文章来源:https://blog.csdn.net/sinat_35866463/article/details/80341524
每个html标签都有各自的功能。【a】标签存放一下超链接,图片存放在哪个标签里呢?html规定,图片放到【img】标签中。
【img】标签有很多属性,有alt、src、class、style属性,其中src属性存放的就是我们需要的图片保存地址,我们根据这个地址就可以进行图片的下载。
网站有静态网站和动态网站之分,一般图片网站基本上大部分都是动态加载的类型。基本上都是为了反爬虫。
动态网站使用动态加载常用的手段就是通过调用JavaScript来实现的一个动态加载的网站可能使用很多JavaScript脚本,我们只要找到负责动态加载图片的JavaScript脚本,不就找到我们需要的链接了吗?
对于初学者,我们不必看懂JavaScript执行的内容是什么,做了哪些事情,因为我们有强大的抓包工具,它自然会帮我们分析。这个强大的抓包工具就是Fiddler:http://www.telerik.com/fiddler
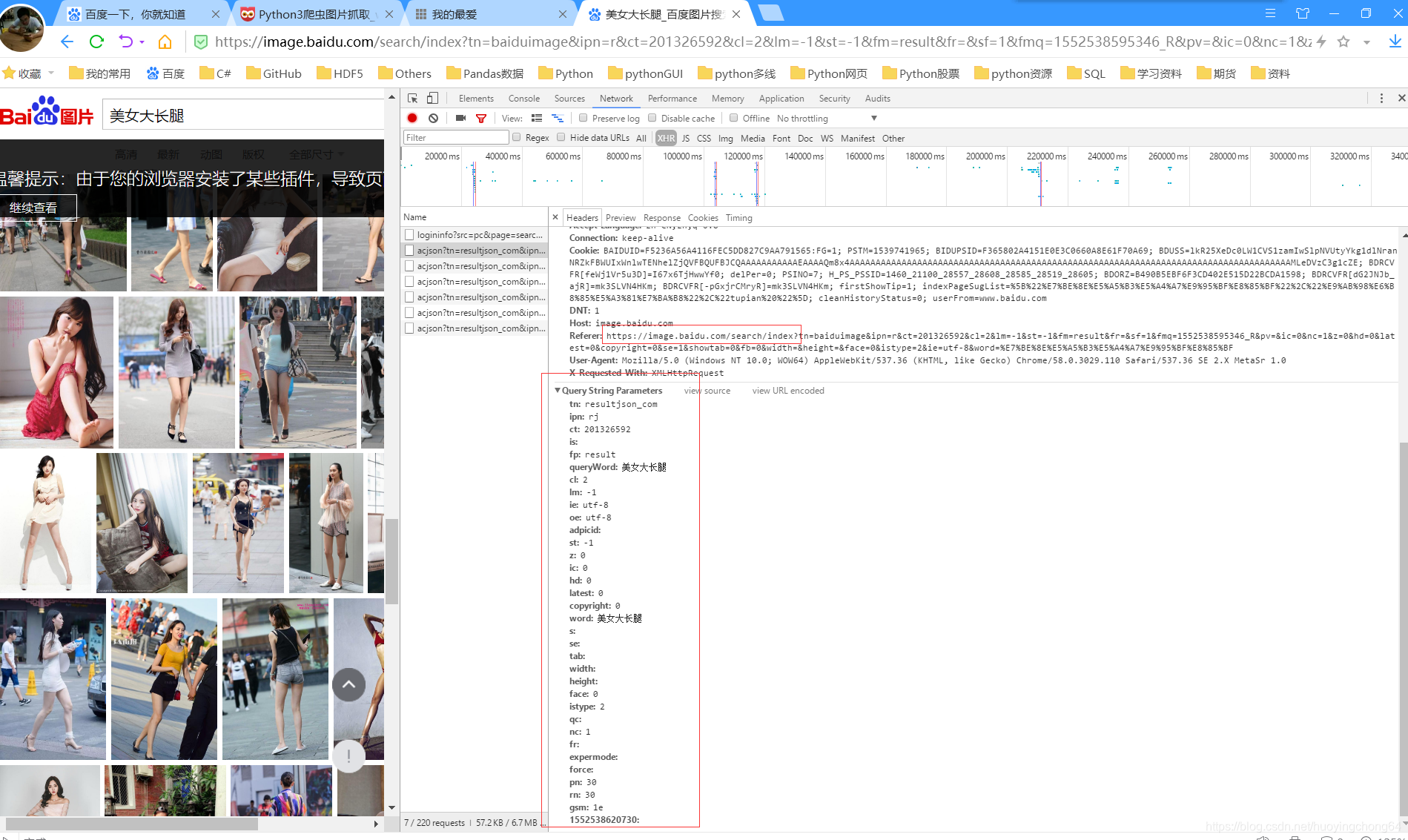
另外也可以使用浏览器自带的Networks。
如下的代码段就是使用浏览器自带的Networks来实现的。在图片页面滚动条行动后,会出现json
请求,点开这条信息的header,在多次滚动后,经过对比,可以知道参数的变化
import urllib.request
import re
import requests
import time
import logging
LocalDay = time.strftime("%Y-%m-%d")
logFile = r'D:\log\{0}.log'.format(LocalDay)
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename=logFile,
filemode='a+')
console = logging.StreamHandler()
console.setLevel(logging.INFO)
formatter = logging.Formatter('%(name)-12s: %(levelname)-8s %(message)s')
console.setFormatter(formatter)
logging.getLogger('').addHandler(console)
def getDatas(keyword, pages):
params = []
for i in range(30, 30 * pages + 30, 30):
params.append({
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': 0,
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': 1,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '1e',
'1526377465547': ''
})
url = 'https://image.baidu.com/search/index'
urls = []
for i in params:
urls.append(requests.get(url, params=i).json().get('data'))
return urls
def getImg(datalist, path):
x = 0
for list in datalist:
for i in list:
if i.get('thumbURL') != None:
logging.info('正在下载:%s' % i.get('thumbURL'))
urllib.request.urlretrieve(i.get('thumbURL'), path + '%d.jpg' % x)
x += 1
else:
logging.info('当前轮次已经下载完成')
if __name__ == '__main__':
queryKeyword = '黑丝大长腿'#查询关键字
pages = 10#下载页数
totalPics = pages*30
logging.info('开始下载%s的图片,预计下载图片%d张'%(queryKeyword,totalPics))
datalist = getDatas(queryKeyword, pages)
getImg(datalist, 'D://Spyder//黑丝大长腿')