1.安装spark
1.1从git或者官网下载安装包
1.2解压安装包
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz
注意:这里我是直接放在hadopp用户下解压的。
1.3修改配置文件
第一个文件: log4j.properties
cp log4j.properties.templatelog4j.properties
vi log4j.properties
添加以下内容
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.MaxFileSize=20000KB
log4j.appender.file.MaxBackupIndex=100
log4j.appender.file.File=/app/hadoop/spark/logs/spark.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{yyyy-MM-ddHH\:mm\:ss}%n[%p]-[Thread\: %t]-[%C.%M()]\: %m%n
第二个文件:spark-env.sh
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
添加以下内容
exportHADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop
exportJAVA_HOME=/home/ideal/jdk/jdk1.8.0_60
export SPARK_WORKER_MEMORY=4g
第三个文件:spark-defaults.conf
cp spark-defaults.conf.templatespark-defaults.conf
不用修改
第四个文件:slaves
cp slaves.template slaves
添加以下内容
mqtt-1
mqtt-3
注意:这里是配置spark的节点。
第五个文件:hive-site.xml
这个文件直接从hadoop的配置文件复制过来就ok
vi hive-site.xml
cp/home/haoop/hadoop/etc/hadoop/hive-site.xml /home/hadoop/spark/conf
不用修改内容
第六个文件:hdfs-site.xml
这个文件直接从hadoop的配置文件复制过来就ok
cp/home/haoop/hadoop/etc/hadoop/hdfs-site.xml /home/hadoop/spark/conf
不用修改内容
以上六个文件修改完毕后,把整个spark目录copy给节点服务器。
scp -r spark 用户名@主机名:/home/hadoop/spark
2.启动spark
2.1 启动hive
启动metastore
nohup ./bin/hive --service metastore
2.2启动hiveserver2
nohup ./bin/hiveserver2>logs/start_hiveserver2.log 2>&1 &
2.3 启动spark
./sbin/start-all.sh
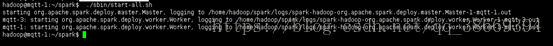
3.验证spark
浏览器输入:服务器地址:端口号
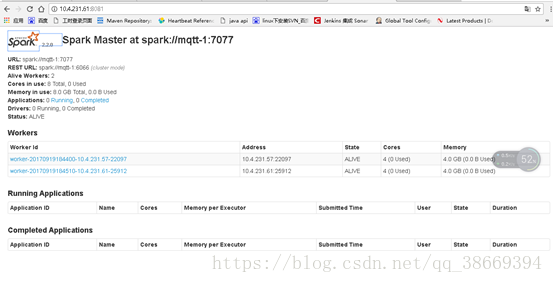
成功!