Lua源码笔记–字符串
与大多数语言一样,Lua的字符串类型的实现主要有两个数据:字符串的首地址和字符串长度。也有自已的一些特点:
- Lua的字符串类型是可以被自动回收的。
- Lua把所有的字符串都存放在一个全局的Hash表中。
1. 存储结构
下面是字符串数据结构的定义(展开原有的宏以及省略了一些字段):
@(简化后)
typedef union TString {
struct {
GCObject *next;
lu_byte tt;
lu_byte marked;
lu_byte reserved;
unsigned int hash;
size_t len;
} tsv;
} TString;
- tt: Lua把所有类型弄成了一个Object的通用类型,因此需要一个字段来指示类型。
- reserved: 指示是否为系统保留字段。
- hash: 字符串哈希值
- len: 字符串长度
上面的数据结构中并没有看到存字符串内容的地方或指向字符串内容的指针,其实存放字符串真实内容的内存就紧挨着这个结构体。如下源码,在申请内存的时候直接把数据结构的存储数据的内存一起申请了:
ts = cast(TString *, luaM_malloc(L, (l+1)*sizeof(char)+sizeof(TString)));
简化起来看就是:
---------------
| TString |
--------------- 连续内存块
| data |
---------------
2. 全局字符串表
Lua把所有的字符串都存在一个全局表里面,当要创建一个字符串(从C字符串创建Lua字符串)时,会先看全局表时面有没有,如果有则直接引用全局表的字符串,如果没有就新创建一个,并插入全局表。
a = "123"
b = "123"
a, b引用全局表的同一个字符串。
a = "123"
a = a .. "4"
新创建一个"1234"的字符串,并插入全局表,而不是把原有的"123"字符串改写成"1234"。这个"123"字符串如果长时间没有被引用,就会被垃圾回收器回收。
全局表是一个Hash表结构,这个Hash表解决冲突的方式是拉链法,即将相同Hash值相同的字符串用链表连起来。
全局Hash结构(假设桶有32个):
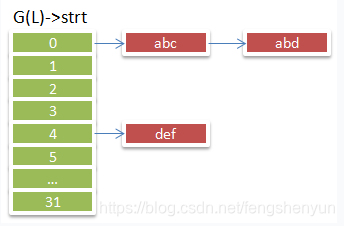
Hash算法:
h = hash(s) % size
假设有三个字符串:“abd”,“abc”,“def”:
hash(“abd”) % 32 = 0, "abd"被存放到桶0处。
hash(“abc”) % 32 = 0,“abc”也要存放到桶0处,但已有一个字符串,就直接插到链首。
hash(“def”) % 32 = 4,“def”被存放到桶0处。
这个桶大小并不是一直不变的,当数据量非常大时,分配到每个桶上的数据会非常多,这样每次查找遍历的链会很长,导致查找效率低。为了避免这种情况,在数据非常大时要扩张Hash表的桶,而当数据量变小时,要缩小桶大小。
初始化时桶大小:
#define MINSTRTABSIZE 32
桶扩张
当全局Hash表的字符串太多时,为了提高查询效率,会将Hash表扩张一倍。
触发条件: 当前字符串数 > 桶大小
桶收缩
当全局Hash表字符串被大量回收时,为了节约内存,会将Hash表缩小一倍。
触发条件: 当前字符串数 < 桶大小 * 0.25
3. 源码详解
新建一个字符串
创建一个字符串,即通过一个C风格字符串创建一个Lua字符串。在创建之前,先从全局表里面查找字符串是否已存在,如果已存在则直接将字符串引用返回,如果不在存则新创建一个字符串并返回。
TString *luaS_newlstr (lua_State *L, const char *str, size_t l) {
// 计算哈希值
unsigned int h = cast(unsigned int, l); /* seed */
size_t step = (l>>5)+1; /* if string is too long, don't hash all its chars */
size_t l1;
for (l1=l; l1>=step; l1-=step) /* compute hash */
h = h ^ ((h<<5)+(h>>2)+cast(unsigned char, str[l1-1]));
// 查找哈希表有没有,有则返回
for (o = G(L)->strt.hash[lmod(h, G(L)->strt.size)]; o != NULL; o = o->gch.next) {
TString *ts = rawgco2ts(o);
if (ts->tsv.len == l && (memcmp(str, getstr(ts), l) == 0)) {
return ts;
}
}
// 新建一个字符串,并插入到Hash表
return newlstr(L, str, l, h);
}
创建一个字符串
具体创建字符串代码,字符串数据结构和内容分配在一块内存上,避免内存碎片,释放时也一起释放。字符串内容兼容了C风格,以’\0’结尾。创建完成后插入到全局表。如果刚好触发了桶大小扩张,则要把桶大小重新调整。
static TString *newlstr (lua_State *L, const char *str, size_t l, unsigned int h) {
// 分配内存
ts = cast(TString *, luaM_malloc(L, (l+1)*sizeof(char)+sizeof(TString)));
// 填充TString
ts->tsv.len = l;
ts->tsv.hash = h;
ts->tsv.marked = luaC_white(G(L));
ts->tsv.tt = LUA_TSTRING;
ts->tsv.reserved = 0;
// 拷贝字符串内容,以 '\0' 结尾
memcpy(ts+1, str, l*sizeof(char));
((char *)(ts+1))[l] = '\0';
// 将字符串插入到Hash表
tb = &G(L)->strt;
h = lmod(h, tb->size);
ts->tsv.next = tb->hash[h]; /* chain new entry */
tb->hash[h] = obj2gco(ts);
tb->nuse++;
// 检查Hash表,如果已用的String对象大于桶大小,则将桶大小扩张一倍
if (tb->nuse > cast(lu_int32, tb->size) && tb->size <= MAX_INT/2)
luaS_resize(L, tb->size*2); /* too crowded */
return ts;
}
删除一个字符串
Lua垃圾回收会将没有引用的TString对象回收掉。
触发桶缩容源码
GC垃圾回收时会触发桶缩容。
static void checkSizes (lua_State *L) {
...
if (g->strt.nuse < cast(lu_int32, g->strt.size/4) &&
g->strt.size > MINSTRTABSIZE*2)
luaS_resize(L, g->strt.size/2); /* table is too big */
...
}
桶大小调整源码
重新分配一个新的桶,再把原有桶里面的字符串重新rehash到新的桶里面,再释放掉旧的桶。当全局表字符串数据大时,rehash操作是非常耗性能的。
void luaS_resize (lua_State *L, int newsize) {
// 新建一个哈希表
newhash = luaM_newvector(L, newsize, GCObject *);
tb = &G(L)->strt;
for (i=0; i<newsize; i++) newhash[i] = NULL;
// 将旧哈希表中的字符串rehash
for (i=0; i<tb->size; i++) {
GCObject *p = tb->hash[i];
while (p) { /* for each node in the list */
GCObject *next = p->gch.next; /* save next */
unsigned int h = gco2ts(p)->hash;
int h1 = lmod(h, newsize); /* new position */
lua_assert(cast_int(h%newsize) == lmod(h, newsize));
p->gch.next = newhash[h1]; /* chain it */
newhash[h1] = p;
p = next;
}
}
// 释放掉旧哈希表的内存
luaM_freearray(L, tb->hash, tb->size, TString *);
// 重置哈希表大小和首地址
tb->size = newsize;
tb->hash = newhash;
}