async/await关键字是出现在python3.4以后。网上已经有很多文章对async/await这两个关键字都有讲解,包括如何由python2的yield from发展到async/await这两个关键字,以及一些代码实现都有。但是对于像我这样初次接触的人来说,光看代码分析也不一定能理解,我也是在度娘上搜索很多相关的网站,当中也有官网,都没有发现能让我一眼看懂在什么地方可以用await,什么情况用await的文章。经过自己的重新思考,总算对async、await有一些初步的了解,所以想把自己的理解记录下来,希望对一些学习协程或者异步的初学者也有一定的帮助。
对于网上能搜到的一些代码实现、例子,这里就不重复了。
一、首先要知道什么是协程、异步。
举个例子:假设有1个洗衣房,里面有10台洗衣机,有一个洗衣工在负责这10台洗衣机。那么洗衣房就相当于1个进程,洗衣工就相当1个线程。如果有10个洗衣工,就相当于10个线程,1个进程是可以开多线程的。这就是多线程!
那么协程呢?先不急。大家都知道,洗衣机洗衣服是需要等待时间的,如果10个洗衣工,1人负责1台洗衣机,这样效率肯定会提高,但是不觉得浪费资源吗?明明1 个人能做的事,却要10个人来做。只是把衣服放进去,打开开关,就没事做了,等衣服洗好再拿出来就可以了。就算很多人来洗衣服,1个人也足以应付了,开好第一台洗衣机,在等待的时候去开第二台洗衣机,再开第三台,……直到有衣服洗好了,就回来把衣服取出来,接着再取另一台的(哪台洗好先就取哪台,所以协程是无序的)。这就是计算机的协程!洗衣机就是执行的方法。
当你程序中方法需要等待时间的话,就可以用协程,效率高,消耗资源少。
好了!现在来总结一下:
洗衣房 ==> 进程
洗衣工 ==> 线程
洗衣机 ==> 方法(函数)
二、Python中的异步
对于一些熟悉编写传统python代码的人来说,转换到异步程序可能有些不好接受。Python中的异步程序依赖于 Coroutines(协程) ,它与event loop(事件循环)一同工作,写出的代码像是执行多个小任务的片段。 协程可以看作是在代码中有一些带点函数,这些带点函数又是控制程序回调中的上下文,除了通过上下文交换数据,这些“yield”点还可以暂停和恢复协程执行。
事件循环决定了可以在任何指定时刻运行代码块—它负责协程之间的暂停、恢复和通信。 这意味着不同协程的最终可能以不同于它们之前被安排的顺序执行。 这种不按固定顺序运行不同代码块的想法称为异步。
可以在 HTTP 请求的场景中阐述异步的重要性。设想要向服务器发大量的请求。比如,要查询一个网站,以获得指定赛季所有运动员的统计信息。
我们可以按顺序依次发出每个请求。然而,对于每个请求,可以想象到可能会花一些时间等待上一个请求被发送到服务器,且收到服务器响应。
但是有时,这些无用的花销甚至可能需要几秒钟。因为程序可能会遇到网络延迟,访问数量过多,又或者是对方服务器的速度限制等问题。
如果我们的代码可以在等待服务器响应的同时做其他事情呢?而且,如果它只在响应数据到达后才处理返回数据呢?如果我们不必等到每个单独的请求都完成之后才继续处理列表中的下一个请求,那么我们可以快速地连续发出许多请求。
具有event loop的协程就可以让我们的代码支持以这样的形式运行。
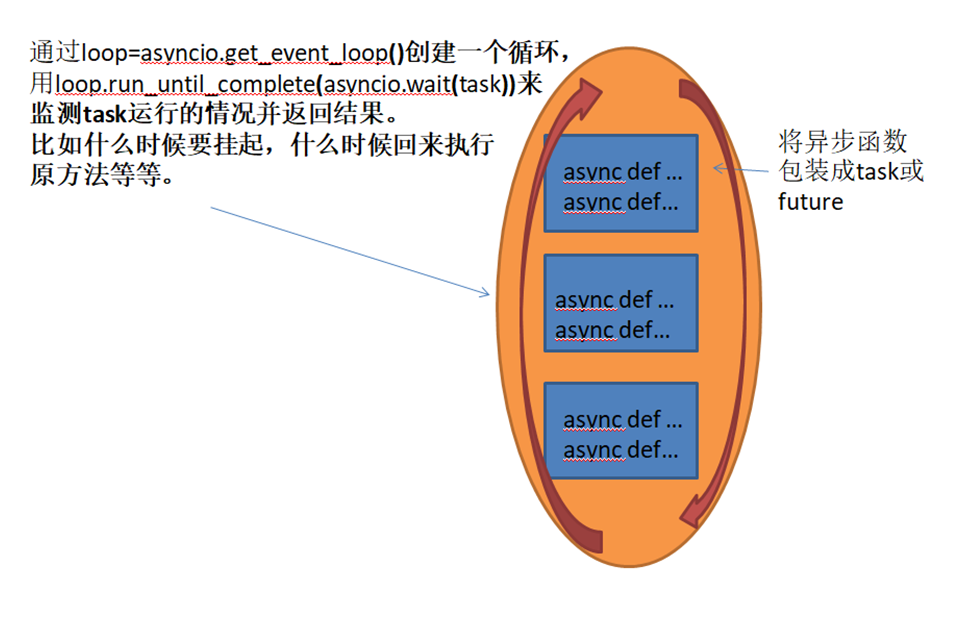
三、async\await 的使用
正常的函数在执行时是不会中断的,所以你要写一个能够中断的函数,就需要添加async关键。
async 用来声明一个函数为异步函数,异步函数的特点是能在函数执行过程中挂起,去执行其他异步函数,等到挂起条件(假设挂起条件是sleep(5))消失后,也就是5秒到了再回来执行。
await 用来用来声明程序挂起,比如异步程序执行到某一步时需要等待的时间很长,就将此挂起,去执行其他的异步程序。await 后面只能跟异步程序或有__await__属性的对象,因为异步程序与一般程序不同。假设有两个异步函数async a,async b,a中的某一步有await,当程序碰到关键字await b()后,异步程序挂起后去执行另一个异步b程序,就是从函数内部跳出去执行其他函数,当挂起条件消失后,不管b是否执行完,要马上从b程序中跳出来,回到原程序执行原来的操作。如果await后面跟的b函数不是异步函数,那么操作就只能等b执行完再返回,无法在b执行的过程中返回。如果要在b执行完才返回,也就不需要用await关键字了,直接调用b函数就行。所以这就需要await后面跟的是异步函数了。在一个异步函数中,可以不止一次挂起,也就是可以用多个await。
import time
import asyncio
import requests
async def test2(i):
r = await other_test(i)
print(i,r)
async def other_test(i):
r = requests.get(i)
print(i)
await asyncio.sleep(4)
print(time.time()-start)
return r
if __name__ == '__main__':
url = ["https://segmentfault.com/p/1210000013564725",
"https://www.jianshu.com/p/83badc8028bd",
"https://www.baidu.com/"]
task = [asyncio.ensure_future(test2(i)) for i in url]
start = time.time()
asyncio.get_event_loop().run_until_complete(asyncio.wait(task))
四、aiohttp
安装aiohttp
pip install aiohttp
客户端:发送请求
下面的示例演示了如何使用 aiohttp 下载某些urtl的HTML内容:
import asyncio
import aiohttp
async def make_request(url):
print(f"making request to {url}")
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
if resp.status == 200:
print(await resp.text())
if __name__ == '__main__':
urls = ["https://segmentfault.com/p/1210000013564725",
