有了代理池之后就可以爬很多网站了,很多网站的反爬措施都是从ip方面下手,通过代理池可以近乎拥有无穷的ip,再也不怕封ip啦
下面我找上了房天下这个网站练一下手,通过测试,这个网站的反爬措施是一旦你访问过于频繁,他就会给你一个验证码,通过了验证码才能继续浏览。由于本人水平有限,可以说破解不了任何的验证码,所以希望通过更换ip来达到目的。
首先,先来了解一下这个网站,我准备爬取二手房的数据
这个是筛选界面,由于最多只显示100页,所以通过筛选缩小范围
这个是房屋信息总览的界面,从这里获取这些房屋的链接
这个是具体的内容,可以获取具体信息
这个是翻页,这里可以查看总页数

下边是代码部分,假设代理池已经建立好,代理池的建立我前边也有写。
程序分为两个模块,第一个是获取所有房屋的链接,第二个是请求这些链接,然后把具体信息爬取出来。
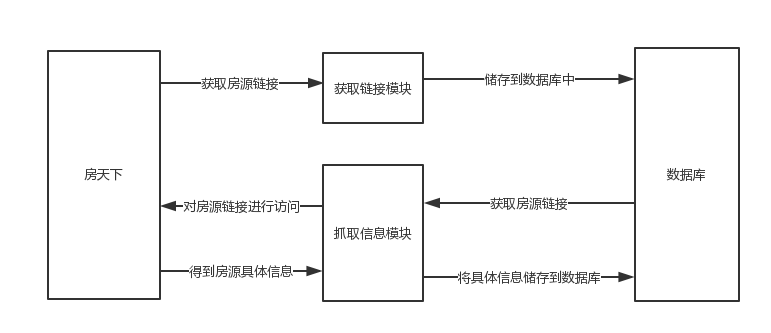
流程图如下
获取链接模块:
import requests
from lxml import etree
import time
import pymongo
class Get_url():
def __init__(self):
self.headers = {
'Cookie':'city=qhd; Integrateactivity=notincludemc; global_cookie=qcsukbug0wpm5ct4714hd1k8o1ejpxt303i; lastscanpage=0; __utmz=147393320.1545394234.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; unique_cookie=U_ag68xkap1c907mueguax03vn32xjpzcujfr*1; __utma=147393320.2031085311.1545382911.1545470150.1545476577.6; __utmc=147393320; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; __utmb=147393320.3.10.1545476577',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
self.client = pymongo.MongoClient(host='localhost',port=27017)
self.db = self.client['fangtianxia']
self.collection = self.db['house_urls']
def get_head(self,url):
html = requests.Session()
html = html.get(url=url,headers=self.headers)
html_parser = etree.HTML(html.text)
targets = html_parser.xpath('//*[@id="kesfqbfylb_A01_03_01"]/ul/li')
time.sleep(1)
for target in targets:
target_a = ''.join(target.xpath('./a/@href'))
target_a = target_a.replace(' ','')
if target_a != '':
target_url = 'http://qhd.esf.fang.com{}i3{}/'.format(target_a,{})
yield target_url
def get_lists(self,urls):
for url in urls:
time.sleep(1)
url1 = url.format(1)
html = requests.get(url=url1,headers=self.headers)
html = etree.HTML(html.text)
num = html.xpath('//*[@id="list_D10_15"]/p[3]/text()')
num = ''.join(num)
num = num[1:-1]
if num == '':
num = '1'
#print('成功获取:初始网页:{},共{}页'.format(url,num))
yield {'url':url,
'num':num}
def get_results(self,url,num):
se = requests.Session()
number = int(num)
for n in range(number):
time.sleep(1)
n += 1
url_r = url.format(n)
html = se.get(url_r)
html = etree.HTML(html.text)
houses = html.xpath('//div[@class="shop_list shop_list_4"]//dl[@dataflag="bg"]')
for house in houses:
house_url = house.xpath('./dd/h4/a/@href')
house_url = 'http://qhd.esf.fang.com{}'.format(''.join(house_url))
yield house_url
def Save_to_mongodb(self,house_urls):
for house_url in house_urls:
house_url = {
'house_url':house_url
}
self.collection.insert(house_url)
print('成功储存{}'.format(house_url))
if __name__ == '__main__':
urls = Get_url().get_head('http://qhd.esf.fang.com/')
lists = Get_url().get_lists(urls)
for list in lists:
house_urls = Get_url().get_results(list['url'],list['num'])
Get_url().Save_to_mongodb(house_urls)
__init__部分初始化了一部分参数,和定义了一个数据库的表单,用来存放链接
方法的名字起得有点随意,get_head(self,url):的目的是获取不同筛选条件下的链接,比如海港区的链接http://qhd.esf.fang.com/house-a01147/
开发区的链接http://qhd.esf.fang.com/house-a012056/,所以要先进行分类。
get_lists(self,urls):的目的是对各个分类下的页数进行统计,比如开发区一共61页,北戴河一共80页。
get_results(self,url,num):通过连接和页数,可以得到所有房屋的链接。
Save_to_mongodb(self,house_urls):将得到的链接存入到数据库之中。
抓取信息模块
import pymongo
import time
from lxml import etree
import requests
import threading
class GET_MESSAGE():
