实现一个cache 缓存,实现可过期被清除的功能
简化设计,函数的形参定义不包含可变位置参数、可变关键词参数和keyword-only参数
可以不考虑缓存大小,也不用考虑缓存满了之后的换出问题
编写的函数,满足:
def add(x=4, y=5):
time.sleep(3)
return x + y
以下6种,可以认为是同一种调用
print(1, add(4,5))
print(2, add(4))
print(3, add(y=5))
print(4, add(x=4,y=5))
print(5, add(y=5,x=4))
print(6, add())
分析:
数据类型的选择
缓存的应用场景,是有数据需要频繁查询,且每次查询都需要大量计算或者等待时间之后才能返回结果的情况,使
用缓存来提高查询速度,用内存空间换取查询、加载的时间。
cache应该选用什么数据结构?
便于查询的,且能快速获得数据的数据结构。
每次查询的时候,只要输入一致,就应该得到同样的结果(顺序也一致,例如减法函数,参数顺序不一致,结果不
一样)
基于上面的分析,此数据结构应该是字典。
通过一个key,对应一个value。
key是参数列表组成的结构,value是函数返回值。难点在于key如何处理。
key的存储
key必须是hashable。
key能接受到位置参数和关键字参数传参。
位置参数是被收集在一个tuple中的,本身就有顺序。
关键字参数被收集在一个字典中,本身无序,这会带来一个问题,传参的顺序未必是字典中保存的顺序。如何解
决?
- OrderedDict行吗?可以,它可以记录顺序。
- 不用OrderedDict行吗?可以,用一个tuple保存排过序的字典的item的kv对。
key的异同
什么才算是相同的key呢?
import time
import functools
@functools.lru_cache()
def add(x,y):
time.sleep(3)
return x+ys
定义一个加法函数,那么传参方式就应该有以下4种:
1. add(4, 5)
2. add(4, y=5)
3. add(y=5, x=4)
4. add(x=4, y=5)
上面4种,可以有下面几种理解:
第一种:1、2、3、4都不同。
第二种:3和4相同,1、2和3都不同。
第三种:1、2、3、4全部相同。
lru_cache实现了第一种,从源码中可以看出单独的处理了位置参数和关键字参数。
但是函数定义为def add(4, y=5),使用了默认值,如何理解add(4, 5)和add(4)是否一样呢?
如果认为一样,那么lru_cache无能为力。
就需要使用inspect来自己实现算法。
key的要求
key必须是hashable。
由于key是所有实参组合而成,而且最好要作为key的,key一定要可以hash,但是如果key有不可hash类型数据,
就无法完成。
lru_cache就不可以,我们也很难实现,所以不能在实参中出现不可hash类型。
key算法设计
inspect模块获取函数签名后,取parameters,这是一个有序字典,会保存所有参数的信息。
构建一个字典params_dict,按照位置顺序从args中依次对应参数名和传入的实参,组成kv对,存入params_dict
中。
kwargs所有值update到params_dict中。
如果使用了缺省值的参数,不会出现在实参params_dict中,会出现在签名的parameters中,缺省值也在函数定义
中。
调用的方式
普通的函数调用可以,但是过于明显,最好类似lru_cache的方式,让调用者无察觉的使用缓存。
构建装饰器函数。
代码实现:
首先我们使用python自带的lru_cache模块进行编写:
#系统自带的lru_cache 模块
import functools
import time
@functools.lru_cache()
def add(x=4,y=5):
time.sleep(2)
return x+y
print(1, add(4,5))
print(2, add(4))
print(3, add(y=5))
print(4, add(x=4,y=5))
print(5, add(y=5,x=4))
print(6, add())
其运行的结果如下图所示:
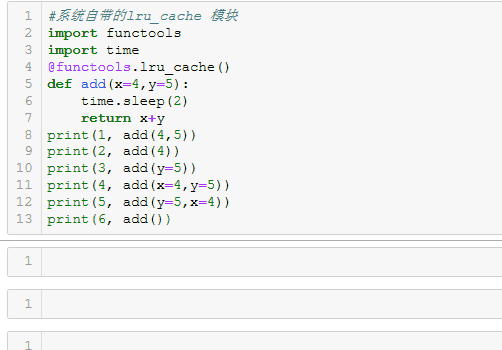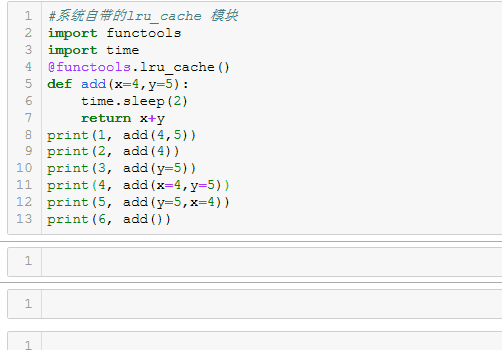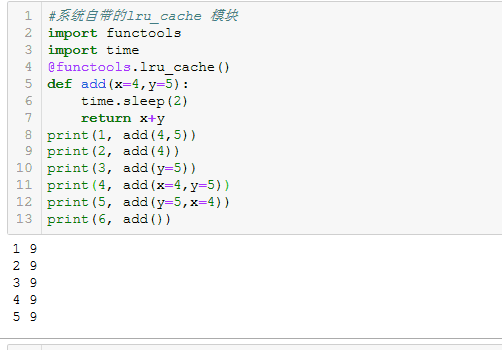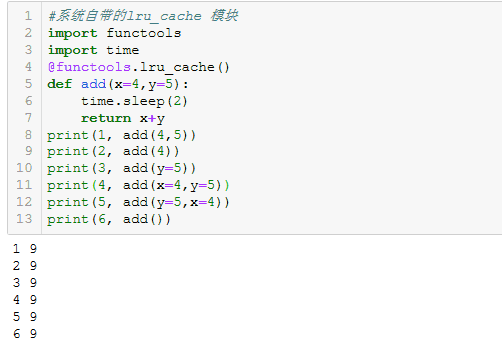
理论上来说,传入的参数都是一致的,但是为什么每次运算时未能调用cache呢?
