构造请求方式
下载大文件时requests参数和返回信息的处理方式与一般的有所不同
requests 模块的iter_content方法
要获取文本的时候我们通常会使用response.text获取文本信息,使用response.content获取字节流,比如下载图片保存到一个文件。
而对于大个的文件我们就要采取分块读取的方法。
request.get() 方法的 stream参数
api中的参数说明
:param stream: (optional) ifFalse, the response content will be immediately downloaded.
requests.get(url, steam=True)
默认情况下是stream的值为false,它会立即开始下载文件并存放到内存当中,倘若文件过大就会导致内存不足的情况.
当把get函数的stream参数设置成True时,它不会立即开始下载,当你使用iter_content或iter_lines遍历内容或访问内容属性时才开始下载。需要注意一点:文件没有下载之前,它也需要保持连接。
r = requests.get(url_file, stream=True)
f = open("file_path", "wb")
for chunk in r.iter_content(chunk_size=512):
if chunk:
f.write(chunk)
上面的代码表示请求了url_file,这个url_file是一个大文件,所以开启了stream模式,然后通过迭代r对象的iter_content方法,同时指定chunk_size=512(即每次读取512个字节)来进行读取。但是如果仅仅是迭代是不行,如果下载中途出现问题我们之前的努力就白费了,所以我们需要做到一个断点续传的功能。
断点续传
所谓断点续传,也就是要从文件已经下载的地方开始继续下载。在以前版本的 HTTP 协议是不支持断点的,HTTP/1.1 开始就支持了。一般断点下载时会用到 header请求头的 Range 字段,这也是现在众多号称多线程下载工具(如 FlashGet、迅雷等)实现多线程下载的核心所在。
HTTP请求头Range
