文章目录
主要对《数学之美》隐马尔科夫模型,维特比和他的维特比算法、《统计学习方法》第十章、 徐亦达HMM概率模型的内容进行总结消化。
隐马尔科夫模型(HMM)最初应用于通信领域,继而推广到语音和语言处理中,成为连接自然语言处理和通信的桥梁,也是机器学习的主要工具之一。因为觉得数学之美的科普性很高很好理解,所以我先从吴军博士提到的自然语言处理模型说起,然后对后面的公式推导进行整理。
一 自然语言处理与隐马尔科夫模型(HMM)
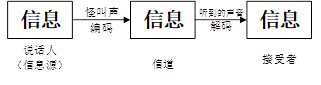
上图表示最原始的通信模型,一般现在通信模型包含信源,信道,接收者,信息,上下文和编码,发送者对信息上下文进行编码得到一种能够在信道中传播的信号,比如语音或者电话线的调制信号,假设信息发送的信息是
,然后通过媒体传播到接收方,接接收端接收到的信号是
,在接收方,根据事先约定好的方法,将编码的信号还原成发送的消息。
而自然语言处理也可以理解成一个通信系统。语音识别,实际上就是听着对介质传播过来的声音进行大脑解码,猜测说话者要表达的意思,这个过程也就是通信系统中接受端根据接收到的信号去分析、理解、还原发送端传送过来的信息。
在通信系统中,只需要从所有源信息中找到最可能产生观测信号
的那一个信息,也就是根绝观测信号来推测信号源发送的信息
了。用概率论语言来描述也就是,在已知
的情况下,求得令条件概率
达到最大值的信息串
。
从这个角度看,围绕HMM有三个基本的问题
- 概率计算问题:给定一个模型,如何计算某个特定的输出序列的概率,即 , 表示给定的模型的参数--------第三节HMM的概率计算方法
- 学习问题:给定足够的观测数据,如何估计HMM的参数,即用最大似然法估计参数--------第四节HMM的学习算法
- 解码问题:给定一个模型和某个特定的输出序列,如何找到最可能产生这个输出序列的状态序列,即求 --------第五节HMM预测算法,这里的预测就可以理解成解码出最有可能的原始信息,就是语音识别得到最终结果的过程
二 隐马尔科夫模型(HMM)基本概念
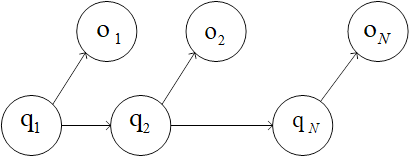
HMM是可用于标注问题的关于时序的模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列(上图第二行)----->称为状态序列,再由各个状态生成一个观测而产生观测随机序列(上图第一行)------>称为观测序列,的过程。【序列的每一个位置可以看作一个时刻】。注:标注问题是给定观测的序列预测其对应的标记序列
首先,HMM是基于两个基本假设的
- 齐次马尔可夫性假设,即假设隐藏的马尔可夫链在任意时刻 的状态只依赖于前一时刻的状态,与其他时刻的状态及观测无关,也与时刻 无关
- 观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测状及状态无关。
HMM由初始概率分布、状态转移概率分布以及观测概率分布确定,符号定义形式如下

HMM模型可以用一个三元符号定义 ,三个符号分别表示HMM的三个要素,是HMM求解的参数。其中状态转移矩阵 ,初始概率分布 确定了隐藏的马尔可夫链,生成不可观测的状态序列,观测矩阵B确定了如何从状态生成观测,即 。
三 HMM概率计算方法(前向算法与后向算法简化)
首先我们需要明确的是,概率计算是在知道模型参数
和观测序列
的条件下,计算产生该观测序列的概率,即
,最直接的方法就是应用概率计算公式进行推导,从上一节EM算法的总结中我们知道了隐变量这个概念,引入隐变量的一个条件就是不影响原来的边缘分布,也就是对隐变量进行积分能够将隐变量积分掉。在这个问题中,我们知道生成状态序列的概率,从状态序列产生观测序列的概率,以及初始概率分布,但是就是不知道那个状态学列是什么。这就可以看作概率计算中的一个隐变量,于是根据概率计算公式就有如下表达:
在模型训练计算参数
的时候,我们需要的是最大化似然函数,也就是
,如果是上述概率计算公式的话,计算量非常大,是
,实现上是不可行的,因此发展出如下有效算法。
3.1 前向算法

