1、注意网页隐藏的信息
在 HTML 表单中,“隐含”字段可以让字段的值对浏览器可见,但是对用户不可见(除非看网页源代码)。随着越来越多的网站开始用 cookie 存储状态变量来管理用户状态,在找到另一个最佳用途之前,隐含字段主要用于阻止爬虫自动提交表单。
下图显示的例子就是 Facebook 登录页面上的隐含字段。虽然表单里只有三个可见字段(username、password 和一个确认按钮),但是在源代码里表单会向服务器传送大量的信息。
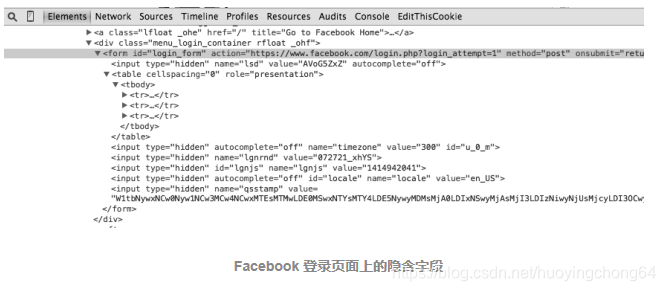
Facebook 登录页面上的隐含字段
用隐含字段阻止网络数据采集的方式主要有两种。第一种是表单页面上的一个字段可以用服务器生成的随机变量表示。如果提交时这个值不在表单处理页面上,服务器就有理由认为这个提交不是从原始表单页面上提交的,而是由一个网络机器人直接提交到表单处理页面的。绕开这个问题的最佳方法就是,首先采集表单所在页面上生成的随机变量,然后再提交到表单处理页面。
第二种方式是“蜜罐”(honey pot)。如果表单里包含一个具有普通名称的隐含字段(设置蜜罐圈套),比如“用户名”(username)或“邮箱地址”(email address),设计不太好的网络机器人往往不管这个字段是不是对用户可见,直接填写这个字段并向服务器提交,这样就会中服务器的蜜罐圈套。服务器会把所有隐含字段的真实值(或者与表单提交页面的默认值不同的值)都忽略,而且填写隐含字段的访问用户也可能被网站封杀。
总之,有时检查表单所在的页面十分必要,看看有没有遗漏或弄错一些服务器预先设定好的隐含字段(蜜罐圈套)。如果你看到一些隐含字段,通常带有较大的随机字符串变量,那么很可能网络服务器会在表单提交的时候检查它们。另外,还有其他一些检查,用来保证这些当前生成的表单变量只被使用一次或是最近生成的(这样可以避免变量被简单地存储到一个程序中反复使用)。
- 避免进入蜜罐
虽然在进行网络数据采集时用 CSS 属性区分有用信息和无用信息会很容易(比如,通过读取 id和 class 标签获取信息),但这么做有时也会出问题。如果网络表单的一个字段通过 CSS 设置成对用户不可见,那么可以认为普通用户访问网站的时候不能填写这个字段,因为它没有显示在浏览器上。如果这个字段被填写了,就可能是机器人干的,因此这个提交会失效。
这种手段不仅可以应用在网站的表单上,还可以应用在链接、图片、文件,以及一些可以被机器人读取,但普通用户在浏览器上却看不到的任何内容上面。访问者如果访问了网站上的一个“隐含”内容,就会触发服务器脚本封杀这个用户的 IP 地址,把这个用户踢出网站,或者采取其他措施禁止这个用户接入网站。实际上,许多商业模式就是在干这些事情。
下面的例子所用的网页在 http://pythonscraping.com/pages/itsatrap.html。这个页面包含了两个链接,一个通过 CSS 隐含了,另一个是可见的。另外,页面上还包括两个隐含字段:
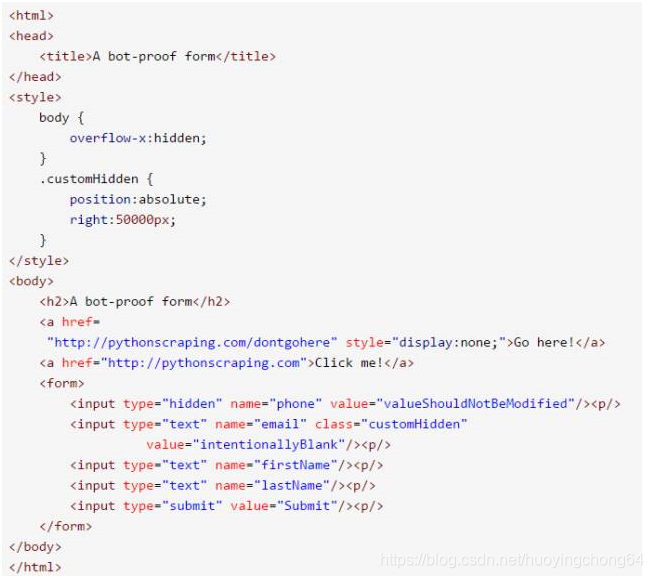
这三个元素通过三种不同的方式对用户隐藏:
第一个链接是通过简单的 CSS 属性设置 display:none 进行隐藏
电话号码字段 name=“phone” 是一个隐含的输入字段
邮箱地址字段 name=“email” 是将元素向右移动 50 000 像素(应该会超出电脑显示器的边界)并隐藏滚动条
因为 Selenium 可以获取访问页面的内容,所以它可以区分页面上的可见元素与隐含元素。通过 is_displayed() 可以判断元素在页面上是否可见。
例如,下面的代码示例就是获取前面那个页面的内容,然后查找隐含链接和隐含输入字段:
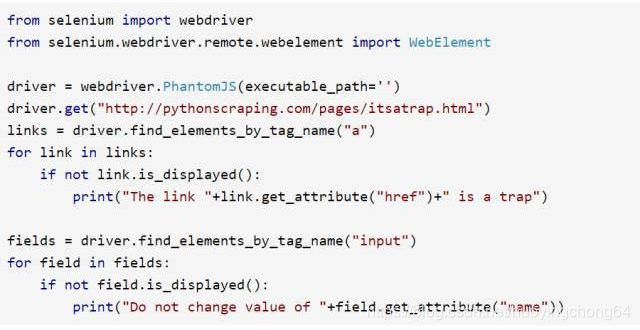
Selenium 抓取出了每个隐含的链接和字段,结果如下所示:

虽然你不太可能会去访问你找到的那些隐含链接,但是在提交前,记得确认一下那些已经在表单中、准备提交的隐含字段的值(或者让 Selenium 为你自动提交)。