range是请求资源的部分内容(不包括响应头的大小),单位是byte,即字节,从0开始.如果服务器能够正常响应的话,服务器会返回 206 Partial Content 的状态码及说明.如果不能处理这种Range的话,就会返回整个资源以及响应状态码为 200 OK .(这个要注意,要分段下载时,要先判断这个)
- Range请求头格式
Range: bytes=start-end - Range头域
Range头域可以请求实体的一个或者多个子范围。例如,
表示头500个字节:bytes=0-499
表示第二个500字节:bytes=500-999
表示最后500个字节:bytes=-500
表示500字节以后的范围:bytes=500-
第一个和最后一个字节:bytes=0-0,-1
同时指定几个范围:bytes=500-600,601-999
例如
Range: bytes=10- :第10个字节及最后个字节的数据
Range: bytes=40-100 :第40个字节到第100个字节之间的数据.
下载实例
下面我们通过具体的代码去进一步了解一些细节。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/4/30 20:47
# @Author : Paulson
# @File : demo.py
# @Software: PyCharm
# @define : function
import os
import requests
from tqdm import tqdm
def down_from_url(url, dst):
response = requests.get(url, stream=True) # (1)
file_size = int(response.headers['content-length']) # (2)
if os.path.exists(dst):
first_byte = os.path.getsize(dst) # (3)
else:
first_byte = 0
if first_byte >= file_size: # (4)
return file_size
header = {"Range": f"bytes={first_byte}-{file_size}"}