主要是cache内部调用时并未对带缺省值函数也进行统计,所以不能实现我们想要的功能?那这需求能否实现呢?当然是肯定的.
接下来我们使用自己写的代码来实现所需功能
方法一:手动创建字典的key,value值
from functools import wraps
import time # 时间sleep
import inspect #提取函数的缺省值
import datetime # 就算时间delta
#######################################
def logger(fn):
@wraps(fn) # 更新函数的属性
def wrapper(*args,**kwargs):
start = datetime.datetime.now()
ret = fn(*args,**kwargs)# fn 调用的是cache\wrapper(4,5)
delta = (datetime.datetime.now()-start).total_seconds()
print(fn.__name__, delta) # 打印原函数的标识符与计算使用时间
return ret
return wrapper
#时间计算代码块
#########################################
def cache(fn):
local_cache = {}
@wraps(fn)
def wrapper(*args,**kwargs):
sig = inspect.signature(fn) # 得到函数的签名
params= sig.parameters
print(params)
target = {}
#字典更新方法一:
# # name = list(params.keys())
# # for i,v in enumerate(args):
# # target[name[i]]= v
## target.update(kwargs)
# target.update(zip(params.keys(),args) # 解决顺序传参
# target.update(kwargs) # 注意update函数 ,上下两行可以直接合并为一行
#字典更新放法二:
target.update(zip(params.keys(),args),**kwargs)
###############上面解决了传参的问题,但是若传参为add(),add(x=5),缺省数据,这时需要补缺省值
# 缺省值更新字典的放法一:
# for k ,v in params.items():
# if k not in target.keys():
# target[k]=v.default # 不存在缺省值则返回inspect_empty
# 缺省值更新字典的放法二:
## for k in (params.keys()-target.keys()):
## target[k]=v.default
# 缺省值更新字典的放法三:
## target.update(((k,v.default)for k,v in params.items()if k not in target.keys()))
# 缺省值更新字典的放法四:
target.update(((k,params[k].default)for k in (params.keys()-target.keys())))
# 转换成生成器表达式生成一个二元组,用生成的二元组惰性求值,然后字典更新.
key =tuple( sorted(target.items()))#sorted 返回值是一个列表,这里需要二元组排序,所以要用items()
if key not in local_cache: # 如果不在缓存中就就算,在就不计算
local_cache[key]=fn(**target)
return local_cache[key]
