一,Xception
Xception是在InceptionV3基础上修改的,主要引入了深度可分离卷积,将空间和通道的操作进行解耦合。

与“extreme” Inception两个区别:
1,1×1卷积的顺序,Xcption用于3×3之后,而Inception用于之前
2,Xception在1×1和3×3之后都没用relu,而Inception都用了。
3*3做空间相关性,1×1做通道相关性。

![]()
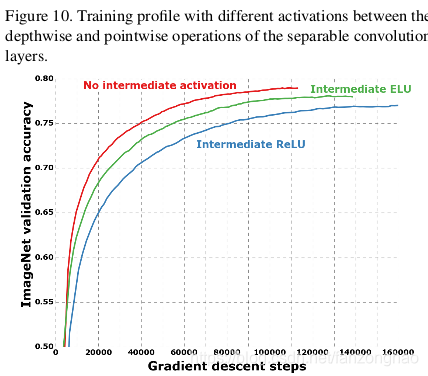
用Relu会损失一部分信息。


二,Inception-ResNet
证明了Residual learning并非深度网络走向更深的必需条件,其只是可以使得深度网络的训练速度加快而已。为了表明这一点,他们更是造出了更为复杂、精巧的Inception v4网络,在不使用residual learning的情况下也达到了与Inception-Resnet v2近似的精度。

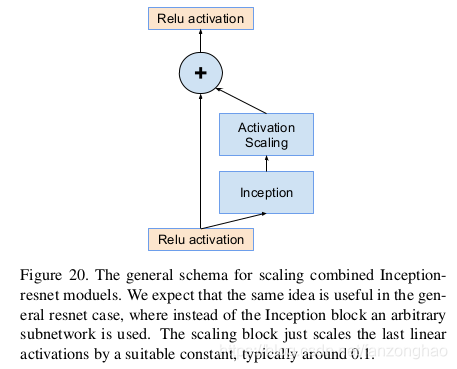
如果通道数超过1000,那么Inception-resnet等网络都会开始变得不稳定,并且过早的就“死掉了”,即在迭代几万次之后,平均池化的前面一层就会生成很多的0值。作者们通过调低学习率,增加BN都没有任何改善。实验发现如果对inception-resnet网络中的residual模块的输出进行scaling(如乘以0.1-0.3),那么可以让它的整个训练过程更加地稳定。如下图为scaling的具体做法示意。
三,SENet
SEnet最终目的是给各个channel增加权重,注意于通道之间的关系,2017年ILSVRC分类第一。
通过精确的建模卷积特征各个通道之间的作用关系来改善网络模型的表达能力。为了达到这个期望,提出了一种能够让网络模型对特征进行校准的机制,使网络从全局信息出发来选择性的放大有价值的特征通道并且抑制无用的特征通道。


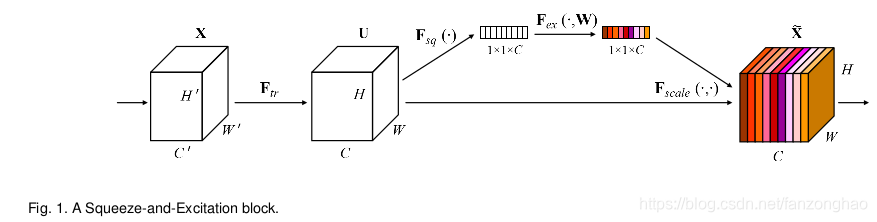
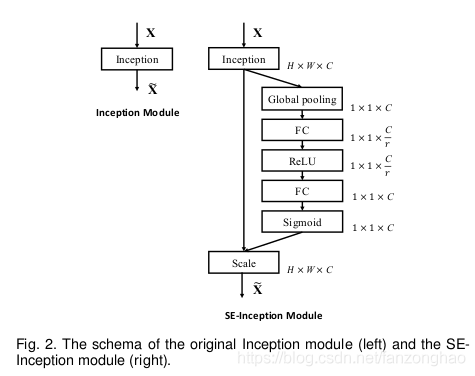
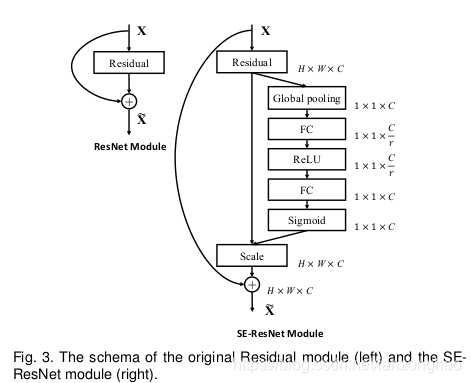
模型复杂度:当r=16时,SE-ResnNet相比ResNet-50参数量仅增加0.26%。

