)
t1.start()
t2.start()
#执行结果
# fun1 is working
# fun2 is working
在代码中,A、B两把锁都在等待对方解锁,因此才造成死锁的问题。
十、生产者与消费者模型
当一个线程生产,另一个线程消费的时候,如果生产能力和消费能力不协调的情况下,可以用队列Queue来解决这种情况。
Queue的说明:
1、对于Queue,在多线程通信之间扮演重要的角色
2、添加数据到队列中,使用put()方法
3、从队列中取数据,使用get()方法
4、判断队列中是否还有数据,使用qsize()方法
from queue import Queue
import time
import threading
def produce():
while True:
if q.qsize()<1000:
for i in range(100):
msg = '生成产品'+str(i)
q.put(msg)
print(msg)
time.sleep(0.5)
def consume():
while True:
if q.qsize()>100:
for i in range(3):
msg = '消费产品'+q.get()
print(msg)
time.sleep(0.5)
if __name__ == '__main__':
q = Queue()
for i in range(500):
q.put('初始产品'+str(i))
for i in range(2):
t = threading.Thread(target=produce)
t.start()
for i in range(5):
t = threading.Thread(target=consume)
t.start()
代码中有初始产品500个,每个生产者生产100个产品休息0.5秒,每个消费者消费3个产品休息0.5秒。有2个生产者,5个消费者。
十一、线程总结:
python中的多线程是通过上下文切换来实现的。多线程之间是可以共享数据的,但是也会发生竞争混乱的情况,于是我们可以给它加锁,当锁加多了,就要注意死锁的问题了。若要协调两个线程之间的速度的时候,可以用Queue来缓冲。