如上图,引自徐亦达老师HMM的课件,左边表示前向算法,右边表示后向算法,为保持符号一致,输出序列改为
表示。
前向概率定义:给定HMM模型
,定义到时刻
部分观测序列为
,且状态为
的概率为前向概率,记作
注意,这只是一个定义,根据这个定义可以递归求得前向概率
以及观测序列概率

所以根据这个递推公式,我们只需要先计算初值
然后对
根据递推公式进行递推,最后对所有可能的初始状态进行积分就可以得到
。
3.2 后向算法
后向概率定义:给定HMM模型
,定义在时刻
状态为
的条件下,从
到T的部分观测序列
的概率为后向概率:
同理,这也只是一个定义,根据该定义可以递推

四 HMM的学习算法(模型训练求解模型参数)
第一种直接运用概率计算,但是需要大量的标记数据,代价很大,因此最常用的还是EM算法,在这里叫做Baum-Welch算法,看书就可以看到这里和上一节总结的EM算法十分相似,并且这里的隐变量实际上已经给出就是 ,看书完全能明白,就不做总结了。
五 HMM预测算法(维特比算法)
维特比算法是一个特殊但是应用最广的动态规划算法,利用动态规划可以解决任何一个图中的最短路径问题。维特比算法是针对一个特殊的图——篱笆网络的有向图最短路径问题提出的。他之所以重要,是因为凡是使用HMM描述的问题都可以用它来解码,包括今天的数字通信,语音识别,机器翻译,拼音转汉字,分词等等。
统计学习方法中根据前向和后向算法推导了单个输出的最大可能概率,但是我们需要预测最可能的一个状态序列,所以整个问题就变成
这时,我们是有观测序列的,但是我们不知道状态序列,也就是每个状态
实际上可能有N个取值,为了简化,我们取几个进行说明,这个优化问题可以展开成一个篱笆网络
从第一个状态到最后一个状态的任何一条路径都可能产生我们观察到额输出序列
,这些路径的可能性可能不一样,我们要做的就是周到最可能的这条路径。维特比提出了一种与状态数目成正比的算法。
其基础可以概括为三点
- 如果概率最大的路径P经过某个点,如 ,那么这条路径上从起点S到 的这一段子路径Q一定是起始点到 的最短路径,否则,用最短路径R代替Q,便构成一条比P更短的路径,这是矛盾的。
- 从起点S到终点E必定经过 时刻的某个状态,假设 时刻有K个状态,那么如果记录了从S到第 个状态所有K个节点的最短路径,最终的最短路径必定经过其中一条。——这样,在任何时刻,只要考虑非常有限条候选路径即可。
- 结合上面两点,如果从状态
到状态
时,从S到状态
上各个节点的最短路径已经找到,并且记录在这些节点上,那么在计算从起点S到
状态的某个节点的最短路径时,只要考虑从S到前一个状态
所有K个节点的最短路径,以及从这K个节点到
的距离即可。
用公式表示为:

六 课后习题
# -*-coding:utf-8-*-
import numpy as np
def sum(L):
sumValue = 0.0
for i in range(0, len(L)):
sumValue += L[i]
return sumValue
def max(L):
target = 0
maxValue = L[target]
for i in range(1, len(L)):
if (L[i] > maxValue):
target = i
maxValue = L[i]
return maxValue, target + 1
def printTable(table, type="float"):
if (type == "float"):
for i in range(0, len(table)):
for j in range(0, len(table[i])):
print ("%-16f" % (table[i][j]),)
print ("\n")
elif (type == "int"):
for i in range(0, len(table)):
for j in range(0, len(table[i])):
print ("%-2d" % (table[i][j]),)
print ("\n")
def initTable(x, y, type="float"):
table = []
if (type == "float"):
initValue = 0.0
elif (type == "int"):
initValue = 0
for i in range(0, x):
temp = []
for j in range(0, y):
temp.append(initValue)
table.append(temp)
return np.array(table)
def forwardV(A, B, pi, Object, mod="forward"):
T = len(Object)
NumState = len(A)
NodeTable = initTable(NumState, T)
if (mod == "viterbi"):
NodePath = initTable(NumState, T, type="int")
for i in range(0, NumState):
NodeTable[i][0] = pi[i] * B[i][Object[0]]
for t in range(1, T):
for j in range(0, NumState):
temp = []
for i in range(0, NumState):
temp.append(NodeTable[i][t - 1] * A[i][j] * B[j][Object[t]])
if (mod == "forward"):
NodeTable[j][t] = sum(temp)
elif (mod == "viterbi"):
NodeTable[j][t], NodePath[j][t] = max(temp)
if (mod == "forward"):
print (u"前向算法alpha值记录表:")
printTable(NodeTable)
p = 0.0
for i in range(0, NumState):
p += NodeTable[i][T - 1]
return NodeTable, p
elif (mod == "viterbi"):
print (u"viterbi算法结点值记录表:")
printTable(NodeTable)
print (u"viterbi算法路径记录表:")
printTable(NodePath, type="int")
target = 0
maxValue = NodeTable[target][T - 1]
for i in range(1, NumState):
if NodeTable[i][T - 1] > maxValue:
target = i
maxValue = NodeTable[i][T - 1]
print (u"viterbi算法最终状态:", target + 1, "\n")
StateSequeues = [0] * T
StateSequeues[T - 1] = target + 1
for i in range(1, T):
StateSequeues[T - i - 1] = NodePath[StateSequeues[T - i] - 1][T - i]
return StateSequeues
def backward(A, B, pi, Object):
T = len(Object)
NumState = len(A)
NodeTable = initTable(NumState, T)
for i in range(0, NumState):
NodeTable[i][T - 1] = 1
for t in range(1, T):
for i in range(0, NumState):
temp = []
for j in range(0, NumState):
temp.append(NodeTable[j][T - t] * A[i][j] * B[j][Object[T - t]])
NodeTable[i][T - t - 1] = sum(temp)
print (u"后向算法beta值记录表:")
printTable(NodeTable)
p = 0.0
for i in range(0, NumState):
p += pi[i] * B[i][Object[0]] * NodeTable[i][0]
return NodeTable, p
# ---------------------------------------------------------------------#
# forwardV函数实现前向算法和viterbi算法
# backward函数实现后向算法的计算
# 前向后向结合计算特殊点概率,只需取两个记录表中相应的alpha和beta值即可
# ---------------------------------------------------------------------#
print (u"习题10.1和10.3")
A1 = [[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]]
B1 = [[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]
pi1 = [0.2, 0.4, 0.4]
Object1 = [0, 1, 0, 1]
# 习题10.1
table, P = backward(A1, B1, pi1, Object1)
print (u"(10.1)通过后向算法计算可得 P(O|lambda)=", P, "\n")
# 习题10.3
I = forwardV(A1, B1, pi1, Object1, mod="viterbi")
print (u"(10.3)通过viterbi算法求得最优路径 I=", I, "\n")
print (u"#-----------------------------------------------------#")
# ---------------------------------------------------------------------#
print (u"习题10.2")
A2 = [[0.5, 0.1, 0.4], [0.3, 0.5, 0.2], [0.2, 0.2, 0.6]]
B2 = [[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]
pi2 = [0.2, 0.3, 0.5]
Object2 = [0, 1, 0, 0, 1, 0, 1, 1]
F, pf = forwardV(A2, B2, pi2, Object2, mod="forward")
B, pb = backward(A2, B2, pi2, Object2)
# 习题10.2
# P(i4=q3|O,lambda)=P(i4=q3,O|lambda)/P(O|lambda)=alpha4(3)*beta4(3)/P(O|lamda)
# pf=pb,任选一个
# 1-based索引转换为0-based索引
print (u"P(O|lambda)=", pf)
P2 = F[3 - 1][4 - 1] * B[3 - 1][4 - 1] / pf
print (u"(10.2)通过前向后向概率计算可得 P(i4=q3|O,lambda)=", P2, "\n")
10.4 试用前向概率和后向概率推导

10.5 比较维特比算法中变量
的计算和前向算法中变量
。
计算变量α的时候直接对上个的结果进行数值计算,而计算变量δ需要在上个结果计算的基础上选择最大值。