偶然在网上看到一篇文章,讲到数据汇总,提到了CUBE,感觉有些晦涩,想试着自己表述一下。同时,个人也认为CUBE还是很有用的,对SQL或数据分析感兴趣的小伙伴不妨了解一下,或许有用呢!
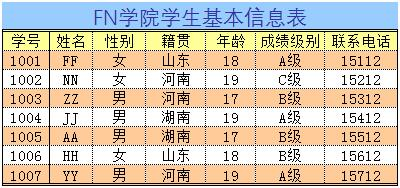
先设定个需求,想要分别按【性别】、【籍贯】、【年龄】或【成绩级别】统计下表中学生的数量,再进一步,需要将这些条件相结合统计,同时满足某两项或更多条件的学生数量。数据表格如下:
我们可以逐层来理解【GROUP BY】【WITH ROLLUP】【WITH CUBE】如何来完成数据汇总
第一层:【GROUP BY】
【GROUP BY】从字面意义上理解就是根据【BY】指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。可以先利用【GROUP BY】按条件进行分组,然后计算各组的数量。看个例子。
按学生性别统计学生的数量:
SQL语句如下:
1 SELECT 性别, COUNT(学号) AS 数量 2 FROM STUDENT 3 GROUP BY 性别
执行结果如下:

结果分析:可以看出,已经按性别顺利统计出“男”、“女”各占的数量,但这距离事先的需求(要统计多个条件,甚至是多条件组合下的学生数量的小计以及合计)差距有点远,【GROUP BY】还是有点弱。
第二层:【GROUP BY】+【WITH ROLLUP】
为【GROUP BY】加上【WITH ROLLUP】子句,看ROLLUP能不能提供更多的统计结果。前面说到多条件,其实说多维度更准确些。看个例子先:
SQL语句如下:
1 --语句只用了【性别】一个维度进行汇总 2 SELECT 性别, COUNT(学号) AS 数量 3 FROM STUDENT 4 GROUP BY 性别 WITH ROLLUP 5 6 --语句用了【性别】和【籍贯】两个维度进行汇总 7 SELECT 性别, 籍贯, COUNT(学号) AS 数量 8 FROM STUDENT 9 GROUP BY 性别, 籍贯 WITH ROLLUP 10 11 --语句用了【性别】、【籍贯】、【年龄】三个维度进行汇总 12 SELECT 性别, 籍贯, 年龄, COUNT(学号) AS 数量 13 FROM STUDENT 14 GROUP BY 性别, 籍贯, 年龄 WITH ROLLUP
执行结果如下:
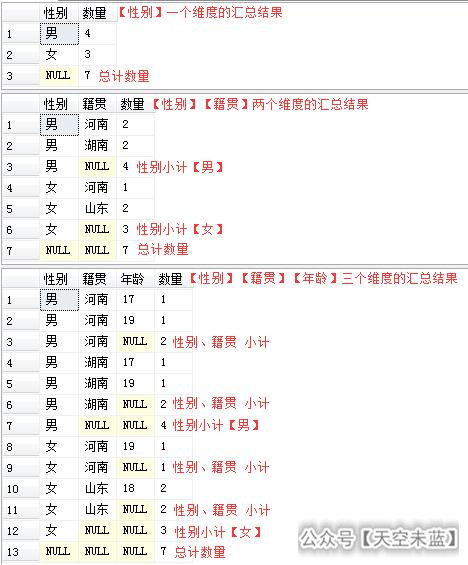
结果分析:可以看出,ROLLUP提供了更多的统计数据,并且在结果中包含了很多“NULL”值的数据行,其实这些含“NULL”的数据行就是ROLLUP提供的汇总项,再仔细分析一下,不难看出,ROLLUP计算了指定分组(就是汇总的维度)的多个层次的数量小计以及合计,先逐步创建高一级别的小计,最后再创建一行总计。整体结果都是以【性别】这一层次进行数据聚合(这也是与CUBE的不同之处)。
第三层:【GROUP BY】+【WITH CUBE】
还有没有更多组合的数据聚合,CUBE可以提供所选择列的所有组合的聚合。简单说,CUBE生成的结果是个多维数据集,就是包含各个维度的所有可能组合的交叉表格。看个例子先:
SQL语句如下:
1 --语句只用了【性别】和【籍贯】两个维度进行汇总 2 SELECT 性别, 籍贯, COUNT(学号) AS 数量 3 FROM STUDENT 4 GROUP BY 性别, 籍贯 WITH CUBE
执行结果如下:

结果分析:与上面的ROLLUP的结果进行对比,是不是可以看到更多的结果数据。不仅有性别的小计,还有籍贯的小计。CUBE可以为指定的列创建各种不同组合的小计,是一种比 ROLLUP更细粒度的分组统计语句。如果将统计维度调整到三个维度,会与ROLLUP有更大的差异,三个维度下的CUBE结果有点多,篇幅有限,就用个GIF展示下,感兴趣的小伙伴可以自己试一下。
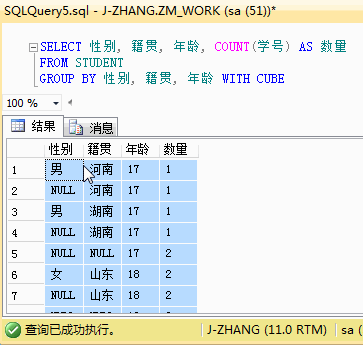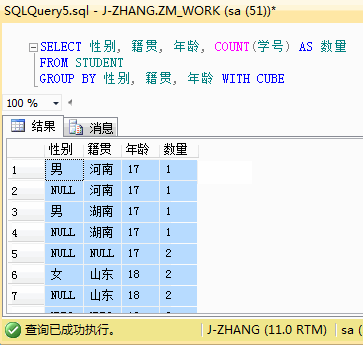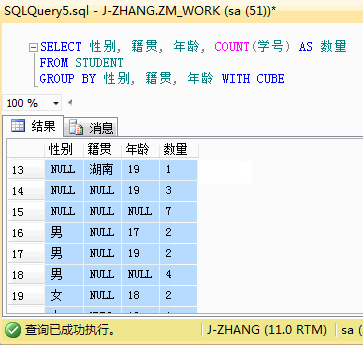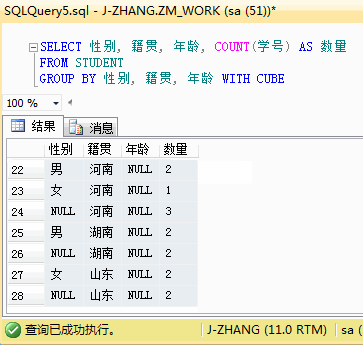
最后,引用一下书面的总结,CUBE和ROLLUP之间的区别在于:
CUBE 生成的结果集显示了所选列中值的所有组合的聚合。
ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
感觉也可以这样来说:ROLLUP就是将GROUP BY后面的第一列名称求总和,而其他列并不要求,而CUBE则会将每一个列名称都求总和。
OK!就酱紫,水平有限,希望能给看到朋友一点小小的帮助。
也可关注一下微信公众号,共同学习交流。