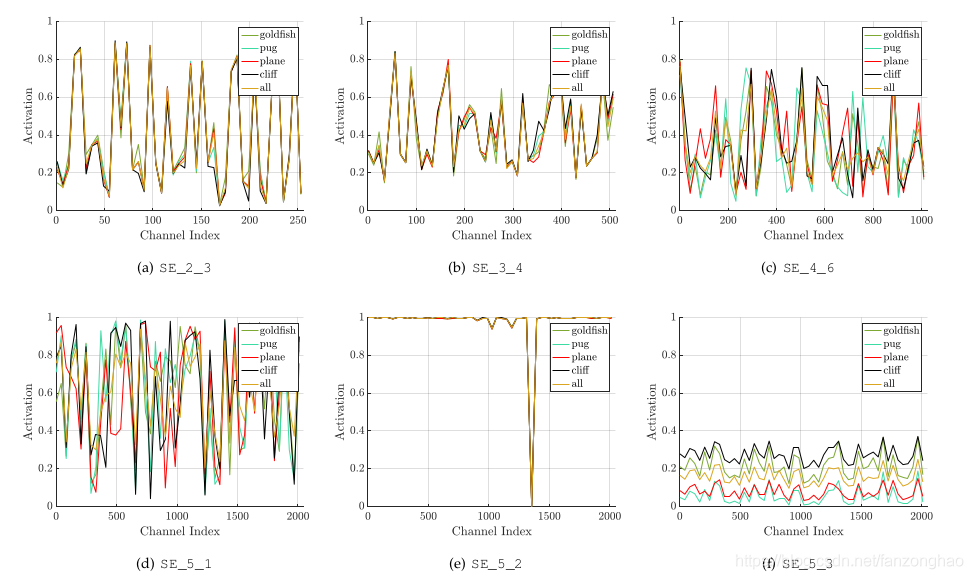
本节我们研究SE-ResNet-50模型的样本激活,并考察它们在不同块不同类别下的分布情况。具体而言,我们从ImageNet数据集中抽取了四个类,这些类表现出语义和外观多样性,即金鱼,哈巴狗,刨和悬崖。然后,我们从验证集中为每个类抽取50个样本,并计算每个阶段最后的SE块中50个均匀采样通道的平均激活(紧接在下采样之前),并在图7中绘制它们的分布。作为参考,我们也绘制所有1000个类的平均激活分布。


我们对SENets中Excitation的作用提出以下三点看法。首先,不同类别的分布在较低层中几乎相同,例如,SE_2_3。这表明在网络的最初阶段特征通道的重要性很可能由不同的类别共享。然而有趣的是,第二个观察结果是在更大的深度,每个通道的值变得更具类别特定性,因为不同类别对特征的判别性值具有不同的偏好。SE_4_6和SE_5_1。这两个观察结果与以前的研究结果一致[21,46],即低层特征通常更普遍(即分类中不可知的类别),而高层特征具有更高的特异性。因此,表示学习从SE块引起的重新校准中受益,其自适应地促进特征提取和专业化到所需要的程度。最后,我们在网络的最后阶段观察到一个有些不同的现象。SE_5_2呈现出朝向饱和状态的有趣趋势,其中大部分激活接近于1,其余激活接近于0。在所有激活值取1的点处,该块将成为标准残差块。在网络的末端SE_5_3中(在分类器之前紧接着是全局池化),类似的模式出现在不同的类别上,尺度上只有轻微的变化(可以通过分类器来调整)。这表明,SE_5_2和SE_5_3在为网络提供重新校准方面比前面的块更不重要。这一发现与第四节实证研究的结果是一致的,这表明,通过删除最后一个阶段的SE块,总体参数数量可以显著减少,性能只有一点损失(<0.1%0.1%的top-1错误率)。