# ret = fn(**target) # 正常计算是用函数调用ret函数
# 目前字典内都是一一配对的,将参数解构到对应值.
## ret = fn(*args,**kwargs)原始
# return ret
return wrapper
#cache缓存代码块
############################################################
@logger # add = logger(add) add = logger(cache\wrapper) -->add=logger\wrapper
@cache #--->add = cache(add) add-->cache|wrapper
# 装饰器的顺序是由近及远,由下向上,顺序位置不能错. 11点45 时间,重新理解
#add(4,5) add=cache(add)(4,5)
# cache|wrapper(4,5)
# logger(cache|wrapper) =>logger\wrapper(4,5)
def add(x=4,y=5):
time.sleep(2)
return x+y
# add(4,5) #---> cache\wrapper(4,5)
print(add(4,5))
print(add(x=4,y=5))
上面已经完成了cache缓存系统了,下面需要增加缓存清除功能:
记录时间的字典可以与目前的字典使用同一个,也可以创建一个新的,这样在新的字典中得到的key来移除缓存字典里的数据
#添加自动清除缓存
from functools import wraps
import time
import inspect
import datetime
def logger(fn):
@wraps(fn)
def wrapper(*args,**kwargs):
start = datetime.datetime.now()
ret = fn(*args,**kwargs)# cache\wrapper(4,5)
delta = (datetime.datetime.now()-start).total_seconds()
print(fn.__name__, delta)
return ret
return wrapper
def cache(duration = 5):
def _cache(fn):
local_cache = {}
@wraps(fn)
def wrapper(*args,**kwargs):
expire_keys = [] # 采用的是懒策略,当数据量大时不是最好的解决方案
now = datetime.datetime.now().timestamp() # 这里用的时时间戳,得到的是一个浮点数,所以可以相减
# for k,(_,timestamp) in local_cache.items():# 创建好不能在改变,所以不能用pop
# if now - timestamp> duration: #这里的减法得到的可能是复数 一:虚拟机,二:时间未校准有可能出现时间不准确,
# expire_keys.append(k)
for k in [k for k ,(_,timestamp)in local_cache.items()if now -timestamp > duration]:
local_cache.pop(k)
sig = inspect.signature(fn) # 得到函数的签名
params= sig.parameters
print(params)
target = {}
target.update(zip(params.keys(),args),**kwargs)
target.update(((k,v.default)for k in (params.keys()-target.keys())))
key =tuple( sorted(target.items()))
if key not in local_cache:
local_cache[key]=fn(**target),datetime.datetime.now().timestamp()
#字典的value会是一个元组
return local_cache[key]
return wrapper
return _cache
@logger
@cache() #带参装饰器
def add(x=4,y=5,z=6):
time.sleep(6)
return x+y
print(add(4,5))
print(add(4,5))
print(add(x=4,y=5))
上面的代码已经能完成基本的过期清除缓存的功能,在后期学习中还会使用更加高级的方法对缓存过期清除.下面简单的测试一下,通过更改清除默认时间值,看看能否达到需求:
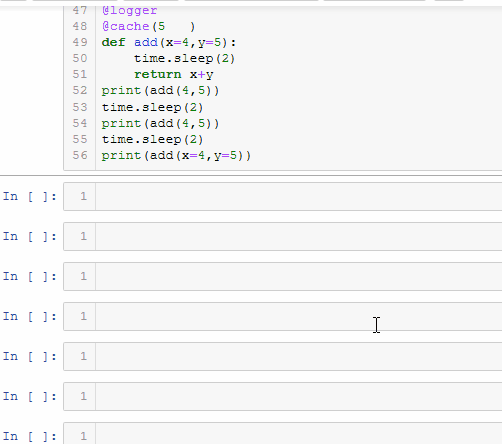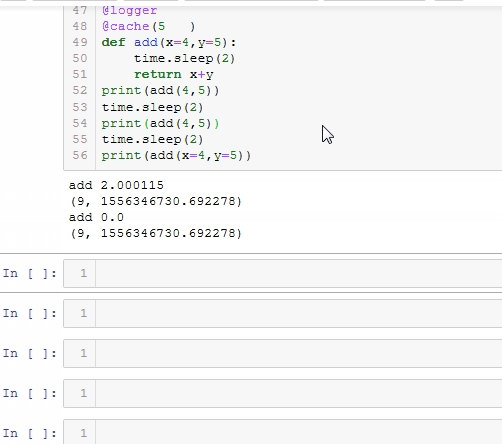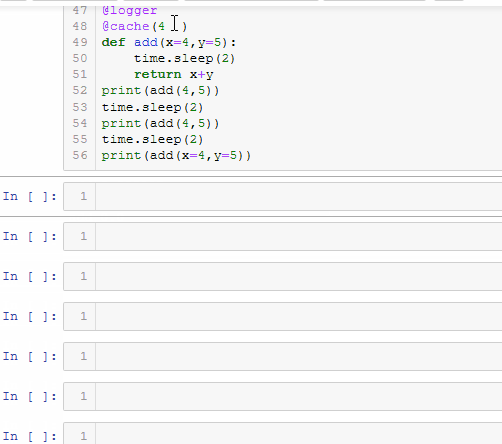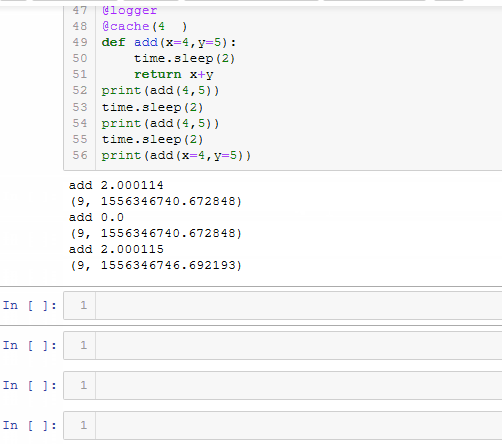
重图中可以看出,在更改默认清除缓存时间后,函数add的运行时间发生了改变,说明缓存清理起了作用.