pbar = tqdm(total=file_size, initial=first_byte, unit='B', unit_scale=True, desc=dst)
req = requests.get(url, headers=header, stream=True) (5)
with open(dst, 'ab') as f:
for chunk in req.iter_content(chunk_size=1024): (6)
if chunk:
f.write(chunk)
pbar.update(1024)
pbar.close()
return file_size
url = "https://pic.ibaotu.com/00/51/34/88a888piCbRB.mp4"
down_from_url(url, "测试视频.mp4")
下面我们开始解读标有注释的代码:
tqdm是一个可以显示进度条的包,具体的用法可以参考
官网文档
(1)设置stream=True参数读取大文件。
(2)通过header的content-length属性可以获取文件的总容量。
(3)获取本地已经下载的部分文件的容量,方便继续下载,当然需要判断文件是否存在,如果不存在就从头开始下载。
(4)本地已下载文件的总容量和网络文件的实际容量进行比较,如果大于或者等于则表示已经下载完成,否则继续。
(5)开始请求视频文件了
(6)循环读取每次读取一个1024个字节,当然你也可以设置512个字节

效果展示
首先调用上面的方法并传入参数。
- 这里的url是视频的链接,访问该链接可以直接观看视频。这里是 ‘.mp4’ 结尾。
url = "https://pic.ibaotu.com/00/51/34/88a888piCbRB.mp4"
down_from_url(url, "测试视频.mp4")
下载展示
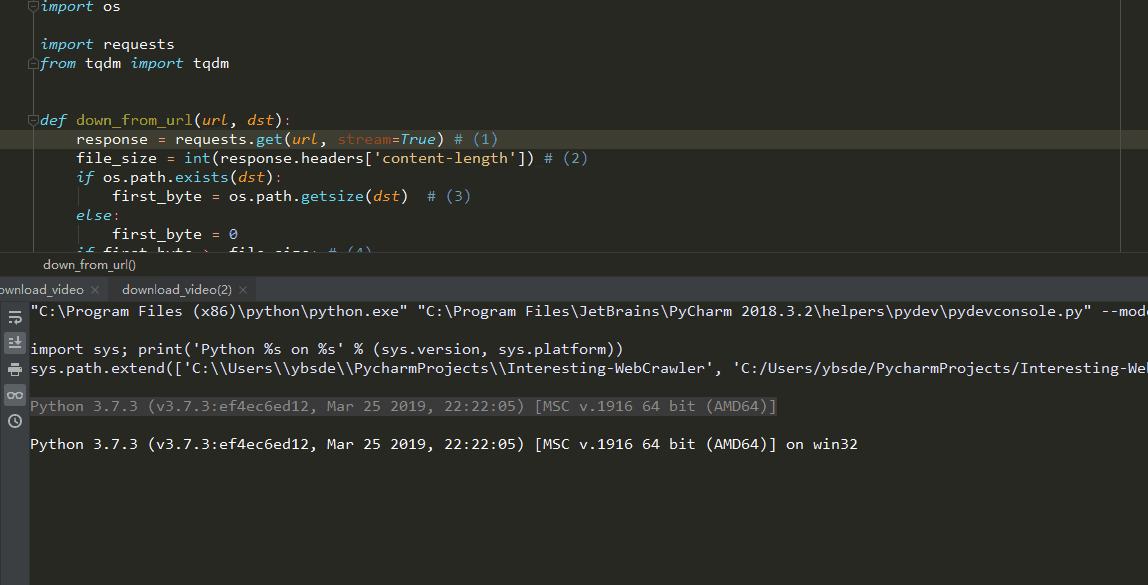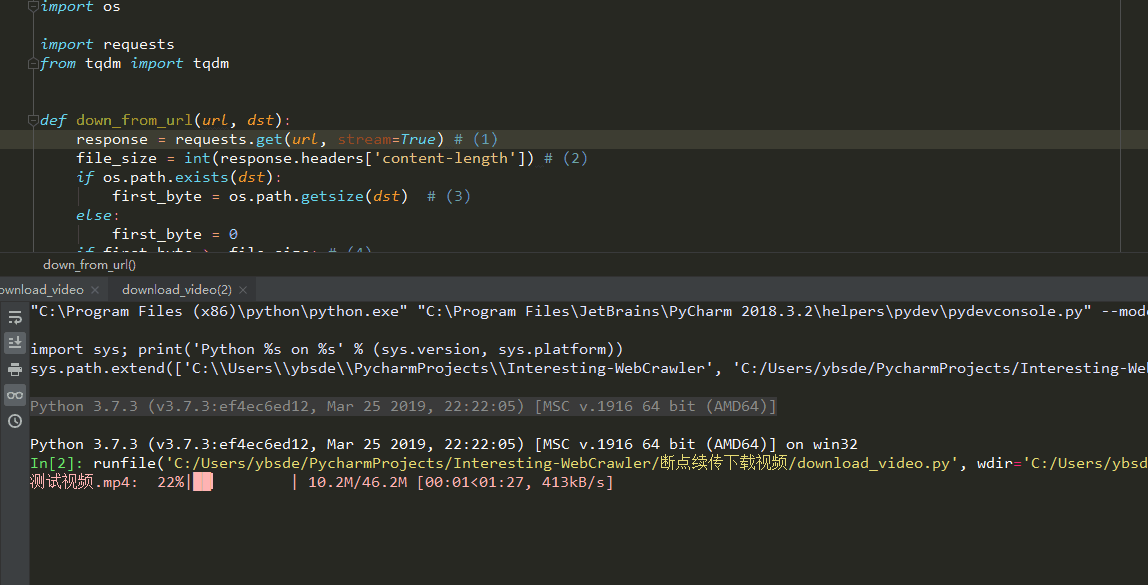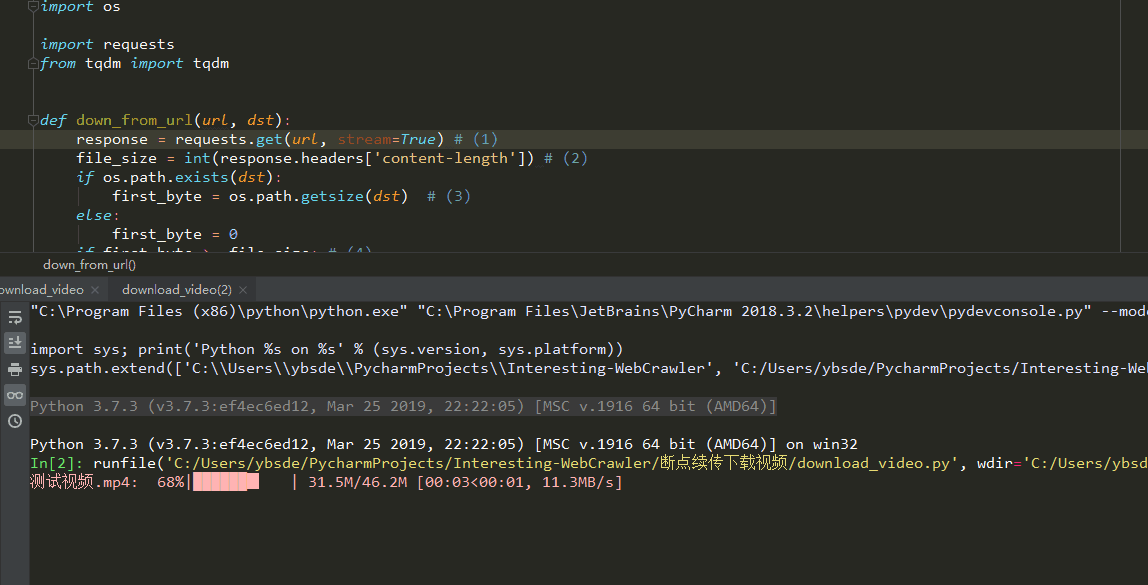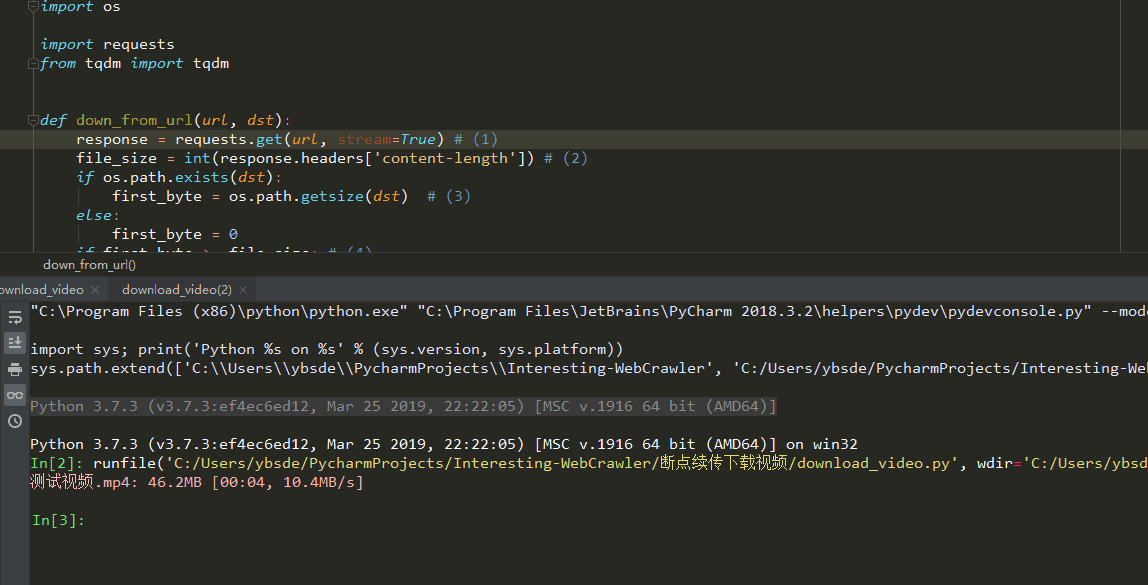
- 谢谢star
github项目地址
github代码地址