"https://www.jianshu.com/p/83badc8028bd",
"https://www.baidu.com/"]
task = [asyncio.ensure_future(make_request(url)) for url in urls]
asyncio.get_event_loop().run_until_complete(asyncio.wait(task))
- 有几点需要强调:
- 和前面的
await asyncio.sleep一样,要获取HTML页面的内容,必须在resp.text()前面使用await。否则程序打印出来的内容会是这样:
making request to https://www.baidu.com <coroutine object ClientResponse.text at 0x109b8ddb0>
-
async with是一个上下文管理器,它接收的是协程而不是函数。在这里的两处使用,是用于在内部自动关闭到服务器的连接释放资源。 -
aiohttp.ClientSession具有和HTTP方法相同的方法,session.get发送 GET 请求,session.post发送 POST 请求。
这个例子本身并不比同步HTTP请求有多大性能优势。aiohttp 客户端真正优势在于多个请求并发:
import asyncio
import aiohttp
async def make_request(session, req_n):
url = "https://www.baidu.com"
print(f"making request to {req_n} to {url}")
async with session.get(url) as resp:
if resp.status == 200:
print(await resp.text())
async def main():
n_request = 100
async with aiohttp.ClientSession() as session:
await asyncio.gather(*[make_request(session, i) for i in range(n_request)])
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
五、自定义协程异步框架
# -*- coding: utf-8 -*-
"""
@Datetime: 2019/5/2
@Author: Zhang Yafei
"""
import asyncio
import functools
import time
from collections import Iterator, Iterable
from pyquery import PyQuery as pq
import aiohttp
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
class Request(object):
"""
用于封装用户请求信息所用
"""
def __init__(self, url, callback):
self.url = url
self.callback = callback
class RequestManager(object):
def __init__(self):
self.new_requests = set()
self.old_requests = set()
def has_new_request(self):
""" 判断是否有未爬取的url """
return self.new_request_size() != 0
async def get_new_request(self):
""" 获取一个未爬取的请求 """
new_request = self.new_requests.pop()
# 提取之后,将其添加到已爬取的链接中
self.old_requests.add(new_request)
return new_request
async def add_new_request(self, request):
""" 将新请求添加到未爬取的集合中(单个请求) """
if request is None:
return
if request not in self.new_requests and request not in self.old_requests:
self.new_requests.add(request)
async def add_new_requests(self, requests):
""" 将新请求添加到未爬取的集合中(集合) """
if requests is None or len(requests) == 0:
return
for request in requests:
self.add_new_request(request)
def new_request_size(self):
""" 获取未爬取的url大小 """
return len(self.new_requests)
def old_request_size(self):
""" 获取已爬取的url大小 """
return len(self.old_requests)
class HTMLParser(object):
def __init__(self):
pass
async def parse(self, response):
items = {'name': 'parse'}
doc = pq(await response.text())
# print(doc)
print('parse---', response.url)
return [Request(url='http://www.sxmu.edu.cn/', callback=self.next_parse)]
# return [items]
async def next_parse(self, response):
doc = pq(await response.text())
print('next parse', response.url)
items = {'next_parse': response.url}
return [items]
class DataMemory(object):
def __init__(self):
pass
async def store_data(self, data):
print('store data: ', data)
