初步理解nginx 进程管理
niginx启动后会有一个master和多个worker进程。master进程主要用来管理worker 进程。包括:接受外界信号,向各worker进程发送信号,监控worker进程的运行状态,当worker进程退出后(异常情况下),会自动重启新的worker进程。而基本的网络事件,则是在worker进程中处理。多个worker进程之间是对等的,他们的同等竞争来自客户端的请求,但他们之间又是相互对立的。一个请求只能在一个worker进程中处理,一个worker进程不可能处理其他进程的请求。worker进程的个数是可以设置。一般会和机器的CPU个数设置一致(这里的原因是和nginx的进程模型以及事件处理模型分不开的)。
nginx 的进程模型如下图:
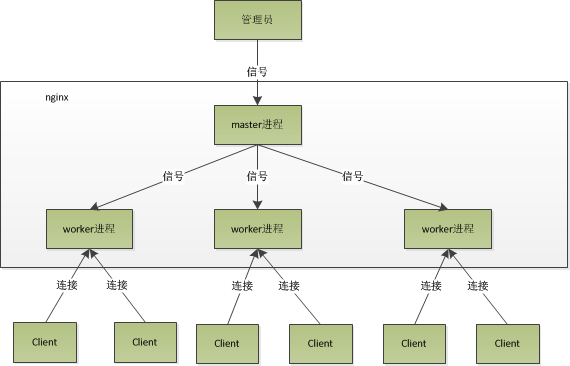
在nginx 启动后,管理nginx 只需要与master 进程通信就好了。master进程会接受来自外界信号。再根据信号做不同的事情。所以控制nginx只需要 kill master 进程发信号就可以了(如:kill -HUP pid 则是重启 nginx )。
简单描述一下重启nginx后的进程状态:当重启nginx后,master在接到信号后,会重现加载配置文件,然后启动新的worker进程,并告诉旧的worker进程,他们可以下岗了。新的worker在启动后,就开始接受新的请求,而老的worker就不再接受请求,而当前进程在所有未处理完的请求处理完成后退出。
那么nginx 内部是如何处理请求的呢? 每个worker进程都是从master进程fork(叉分)过来的。在master进程里面,先建立号需要listen和socket(listenefd)之后,然后再fork 多个work 进程。所有worker进程的listenfd会在新的连接到来的时候变得可读,为保证只有一个进程处理该连接,所有worker进程在注册listenefd 读事件前抢 accept_mutex , 抢到互斥锁的那个进程注册listenefd读事件,在读事件里调用accept接受该连接。当一个worker进程在accept这个进程后,就开始读取请求,处理请求,产生数据后 ,再返回个客户端,最后才断开连接,这样一个完整的请求就是这样了。
上面阐述了nginx进程模型,那么nginx是如何处理事件的。
nginx 采用了异步非阻塞的方式来处理请求,即nginx是可以同时处理成千上万个请求的。
现在来看一个完整的请求过程。首先,请求过来,要建立连接,然后再接受数据,接受数据后,再发送数据,具体到系统底层,就是读写事件,而当读写事件没有准备好时,必然不可操作,如果不用非阻塞的方式来调用,那就的阻塞调用了,事件没有准备好,那就只能等用,cpu利用率自然就下来了,更不可能高并发了。所有,在nginxl里面,最忌讳阻塞的系统调用了,不要阻塞即非阻塞了。非阻塞就是,事件没有准备好,马上返回EAGEAIN(eagin),表示事件还没有准备好,过会再来,再检查一下事件,直到事件准备好了为止,虽然不阻塞,但要时不时检查一下事件的状态,所以才有了事件处理机制,具体到系统调用就像 /select/poll/epoll/kqueue 这样的系统调用。他们提供了一种机制,可以同时监控多个事件,调用他们是阻塞的,但可以设置超时时间,在超时时间之内,如果有事件准备好了,就返回。当然线程的个数只有一个,所以同时能处理的请求只有一个,只是在请求间进程不断的切换而已,切换也是因为异步事件未准备好,而主动让出的。这里的切换是没有任何代价。也可以理解为循环多个准备好的事件。与多线程相比,这种事件处理方式是有很大优势的。不需要创建线程,每个请求占用的内存也很小,处理的事件也非常的轻量级。并发的数量再多也不会导致无谓的资源浪费。
对于一个基本的web服务器来说,事件通常有三种模型,网络事件,信号,定时器。 网络事件通过异步阻塞的方式可以很好的解决。就剩下定时器和信号了。信号 ,特定的信号代表着特殊的意义。信号会中断掉当前程序的运行,在改变状态后,继续执行。如果只是系统调用。则可能会导致系统调用失败。所以信号处理后续学习。定时器,在事件准备的时候,可以设置一个超时时间的,在算出等待的超时时间后进入事件处理状态。所以,当没有事件产生,也没有中断信号时,等待处理的事件会超时 ,这是就有了定时器事件了。这时,nginx 会检查所有的超时事件,讲他们设置为超时,然后在处理网络事件。所以在吃力网络事件的回调函数的时,通常第一件事情就是判断超时,然后处理网络事件。