最后对函数进行相应的美化,将函数内部定功能段提取到函数外部,既可以节省空间,减少函数定义占用的内存,同时代码可读性增强.
# 添加自动清除缓存
import functools
from functools import wraps
import time
import inspect
import datetime
def logger(fn):
@wraps(fn)
def wrapper(*args, **kwargs):
start = datetime.datetime.now()
ret = fn(*args, **kwargs) # cache\wrapper(4,5)
delta = (datetime.datetime.now() - start).total_seconds()
print(fn.__name__, delta)
return ret
return wrapper
def _clear_expires(cache, duration): # 含数放到外部,内部在调用时就不在需要再次创建,减少内存损耗
now = datetime.datetime.now().timestamp()
for k in [k for k, (_, timestamp) in cache.items() if now - timestamp > duration]:
cache.pop(k)
def _make_key(fn,args, kwargs):
sig = inspect.signature(fn) # 得到函数的签名
params = sig.parameters
target = {}
target.update(zip(params.keys(), args), **kwargs)
target.update(((k, v.default) for k in (params.keys() - target.keys())))
key = tuple(sorted(target.items()))
return key,target
def cache(duration=6):
def _cache(fn):
local_cache = {}
@wraps(fn)
def wrapper(*args, **kwargs):
#清除缓存过期数据
_clear_expires(local_cache, duration)
#创建key
key,target= _make_key(fn,args, kwargs)
if key not in local_cache:
local_cache[key] = fn(**target), datetime.datetime.now().timestamp()
return local_cache[key]
return wrapper
return _cache
@logger
@cache()
def add(x=4, y=5):
time.sleep(2)
return x + y
print(add(4, 5))
time.sleep(2)
print(add(4, 5))
time.sleep(2)
print(add(x=4, y=5))
方法二:使用有序字典的方式
对创建字典部分进行修改
def _make_key(fn,args, kwargs):
sig = inspect.signature(fn) # 得到函数的签名
params = sig.parameters
target = OrderedDict()
target.update(zip(params.keys(), args))
for k ,v in params.items():
if k not in target.keys():
if k in kwargs:
target[k]=kwargs[k]
else:# 顺序和关键词传参都没有
target[k]= v.default
key = tuple(target.items())# 有序字典不需要排序
过期功能
一般缓存系统都有过期功能。
过期什么?
它是某一个key过期。可以对每一个key单独设置过期时间,也可以对这些key统一设定过期时间。
本次的实现就简单点,统一设定key的过期时间,当key生存超过了这个时间,就自动被清除。
注意:这里并没有考虑多线程等问题。而且这种过期机制,每一次都要遍历所有数据,大量数据的时候,遍历可能有效率问题。
在上面的装饰器中增加一个参数,需要用到了带参装饰器了。
@mag_cache(5) 代表key生存5秒钟后过期。
带参装饰等于在原来的装饰器外面在嵌套一层。
清除的时机
何时清除过期key?
1、用到某个key之前,先判断是否过期,如果过期重新调用函数生成新的key对应value值。
2、一个线程负责清除过期的key,这个以后实现。本次在创建key之前,清除所有过期的key。
value的设计
1、key => (v, createtimestamp)
适合key过期时间都是统一的设定。
2、key => (v, createtimestamp, duration)
duration是过期时间,这样每一个key就可以单独控制过期时间。在这种设计中,-1可以表示永不过期,0可以表示
立即过期,正整数表示持续一段时间过期。
本次采用第一种实现。
装饰器的用途
装饰器是AOP面向切面编程 Aspect Oriented Programming的思想的体现。
面向对象往往需要通过继承或者组合依赖等方式调用一些功能,这些功能的代码往往可能在多个类中出现,例如:
logger功能代码。这样造成代码的重复,增加了耦合。logger的改变影响所有使用它的类或方法。
而AOP在需要的类或方法上切下,前后的切入点可以加入增强的功能。让调用者和被调用者解耦。
这是一种不修改原来的业务代码,给程序动态添加功能的技术。例如logger函数就是对业务函数增加日志的功能,
而业务函数中应该把与业务无关的日志功能剥离干净。
装饰器应用场景
日志、监控、权限、审计、参数检查、路由等处理。
这些功能与业务功能无关,是很多业务都需要的公有的功能,所以适合独立出来,需要的时候,对目标对象进行增
强。