def to_csv(self):
pass
def to_excel(self):
pass
def save_mongo(self):
pass
def save_redis(self):
pass
def save_mysql(self):
pass
class Crawler(object):
def __init__(self, urls):
self.manager = RequestManager()
self.parser = HTMLParser()
self.data_memory = DataMemory()
self.urls = urls
def filter_downloaded_urls(self):
return self.urls
async def start(self, session, request):
await self.manager.add_new_request(request)
while self.manager.has_new_request() and self.manager.old_request_size() < 100:
# 1. 取出新请求
new_request = await self.manager.get_new_request()
print(new_request.url)
# 2. 将请求的url进行下载
async with session.get(new_request.url) as response:
if response.status == 200:
# 3. 将下载的Html文本进行解析
result = await new_request.callback(response)
# 4. 判断解析之后返回的数据对象为新请求还是解析的数据
if not isinstance(result, Iterable):
raise Exception('返回的数据类型不可迭代')
for ret in result:
if isinstance(ret, Request):
# 5. 如果是新请求,则加入到请求管理器
await self.manager.add_new_request(ret)
elif isinstance(ret, dict) and ret:
# 6. 如果是解析的数据,则将数据进行存储
await self.data_memory.store_data(ret)
else:
raise Exception('返回数据类型或格式不正确,只能返回Request的实例对象或字典的实例对象,且不能为空')
async def run(self):
url_list = self.filter_downloaded_urls()
async with aiohttp.ClientSession() as session:
await asyncio.gather(*[self.start(session, Request(url, self.parser.parse)) for url in url_list])
def timeit(func):
@functools.wraps(func)
def inner(*args, **kwargs):
start = time.time()
ret = func(*args, **kwargs)
print(time.time() - start)
return ret
return inner
@timeit
def main():
urls = ['https://mp.weixin.qq.com' for _ in range(10)]
crawl = Crawler(urls)
asyncio.get_event_loop().run_until_complete(crawl.run())
if __name__ == '__main__':
main()


https://mp.weixin.qq.com https://mp.weixin.qq.com https://mp.weixin.qq.com https://mp.weixin.qq.com https://mp.weixin.qq.com https://mp.weixin.qq.com https://mp.weixin.qq.com https://mp.weixin.qq.com https://mp.weixin.qq.com https://mp.weixin.qq.com parse--- https://mp.weixin.qq.com http://www.sxmu.edu.cn/ parse--- https://mp.weixin.qq.com http://www.sxmu.edu.cn/ parse--- https://mp.weixin.qq.com http://www.sxmu.edu.cn/ parse--- https://mp.weixin.qq.com http://www.sxmu.edu.cn/ parse--- https://mp.weixin.qq.com http://www.sxmu.edu.cn/ parse--- https://mp.weixin.qq.com http://www.sxmu.edu.cn/ parse--- https://mp.weixin.qq.com http://www.sxmu.edu.cn/ parse--- https://mp.weixin.qq.com http://www.sxmu.edu.cn/ parse--- https://mp.weixin.qq.com http://www.sxmu.edu.cn/ parse--- https://mp.weixin.qq.com http://www.sxmu.edu.cn/ next parse http://www.sxmu.edu.cn/ store data: {'next_parse': URL('http://www.sxmu.edu.cn/')} next parse http://www.sxmu.edu.cn/ store data: {'next_parse': URL('http://www.sxmu.edu.cn/')} next parse http://www.sxmu.edu.cn/ store data: {'next_parse': URL('http://www.sxmu.edu.cn/')} next parse http://www.sxmu.edu.cn/ store data: {'next_parse': URL('http://www.sxmu.edu.cn/')} next parse http://www.sxmu.edu.cn/ store data: {'next_parse': URL('http://www.sxmu.edu.cn/')} next parse http://www.sxmu.edu.cn/ store data: {'next_parse': URL('http://www.sxmu.edu.cn/')} next parse http://www.sxmu.edu.cn/ store data: {'next_parse': URL('http://www.sxmu.edu.cn/')} next parse http://www.sxmu.edu.cn/ store data: {'next_parse': URL('http://www.sxmu.edu.cn/')} next parse http://www.sxmu.edu.cn/ store data: {'next_parse': URL('http://www.sxmu.edu.cn/')} next parse http://www.sxmu.edu.cn/ store data: {'next_parse': URL('http://www.sxmu.edu.cn/')} 1.517087459564209
六、自定义多线程爬虫架构
# -*- coding: utf-8 -*-
"""
@Datetime: 2019/5/1
@Author: Zhang Yafei
"""
import functools
import os
import time
from collections import Iterator
from retrying import retry
import requests
from concurrent.futures import ThreadPoolExecutor
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
class Request(object):
"""
用于封装用户请求信息所用
"""
def __init__(self, url, callback):
self.url = url
self.callback = callback
class RequestManager(object):
def __init__(self):
self.new_requests = set()
self.old_requests = set()
def has_new_request(self):
""" 判断是否有未爬取的url """
return self.new_request_size() != 0
def get_new_request(self):
""" 获取一个未爬取的请求 """
new_request = self.new_requests.pop()
# 提取之后,将其添加到已爬取的链接中
self.old_requests.add(new_request)
return new_request
def add_new_request(self, request):
""" 将新请求添加到未爬取的集合中(单个请求) """
if request is None:
return
if request not in self.new_requests and request not in self.old_requests:
self.new_requests.add(request)
def add_new_urls(self, requests):
""" 将新请求添加到未爬取的集合中(集合) """
if requests is None or len(requests) == 0:
return
for request in requests:
self.add_new_request(request)
def new_request_size(self):
""" 获取未爬取的url大小 """
return len(self.new_requests)
def old_request_size(self):
""" 获取已爬取的url大小 """
return len(self.old_requests)
class HTMLDownLoad(object):
@retry(stop_max_attempt_number=3)
def retry_download(self, url):
"""
通过装饰器封装重试下载模块,最多重试三次
:param url: 下载网页的最终地址
"""
result = requests.get(url, headers=headers, timeout=3)
assert result.status_code == 200 # 使用断言判断下载状态,成功则返回结果,失败抛出异常
return result
def download(self, url):
"""
真正的下载类,代理模式
:param url:下载的链接
"""
try:
result = self.retry_download(url)
except Exception as e: # 异常处理尽量使用具体的异常
print(e)
result = None
return result
class HTMLParser(object):
def __init__(self):
pass
def parse(self, response):
items = {}
# print(response.result())
# print(response.url)
print('parse---', response)
yield Request(url='http://www.sxmu.edu.cn/', callback=self.next_parse)
# yield items
def next_parse(self, response):
print('next parse', response.url)
items = {'next_parse': response.url}
yield items
class DataMemory(object):
def __init__(self):
pass
def store_data(self, data):
print('store data')
def to_csv(self):
