版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_24990189/article/details/89606221
1.学习目标:
了解纹理内存的性能特性
了解如何在CUDA C中使用一维纹理内存
了解如何在CUDA C中使用二维纹理内存
2.背景提出:
特定环境中使用特殊的内存将极大地提升应用程序的性能。与Constant Memory相似,Texture Memory同样缓存在芯片上,只读内存,在某些情况下,能减少对内存的请求并提供更高效的内存带宽。Texture Mmeory是专门为那些在内存访问模式中存在大量空间局部性(Spatial Locality)的图形应用程序而设计的。意思是,在某个计算应用程序中,这意味着一个Thread读取的位置可能与邻近Thread读取的位置“非常接近”。

从数学角度,图中四个地址并非连续,在一般的CPU缓存模式中,这些地址将不会缓存。GPU纹理缓存是为了加速这种访问模式而设设计的,因此如果在这种情况中使用纹理内存而不是全局内存,那么将会获得性能提升。
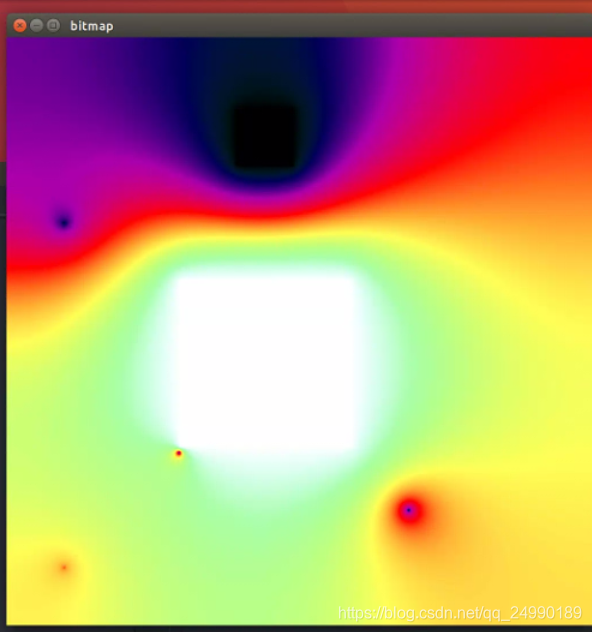
3.案例分析:二维热传导模拟
构造:
格网中随机散步“热源”,他们有着不同的固定的温度。在给定了矩形格网以及热源分布后,我们可以计算格网中每个单元的温度随时间的变化情况。为了简单,热源单元本身的温度将保持不变。但是,热量从更热的单元传导到更冷的单元

温度更新计算:
4.代码复现-一维纹理内存版本-- texture、cudaBindTexture()
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_anim.h"
#define DIM 1024
#define PI 3.1415926535897932f
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
// these exist on the GPU side
// 这些变量将位与GPU上
texture<float> texConstSrc;
texture<float> texIn;
texture<float> texOut;
// this kernel takes in a 2-d array of floats
// it updates the value-of-interest by a scaled value based
// on itself and its nearest neighbors
//给定一个输入格网,据等式7.2中的更新公式计算输出温度格网。
__global__ void blend_kernel( float *dst,
bool dstOut ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
int left = offset - 1;
int right = offset + 1;
if (x == 0) left++;
if (x == DIM-1) right--;
int top = offset - DIM;
int bottom = offset + DIM;
if (y == 0) top += DIM;
if (y == DIM-1) bottom -= DIM;
float t, l, c, r, b;
if (dstOut) {
t = tex1Dfetch(texIn,top);
l = tex1Dfetch(texIn,left);
c = tex1Dfetch(texIn,offset);
r = tex1Dfetch(texIn,right);
b = tex1Dfetch(texIn,bottom);
} else {
t = tex1Dfetch(texOut,top);
l = tex1Dfetch(texOut,left);
c = tex1Dfetch(texOut,offset);
r = tex1Dfetch(texOut,right);
b = tex1Dfetch(texOut,bottom);
}
dst[offset] = c + SPEED * (t + b + r + l - 4 * c);
}
// NOTE - texOffsetConstSrc could either be passed as a
// parameter to this function, or passed in __constant__ memory
// if we declared it as a global above, it would be
// a parameter here:
//给定一个包含初始输入温度的格网,将其中作为热源的单元温度值复制到格网相应单元中。这将覆盖这些大院之前计算出的温度。
// __global__ void copy_const_kernel( float *iptr,
// size_t texOffset )
__global__ void copy_const_kernel( float *iptr ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float c = tex1Dfetch(texConstSrc,offset);
if (c != 0)
iptr[offset] = c;
}
// globals needed by the update routine
struct DataBlock {
unsigned char *output_bitmap;
float *dev_inSrc;
float *dev_outSrc;
float *dev_constSrc;
CPUAnimBitmap *bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
void anim_gpu( DataBlock *d, int ticks ) {
HANDLE_ERROR( cudaEventRecord( d->start, 0 ) );
dim3 blocks(DIM/16,DIM/16);
dim3 threads(16,16);
CPUAnimBitmap *bitmap = d->bitmap;
// since tex is global and bound, we have to use a flag to
