前言:当深度学习使用的训练数据文件过大,使用pandas读取时会一次性读取全部数据,给内存带来了极大的压力。Tensorflow提供了一个使用队列且多线程读取文件的机制,缓解了内存的压力。该程序完整代码:https://github.com/iapcoder/TensorflowReadCSV
一 步骤:
1、构造文件队列
file_queue = tf.train.string_input_producer(file_list) # file_list: csv文件路径列表2、构造csv阅读器读取队列数据(读取的是一行)
reader = tf.TextLineReader(skip_header_lines=1) # skip_header_lines 指定跳过几行
key, value = reader.read(file_queue) # key:行号 value: 内容3、对每行的内容进行解码
records = [[1.0], [1]] # 指定每一列的类型,1.0表示是浮点型,缺失则为1.0, 1表示整型,缺失则为1,“None”表示字符串,缺失则为None
example, label = tf.decode_csv(value, record_defaults=records) # 返回的是一行的数据4、若想读取多个数据,需要使用批处理
example_batch, label_batch = tf.train.batch([example, label], batch_size=9, num_threads=2, capacity=9) # batch_size:要读取多少行 num_threads:指定多少个子线程 capacity:指定队列容量5、开启会话获取数据
with tf.Session() as sess:
coord = tf.train.coordinator() # 定义一个线程协调器
threads = tf.train.start_queue_runner(sess, coord=coord) # 开启读取文件的线程
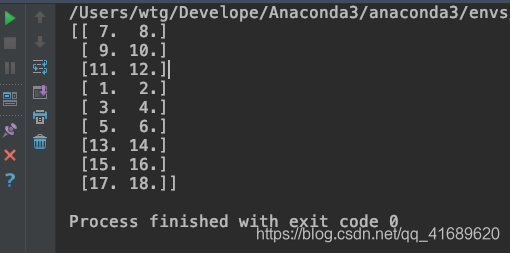
data = sess.run([example_batch, label_batch]) # 获取数据
coord.request_stop() # 请求关闭线程
coord.join(threads) # 主线程等待子线程结束二 实例
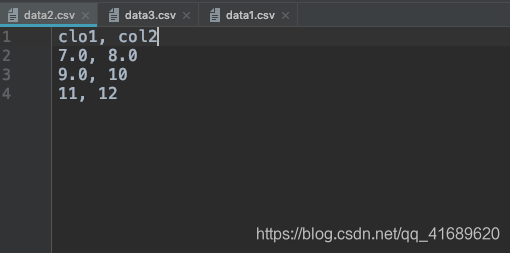
假设有三个csv文件,如下图所示,第一行为表头。
构造三个文件路径的列表,传入给文件队列
file_name = os.listdir("../datas/")
file_list = [os.path.join("../datas/", file) for file in file_name]经过Tensorflow读取文本数据