pass
def to_excel(self):
pass
def save_mongo(self):
pass
def save_redis(self):
pass
def save_mysql(self):
pass
class Crawler(object):
def __init__(self, urls):
self.manager = RequestManager()
self.downloader = HTMLDownLoad()
self.parser = HTMLParser()
self.data_memory = DataMemory()
self.urls = urls
def filter_downloaded_urls(self):
return self.urls
def start(self, request):
self.manager.add_new_request(request)
while self.manager.has_new_request() and self.manager.old_request_size() < 100:
# 1. 取出新请求
new_request = self.manager.get_new_request()
print(new_request.url)
# 2. 将请求的url进行下载
response = self.downloader.download(new_request.url)
# 3. 将下载的Html文本进行解析
result = new_request.callback(response)
# 4. 判断解析之后返回的数据对象为新请求还是解析的数据
if not isinstance(result, Iterator):
raise Exception('返回的数据类型不是迭代器')
for ret in result:
if isinstance(ret, Request):
# 5. 如果是新请求,则加入到请求管理器
self.manager.add_new_request(ret)
elif isinstance(ret, dict):
# 6. 如果是解析的数据,则将数据进行存储
self.data_memory.store_data(ret)
else:
raise Exception('返回数据类型不正确,只能返回Request的实例对象或字典的实例对象')
def run(self):
url_list = self.filter_downloaded_urls()
request_lists = (Request(url, self.parser.parse) for url in url_list)
with ThreadPoolExecutor(max_workers=os.cpu_count()) as pool:
pool.map(self.start, request_lists)
def timeit(func):
""" 装饰器: 计算函数运行时间 """
@functools.wraps(func)
def inner(*args, **kwargs):
start = time.time()
ret = func(*args, **kwargs)
print(time.time() - start)
return ret
return inner
@timeit
def main():
urls = ('https://mp.weixin.qq.com' for _ in range(10))
crawl = Crawler(urls=urls)
crawl.run()
if __name__ == '__main__':
main()
https://mp.weixin.qq.com https://mp.weixin.qq.com https://mp.weixin.qq.com https://mp.weixin.qq.com parse--- <Response [200]> http://www.sxmu.edu.cn/ parse--- <Response [200]> parse--- <Response [200]> http://www.sxmu.edu.cn/ http://www.sxmu.edu.cn/ parse--- <Response [200]> http://www.sxmu.edu.cn/ next parse http://www.sxmu.edu.cn/ store data https://mp.weixin.qq.com next parse http://www.sxmu.edu.cn/ store data https://mp.weixin.qq.com next parse http://www.sxmu.edu.cn/ store data https://mp.weixin.qq.com next parse http://www.sxmu.edu.cn/ store data https://mp.weixin.qq.com parse--- <Response [200]> http://www.sxmu.edu.cn/ parse--- <Response [200]> http://www.sxmu.edu.cn/ parse--- <Response [200]> http://www.sxmu.edu.cn/ parse--- <Response [200]> http://www.sxmu.edu.cn/ next parse http://www.sxmu.edu.cn/ store data https://mp.weixin.qq.com next parse http://www.sxmu.edu.cn/ store data https://mp.weixin.qq.com next parse http://www.sxmu.edu.cn/ store data next parse http://www.sxmu.edu.cn/ store data parse--- <Response [200]> http://www.sxmu.edu.cn/ parse--- <Response [200]> http://www.sxmu.edu.cn/ next parse http://www.sxmu.edu.cn/ store data next parse http://www.sxmu.edu.cn/ store data 2.2576050758361816