// select which is in/out per iteration
volatile bool dstOut = true;
for (int i=0; i<90; i++) {
float *in, *out;
if (dstOut) {
in = d->dev_inSrc;
out = d->dev_outSrc;
} else {
out = d->dev_inSrc;
in = d->dev_outSrc;
}
copy_const_kernel<<<blocks,threads>>>( in );
blend_kernel<<<blocks,threads>>>( out, dstOut );
dstOut = !dstOut;
}
float_to_color<<<blocks,threads>>>( d->output_bitmap,
d->dev_inSrc );
HANDLE_ERROR( cudaMemcpy( bitmap->get_ptr(),
d->output_bitmap,
bitmap->image_size(),
cudaMemcpyDeviceToHost ) );
HANDLE_ERROR( cudaEventRecord( d->stop, 0 ) );
HANDLE_ERROR( cudaEventSynchronize( d->stop ) );
float elapsedTime;
HANDLE_ERROR( cudaEventElapsedTime( &elapsedTime,
d->start, d->stop ) );
d->totalTime += elapsedTime;
++d->frames;
printf( "Average Time per frame: %3.1f ms\n",
d->totalTime/d->frames );
}
// clean up memory allocated on the GPU
void anim_exit( DataBlock *d ) {
cudaUnbindTexture( texIn );
cudaUnbindTexture( texOut );
cudaUnbindTexture( texConstSrc );
HANDLE_ERROR( cudaFree( d->dev_inSrc ) );
HANDLE_ERROR( cudaFree( d->dev_outSrc ) );
HANDLE_ERROR( cudaFree( d->dev_constSrc ) );
HANDLE_ERROR( cudaEventDestroy( d->start ) );
HANDLE_ERROR( cudaEventDestroy( d->stop ) );
}
int main( void ) {
DataBlock data;
CPUAnimBitmap bitmap( DIM, DIM, &data );
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
HANDLE_ERROR( cudaEventCreate( &data.start ) );
HANDLE_ERROR( cudaEventCreate( &data.stop ) );
int imageSize = bitmap.image_size();
HANDLE_ERROR( cudaMalloc( (void**)&data.output_bitmap,
imageSize ) );
// assume float == 4 chars in size (ie rgba)
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_inSrc,
imageSize ) );
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_outSrc,
imageSize ) );
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_constSrc,
imageSize ) );
HANDLE_ERROR( cudaBindTexture( NULL, texConstSrc,
data.dev_constSrc,
imageSize ) );
HANDLE_ERROR( cudaBindTexture( NULL, texIn,
data.dev_inSrc,
imageSize ) );
HANDLE_ERROR( cudaBindTexture( NULL, texOut,
data.dev_outSrc,
imageSize ) );
// intialize the constant data
float *temp = (float*)malloc( imageSize );
for (int i=0; i<DIM*DIM; i++) {
temp[i] = 0;
int x = i % DIM;
int y = i / DIM;
if ((x>300) && (x<600) && (y>310) && (y<601))
temp[i] = MAX_TEMP;
}
temp[DIM*100+100] = (MAX_TEMP + MIN_TEMP)/2;
temp[DIM*700+100] = MIN_TEMP;
temp[DIM*300+300] = MIN_TEMP;
temp[DIM*200+700] = MIN_TEMP;
for (int y=800; y<900; y++) {
for (int x=400; x<500; x++) {
temp[x+y*DIM] = MIN_TEMP;
}
}
HANDLE_ERROR( cudaMemcpy( data.dev_constSrc, temp,
imageSize,
cudaMemcpyHostToDevice ) );
// initialize the input data
for (int y=800; y<DIM; y++) {
for (int x=0; x<200; x++) {
temp[x+y*DIM] = MAX_TEMP;
}
}
HANDLE_ERROR( cudaMemcpy( data.dev_inSrc, temp,
imageSize,
cudaMemcpyHostToDevice ) );
free( temp );
bitmap.anim_and_exit( (void (*)(void*,int))anim_gpu,
