基于AMP的GPU并行计算
AMP简介
C++AMP (C++ Accelerated Massive Parallelism)利用并行硬件(例如独立图形加速卡)的性能,加速你C++程序的执行速度,C++ AMP编程模型包括支持多维数组,索引,内存传输和平铺,包括数学函数库。你可以使用C++ AMP更广泛的控制CPU同GPU之间数据的传递。
注意:C++ AMP要求你的显卡完整支持DirectX11硬件特性。
具体实现
#include "pch.h"
#include <amp.h>
#include <iostream>
#include <vector>
using namespace Concurrency;
constexpr auto PI = 3.14159265358979323846;
const int size = 10000000;//循环次数
//GPU计算
void GPUCompute(std::vector<double> vec)
{
DWORD t1, t2;
t1 = GetTickCount();
std::vector<double> resultVec;
resultVec.resize(size);
array_view<const double, 1> array1(size, vec);
array_view<const double, 1> array2(size, vec);
array_view<double, 1> result(size, resultVec);
//GPU计算部分
parallel_for_each(result.extent, [=](index<1> idx) restrict(amp)
{
result[idx] = array1[idx] * array1[idx] * array2[idx] / array2[idx];
});
t2 = GetTickCount();
std::cout << "GPU Use Time:" << (t2 - t1)*1.0 / 1000 << "\n";
}
//CPU计算
void CPUCompute(std::vector<double> vec)
{
DWORD t1, t2;
t1 = GetTickCount();
std::vector<double> result;
result.resize(size);
for (size_t i = 0; i < size; i++)
{
result[i] = vec[i] * vec[i] * vec[i] / vec[i];
}
t2 = GetTickCount();
std::cout << "CPU Use Time:" << (t2 - t1)*1.0 / 1000 << "\n";
}
int main()
{
std::vector<double> nums;
for (size_t i = 0; i < size; i++)
{
nums.push_back(PI);
}
GPUCompute(nums);
CPUCompute(nums);
system("PAUSE ");
}
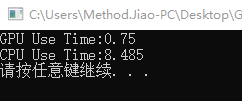
时间消耗
遗留问题及猜想
在循环数量过少,例如少于1w次循环下,cpu执行速度会比gpu执行速度快。原因可能在于gpu获取数据有固定时间消耗,无法像cpu一样直接调度数据总线。
因此会产生在循环数量很多时,cpu和gpu的差异才会被拉开。