作为实践篇的最后一篇,我们将介绍如何用Python完成一个简易的问答程序。下图是demo的展示效果:
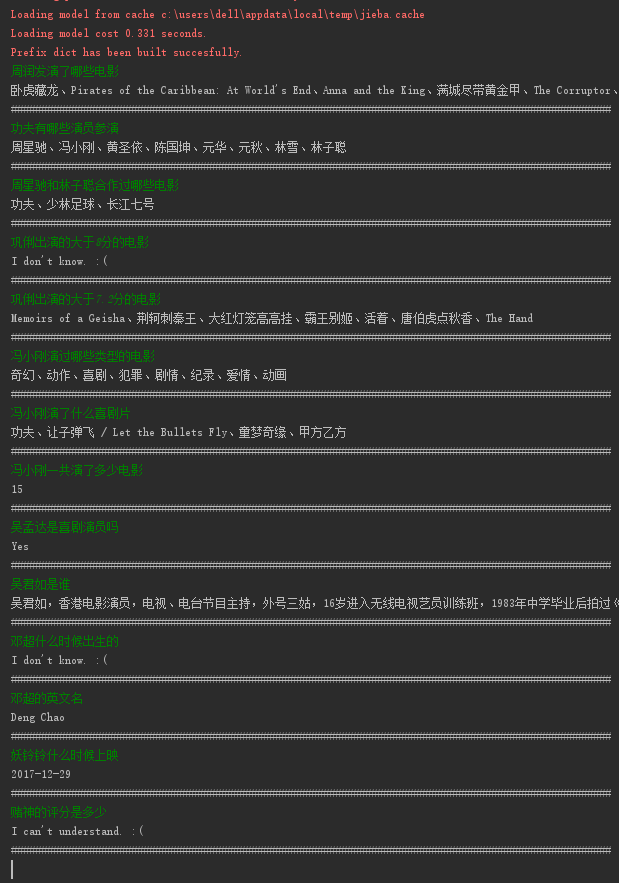
查询结果为空,回答“I don't know.”;不能理解问句,回答“I can't understand.”。本实现参考了王昊奋老师发布在OpenKG上的demo“基于REfO的KBQA实现及示例”,读者也可以参考此示例,来完成本demo。下面谈谈本demo的流程。
一、基本流程
此demo是利用正则表达式来做语义解析。我们需要第三方库来完成初步的自然语言处理(分词、实体识别),然后利用支持词级别正则匹配的库来完成后续的语义匹配。
分词和实体识别(人名和电影名)我们用jieba来完成。jieba是一个轻量级的中文分词工具,有多种语言的实现版本。对于分词,在实验环境中,jieba还是勉强能用。在我们这个demo当中,有些经常会被使用的词语并不能被正确切分。比如:“喜剧电影”、“恐怖电影”、“科幻电影”、“喜剧演员”、“出生日期”等,在分词的时候,jieba把它们当作一个词来处理,我们需要手动调整词语的频率使得“喜剧电影”能被切分为“喜剧”和“电影”。至于实体识别,jieba对于人名的识别精度尚可接受,但是电影名称的识别精度太低以至于完全不可用。因此,我们直接把数据库中的人名和电影名导出,作为外部词典;使用jieba的时候加载外部词典,这样就能解决实体识别的问题。
将自然语言转为以词为基础的基本单位后,我们使用REfO(Regular Expressions for Objects)来完成语义匹配。具体实现请参考OpenKG的demo或者本demo的代码。
匹配成功后,得到其对应的我们预先编写的SPARQL模板,再向Fuseki服务器发送查询,最后将结果打印出来。
二、代码文件说明
代码已放到github中,本项目的目录结构如下:
kg_demo_movie/
crawler/
movie_crawler.py
__init__.py
tradition2simple/
langconv.py
traditional2simple.py
zh_wiki.py
__init__.py
KB_query/
jena_sparql_endpoint.py
query_main.py
question2sparql.py
question_temp.py
word_tagging.py
external_dict/
csv2txt.py
movie_title.csv
movie_title.txt
person_name.csv
person_name.txt
__init__.py- "crawler"文件夹包含的是我们从"The Movie DB"获取数据的脚本。
- "KB_query"文件夹包含的是完成整个问答demo流程所需要的脚本。
- "external_dict"包含的是人名和电影名两个外部词典。csv文件是从mysql-workbench导出的,按照jieba外部词典的格式,我们将csv转为对应的txt。
- "word_tagging",定义Word类的结构(即我们在REfO中使用的对象);定义"Tagger"类来初始化词典,并实现自然语言到Word对象的方法。
- "jena_sparql_endpoint",用于完成与Fuseki的交互。
- "question2sparql",将自然语言转为对应的SPARQL查询。
- "question_temp",定义SPARQL模板和匹配规则。
- "query_main",main函数。
在运行"query_main"之前,读者需要启动Fuseki服务,具体方法请参考上一篇文章。
三、总结
我们通过使用正则表达式的方式来解析自然语言,并将解析的结果和我们预定义的模板进行匹配,最后实现一个简易的KBQA。方法没有大家想象的那么“高大上”,没有统计方法、没有机器学习也没有深度学习。正则的好处是,易学,从事相关行业的人基本都了解这个东西;其次,可控性强或者说可解释性强,如果某个问题解析错误,我们只要找到对应的匹配规则进行调试即可;最后,正则冷启动比较容易,在没有数据或者数据极少的情况下,我们可以利用正则规则马上上线一个类似上述demo的初级的问答系统。在现实情况中,由于上述优点,工业界也比较青睐用正则来做语义解析。正则方法的缺陷也是显而易见的,它并不能理解语义信息,而是基于符号的匹配。换个角度说,用正则的方法,就需要规则的设计者能够尽可能考虑到所有情况,然而这是不可能的。暂且不考虑同义词、句子结构等问题,光是罗列所有可能的问题就需要花费很大的功夫。尽管如此,在某些垂直领域,比如“音乐”,“电影”,由于问题集合的规模在一定程度上是可控的(我们基本能将用户的问题划定在某个范围内),正则表达式还是有很大的用武之地的。在冷启动一段时间,获得了一定用户使用数据之后,我们可以考虑引入其他的方法来改善系统的性能,然后逐渐减少正则规则在整个系统中的比重。如果读者想深入研究KBQA,可以参考专栏“揭开知识库问答KB-QA的面纱”,该专栏的作者详细介绍了做KBQA的方法和相关研究。
这个系列的实践也告一段落了。希望通过实践,读者能够进一步理解知识图谱的相关概念。