(void (*)(void*))anim_exit );
}
wlsh@wlsh-ThinkStation:~/Desktop/GPU高性能编程CUDA实战—示例代码/chapter07$ nvcc -o heat heat.cu -lglut -lGL -lGLU
../common/cpu_anim.h(61): warning: conversion from a string literal to "char *" is deprecated
../common/cpu_anim.h(61): warning: conversion from a string literal to "char *" is deprecated
wlsh@wlsh-ThinkStation:~/Desktop/GPU高性能编程CUDA实战—示例代码/chapter07$ ./heat
wlsh@wlsh-ThinkStation:~/Desktop/GPU高性能编程CUDA实战—示例代码/chapter07$ ./heat
Average Time per frame: 9.2 ms
Average Time per frame: 8.6 ms
Average Time per frame: 8.5 ms
Average Time per frame: 8.5 ms
Average Time per frame: 8.3 ms
Average Time per frame: 8.3 ms
Average Time per frame: 8.3 ms
Average Time per frame: 8.2 ms
Average Time per frame: 8.2 ms
Average Time per frame: 8.1 ms
Average Time per frame: 8.2 ms
Average Time per frame: 8.2 ms
Average Time per frame: 8.3 ms
Average Time per frame: 8.7 ms
Average Time per frame: 9.0 ms
Average Time per frame: 8.9 ms
Average Time per frame: 8.9 ms
5.代码复现-二维纹理内存版本
#include "cuda.h"
#include "../common/book.h"
#include "../common/cpu_anim.h"
#define DIM 1024
#define PI 3.1415926535897932f
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
// these exist on the GPU side
texture<float,2> texConstSrc;
texture<float,2> texIn;
texture<float,2> texOut;
__global__ void blend_kernel( float *dst,
bool dstOut ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float t, l, c, r, b;
if (dstOut) {
t = tex2D(texIn,x,y-1);
l = tex2D(texIn,x-1,y);
c = tex2D(texIn,x,y);
r = tex2D(texIn,x+1,y);
b = tex2D(texIn,x,y+1);
} else {
t = tex2D(texOut,x,y-1);
l = tex2D(texOut,x-1,y);
c = tex2D(texOut,x,y);
r = tex2D(texOut,x+1,y);
b = tex2D(texOut,x,y+1);
}
dst[offset] = c + SPEED * (t + b + r + l - 4 * c);
}
__global__ void copy_const_kernel( float *iptr ) {
// map from threadIdx/BlockIdx to pixel position
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float c = tex2D(texConstSrc,x,y);
if (c != 0)
iptr[offset] = c;
}
// globals needed by the update routine
struct DataBlock {
unsigned char *output_bitmap;
float *dev_inSrc;
float *dev_outSrc;
float *dev_constSrc;
CPUAnimBitmap *bitmap;
cudaEvent_t start, stop;
float totalTime;
float frames;
};
void anim_gpu( DataBlock *d, int ticks ) {
HANDLE_ERROR( cudaEventRecord( d->start, 0 ) );
dim3 blocks(DIM/16,DIM/16);
dim3 threads(16,16);
CPUAnimBitmap *bitmap = d->bitmap;
// since tex is global and bound, we have to use a flag to
// select which is in/out per iteration
volatile bool dstOut = true;
for (int i=0; i<90; i++) {
float *in, *out;
if (dstOut) {
in = d->dev_inSrc;
out = d->dev_outSrc;
} else {
out = d->dev_inSrc;
in = d->dev_outSrc;
}
copy_const_kernel<<<blocks,threads>>>( in );
blend_kernel<<<blocks,threads>>>( out, dstOut );
dstOut = !dstOut;
}
float_to_color<<<blocks,threads>>>( d->output_bitmap,
