R-CNN算法中我已经知道了它的几个缺点,分别是:提取候选框耗时、重复计算、多次训练;针对以上几个缺点,作者对R-CNN做了改进和优化,改进的主要突破就在于对卷积特征进行共享,避免重复计算,减小计算量。
先来看下下面这张图,第一行就是原始R-CNN的特征提取和表示的过程:
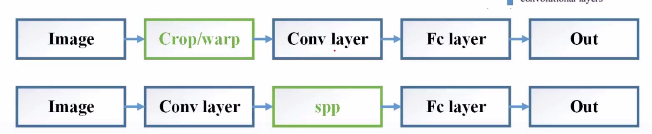
由于要将同一个卷积层的输出作为FC层的输入,所以必须要保证feature map的大小一致(因为全连接层对特征个数有严格要求,即每一个神经元都对应一个特征),所以卷积层的输入Image(候选框)必须要大小一致,由于候选框的大小不一,所以必须要对候选框进行crop或warp(抠图)的操作,然后进行resize,但是大家都知道一旦进行resize,就会对原图造成不同程度的扭曲和拉伸,进而会对提取到的卷积层的feature map产生精度上的影响,降低图像识别准确率。
另外,我们看到上图第一行中,在卷积层之前,每一次都要对原图进行抠图和resize,而且在FC层之前的输入,每一个候选框都要做一次卷积特征提取,导致重复计算。
因此,基于以上两点,提出了SPPNet,请看上图第二行,将SPP的输出作为FC层的输入,完成固定尺寸输出的操作,并且不再采用每一个候选框作为整个框架的输,而是直接把正常原始图片作为输入,先进行卷积操作(记住哦,是一次卷积操作,只有一次),进而产生多个feature map,然后把ss算法提取到的2000个候选区域的位置映射到feature map的对应位置上抠图,进而将抠图得到的feature map送入SPP层,最红得到固定尺寸的FC层输入进行权重计算。
关于SPPNet,具体操作如下图:

不难发现,这里给出了一个三层的金字塔池化层,也就是有3个不同尺度为4x4,2x2,1x1;
也就是不管feature map的大小有多大,都将其分别平均划分成16,4,1个网格,每一个网络就是一个特征点,通过最大池,分别得到16、4、1个特征,最终得到feature map的输出维度就是(16 + 4 + 1)x 通道数,达到固定尺寸的输出,而无需考虑不同尺寸的图片输入,可以看到这里的通道数是256;
注意:这里需要多少个金字塔池化层,以及划分成多少个网格都是任意的,根据自己需要而定。并且,有了SPP层,就可以实现对任意尺寸的图片进行CNN处理。
因此,SPPNet的提出,不仅提升了识别效果,而且也加快了识别速度,于是乎作者在R-CNN上结合SPPNet做了优化。
目标检测之SPPNet通俗详解
版权声明:本文为博主原创文章,转载请注明出处:http://blog.csdn.net/eternity1118_。 https://blog.csdn.net/eternity1118_/article/details/89707018
猜你喜欢
转载自blog.csdn.net/eternity1118_/article/details/89707018
今日推荐
周排行