def __init__(self):
self.headers ={
"Host":"qhd.esf.fang.com",
'Cookie':'city=qhd; Integrateactivity=notincludemc; global_cookie=qcsukbug0wpm5ct4714hd1k8o1ejpxt303i; lastscanpage=0; showAdqhd=1; sf_source=; s=; __utma=147393320.2031085311.1545382911.1545656618.1545662867.10; __utmc=147393320; __utmz=147393320.1545662867.10.5.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; logGuid=7c237c12-9bbd-4158-ad34-8f54e80099c0; unique_cookie=U_9eifwoxb7qnivb3aruncxnzdk1qjq2frfn3*2; __utmb=147393320.6.10.1545662867',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'
}
self.client = pymongo.MongoClient(host="localhost",port=27017)
self.fangdb = self.client['fangtianxia']
self.url_collection = self.fangdb['house_urls']
self.message_collection = self.fangdb['house_messages']
self.proxydb = self.client['proxy']
self.use_area = self.proxydb['use_area']
def get_one_url(self):
house_url = self.url_collection.find_one()
return house_url['house_url']
def get_one_proxy(self):
proxy = self.use_area.find_one()
return proxy['dl']
def del_one_proxy(self,IP_PORT):
self.use_area.remove({'dl':IP_PORT})
print('IP{}不可用,删除IP'.format(IP_PORT))
def del_one_house_url(self,url):
self.url_collection.remove({'house_url':url})
def get_message(self):
time.sleep(1)
IP_PORT = GET_MESSAGE().get_one_proxy()
url = GET_MESSAGE().get_one_url()
proxies = {
"http":"http://{}".format(IP_PORT),
"https":"http://{}".format(IP_PORT)
}
try:
re = requests.get(url=url,headers=self.headers,proxies=proxies)
if re.status_code == 200 :
GET_MESSAGE().del_one_house_url(url)
re = re.content.decode('utf-8')
html = etree.HTML(re)
price = html.xpath('/html/body/div[5]/div[1]/div[4]/div[1]/div[1]/div[1]/i/text()')
unit_price = html.xpath('/html/body/div[5]/div[1]/div[4]/div[2]/div[3]/div[1]/text()')
house_type = html.xpath('/html/body/div[5]/div[1]/div[4]/div[2]/div[1]/div[1]/text()')
area = html.xpath('/html/body/div[5]/div[1]/div[4]/div[2]/div[2]/div[1]/text()')
direction = html.xpath('/html/body/div[5]/div[1]/div[4]/div[3]/div[1]/div[1]/text()')
layer = html.xpath('/html/body/div[5]/div[1]/div[4]/div[3]/div[2]/div[1]/text()')
decoration = html.xpath('/html/body/div[5]/div[1]/div[4]/div[3]/div[3]/div[1]/text()')
message = {
'总价':''.join(price)+'万元',
'户型':''.join(house_type),
'建筑面积':''.join(area),
'单价':''.join(unit_price),
'朝向':''.join(direction),
'层数':''.join(layer),
'装修':''.join(decoration)
}
GET_MESSAGE().save_house_message(message)
elif re.status_code == 404:
GET_MESSAGE().del_one_house_url(url)
print('网址不存在{}'.format(url))
else:
GET_MESSAGE().del_one_proxy(IP_PORT)
except:
GET_MESSAGE().del_one_proxy(IP_PORT)
GET_MESSAGE().get_message()
def save_house_message(self,house_message):
target = self.message_collection.find_one(house_message)
if target == None:
self.message_collection.insert(house_message)
print('储存{}成功'.format(house_message))
if __name__ == "__main__":
for t in range(6):
thread = threading.Thread(target=GET_MESSAGE().get_message,args=())
thread.start()
方法比较好理解,分别有获取一个房屋链接,删除一个房屋链接,获取一个代理,删除一个代理。
最主要得还是get_message(self):方法,我把流程图放出来,方便理解
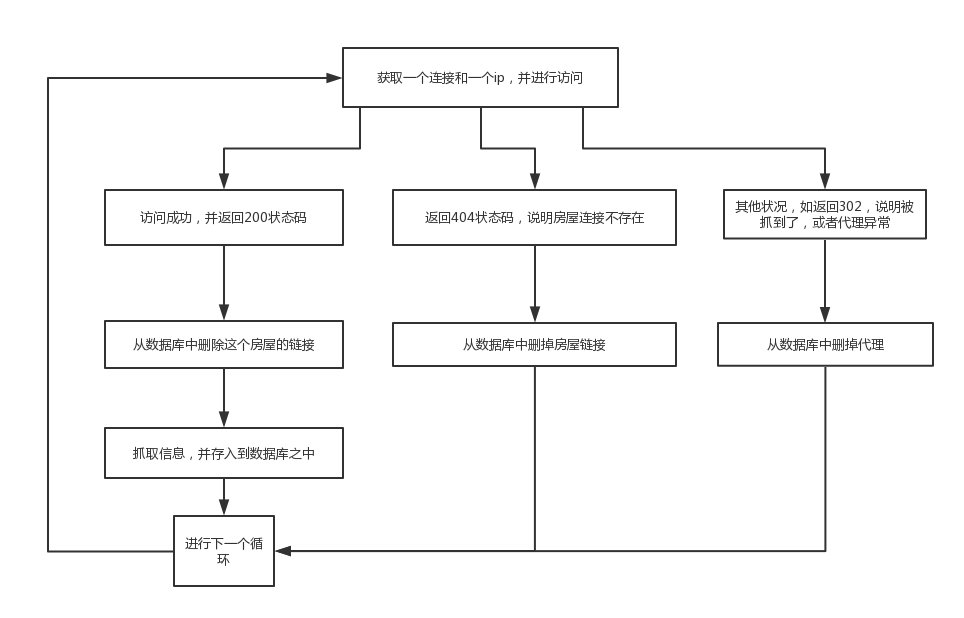
顺便再最后开启多线程,最后轻轻松松获取所有信息,不过我仍然发现了很多问题,不同线程之间有时会进行相同的操作,所以我在存储之前都会先进行查询信息是否存在,以免重复,虽然不会出错,但是这样相当于浪费了内存和网速和代理,还需要继续努力下去。