d->dev_inSrc );
HANDLE_ERROR( cudaMemcpy( bitmap->get_ptr(),
d->output_bitmap,
bitmap->image_size(),
cudaMemcpyDeviceToHost ) );
HANDLE_ERROR( cudaEventRecord( d->stop, 0 ) );
HANDLE_ERROR( cudaEventSynchronize( d->stop ) );
float elapsedTime;
HANDLE_ERROR( cudaEventElapsedTime( &elapsedTime,
d->start, d->stop ) );
d->totalTime += elapsedTime;
++d->frames;
printf( "Average Time per frame: %3.1f ms\n",
d->totalTime/d->frames );
}
// clean up memory allocated on the GPU
void anim_exit( DataBlock *d ) {
cudaUnbindTexture( texIn );
cudaUnbindTexture( texOut );
cudaUnbindTexture( texConstSrc );
HANDLE_ERROR( cudaFree( d->dev_inSrc ) );
HANDLE_ERROR( cudaFree( d->dev_outSrc ) );
HANDLE_ERROR( cudaFree( d->dev_constSrc ) );
HANDLE_ERROR( cudaEventDestroy( d->start ) );
HANDLE_ERROR( cudaEventDestroy( d->stop ) );
}
int main( void ) {
DataBlock data;
CPUAnimBitmap bitmap( DIM, DIM, &data );
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
HANDLE_ERROR( cudaEventCreate( &data.start ) );
HANDLE_ERROR( cudaEventCreate( &data.stop ) );
int imageSize = bitmap.image_size();
HANDLE_ERROR( cudaMalloc( (void**)&data.output_bitmap,
imageSize ) );
// assume float == 4 chars in size (ie rgba)
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_inSrc,
imageSize ) );
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_outSrc,
imageSize ) );
HANDLE_ERROR( cudaMalloc( (void**)&data.dev_constSrc,
imageSize ) );
cudaChannelFormatDesc desc = cudaCreateChannelDesc<float>();
HANDLE_ERROR( cudaBindTexture2D( NULL, texConstSrc,
data.dev_constSrc,
desc, DIM, DIM,
sizeof(float) * DIM ) );
HANDLE_ERROR( cudaBindTexture2D( NULL, texIn,
data.dev_inSrc,
desc, DIM, DIM,
sizeof(float) * DIM ) );
HANDLE_ERROR( cudaBindTexture2D( NULL, texOut,
data.dev_outSrc,
desc, DIM, DIM,
sizeof(float) * DIM ) );
// initialize the constant data
float *temp = (float*)malloc( imageSize );
for (int i=0; i<DIM*DIM; i++) {
temp[i] = 0;
int x = i % DIM;
int y = i / DIM;
if ((x>300) && (x<600) && (y>310) && (y<601))
temp[i] = MAX_TEMP;
}
temp[DIM*100+100] = (MAX_TEMP + MIN_TEMP)/2;
temp[DIM*700+100] = MIN_TEMP;
temp[DIM*300+300] = MIN_TEMP;
temp[DIM*200+700] = MIN_TEMP;
for (int y=800; y<900; y++) {
for (int x=400; x<500; x++) {
temp[x+y*DIM] = MIN_TEMP;
}
}
HANDLE_ERROR( cudaMemcpy( data.dev_constSrc, temp,
imageSize,
cudaMemcpyHostToDevice ) );
// initialize the input data
for (int y=800; y<DIM; y++) {
for (int x=0; x<200; x++) {
temp[x+y*DIM] = MAX_TEMP;
}
}
HANDLE_ERROR( cudaMemcpy( data.dev_inSrc, temp,
imageSize,
cudaMemcpyHostToDevice ) );
free( temp );
bitmap.anim_and_exit( (void (*)(void*,int))anim_gpu,
(void (*)(void*))anim_exit );
}
wlsh@wlsh-ThinkStation:~/Desktop/GPU高性能编程CUDA实战—示例代码/chapter07$ nvcc -o heat_2d heat_2d.cu -lglut -lGL -lGLU
wlsh@wlsh-ThinkStation:~/Desktop/GPU高性能编程CUDA实战—示例代码/chapter07$ ./heat_2d