规格定义
目前,AnalyticDB for PostgreSQL 支持如下两种实例规格:
-
高性能:规格简称为“n x m C SSD”,n代表单分区(segment)分配的CPU核数,m代表该计算组的总分区数,规格全称以 gpdb.group.segsdx 开始,特点是可以提供更好的 I/O 能力,带来更高的分析性能。
-
高容量:规格简称为“n x m C HDD”,n代表单分区(segment)分配的CPU核数,m代表该计算组的总分区数,规格全称以 gpdb.group.seghdx开始,,特点是可以提供更大、更实惠的空间,满足更高的存储需求。
因此,在选择实例规格时,建议您根据需要的存储空间和计算能力进行选择。同时,AnalyticDB for PostgreSQL 支持基于 OSS 的外部表扩展,并可通过 gzip 实现外部存储上的数据压缩,不需要参与实时计算的数据可以存放到外部存储以进一步节省存储成本。
规格详情
高性能实例的规格信息如下表所示:
| 【高性能】计算组规格简称 | 【高性能】计算组规格全称 | CPU | 内存 | 存储空间 | 规格说明 |
|---|---|---|---|---|---|
| 1x1C SSD | gpdb.group.segsdx1 | 1 Core | 8 GB | 80 GB SSD | 1个数据分区(segment),每个分区1CPU核 |
| 1x2C SSD | gpdb.group.segsdx2 | 2 Cores | 16 GB | 160 GB SSD | 2个数据分区(segment),每个分区1CPU核 |
| 1x16C SSD | gpdb.group.segsdx16 | 16 Cores | 128 GB | 1.28 TB SSD | 16个数据分区(segment),每个分区1CPU核 |
| 4x4C SSD (高并发场景规格) |
gpdb.group.segsd4cx4 | 16 Cores | 128 GB | 1.28 TB SSD | 4个数据分区(segment),每个分区4CPU核 |
高容量型实例的规格信息如下表所示:
| 【高容量】计算组规格简称 | 【高容量】计算组规格全称 | CPU | 内存 | 存储空间 | 规格说明 |
|---|---|---|---|---|---|
| 2x2 HDD | gpdb.group.seghdx4 | 4 Cores | 32 GB | 2 TB HDD | 2个数据分区(segment),每个分区2CPU核 |
| 2x18 HDD | gpdb.group.seghdx36 | 36 Cores | 288 GB | 18 TB HDD | 18个数据分区(segment),每个分区2CPU核 |
价格信息详情,参见 产品定价。
规格选型
对于性能优先类场景,建议以 SSD 高性能规格建分析数据仓库集群,对于以数据存储类优先的场景,可以考虑 HDD 高容量规格。 AnalyticDB for PostgreSQL 采用 MPP 全对等并行架构,数据处理能力随计算组增加线性增长,可以保证相同的响应 RT 时间。如下所示,随着计算组增加,可以保证同样查询的相同计算分析时间。
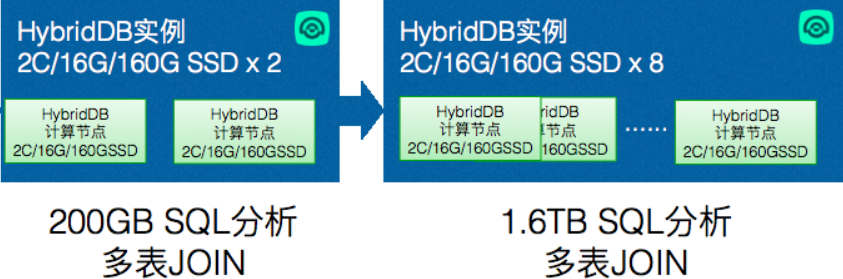
集群规格选型可以参照原始数据量及应用场景,选择合适的计算组数量,构建MPP分析集群。
1、有一定并发度的简单查询场景,或者有较多数据更新操作 (INSERT/UPDATE/DELETE ),建议数据采用行存储。对 1TB 原始数据,一般入库后考虑索引等,数据库数据还是在 1TB 左右,考虑到计算过程中会产生临时文件,日志等,建议按 2TB 的物理存储空间来规划集群的计算组数量。如果查询性能要求较高,可以增加计算组数量,提升查询性能。
2、批处理 ETL场景,其数据较少更新操作(UPDATE/DELETE),同时全表数据聚合关联操作较多,建议数据采用列存储。对 1TB 原始数据,列存储具备2-5倍的高压缩比,入库后数据库存储在 0.5TB 以内,建议按 1TB 的物理存储空间来规划集群的计算组数量。
参见 产品定价,已经提供了一些常用计算组集群规格组合速查表。对于超过控制台自助创建页面的计算组数量,可以通过提工单或者联系销售代表申请创建。