谷歌发布了 Facets,一款开源的可视化工具。它可以帮助你理解、分析和调试 ML 数据集。Facets 包含两个部分——Facets Overview 和 Facets Dive——允许用户从不同的粒度观看数据的全景图,还可以轻易地被用在 Jupyter notebooks 之内,或者嵌入网页之中。除了开放 Facets 源代码,谷歌还创建了演示网站,Github 和网站地址见:
github 地址:https://github.com/pair-code/facets
演示地址:https://pair-code.github.io/facets/
overview
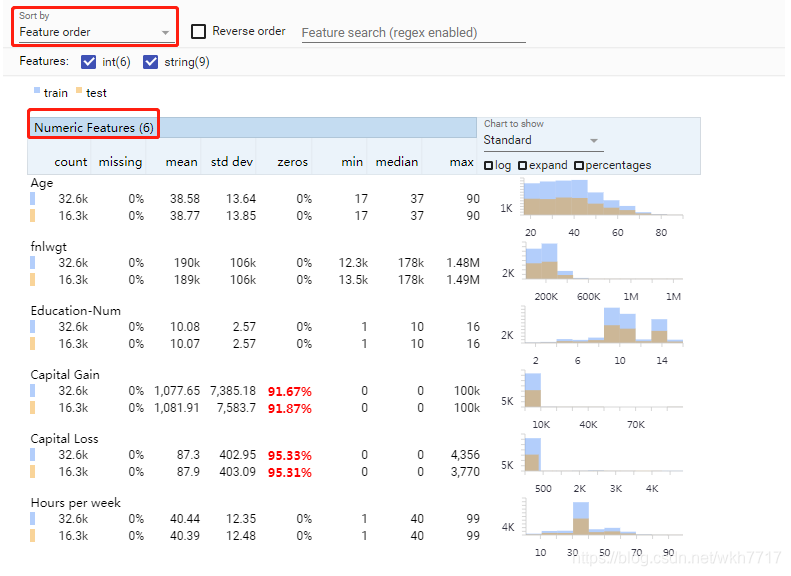
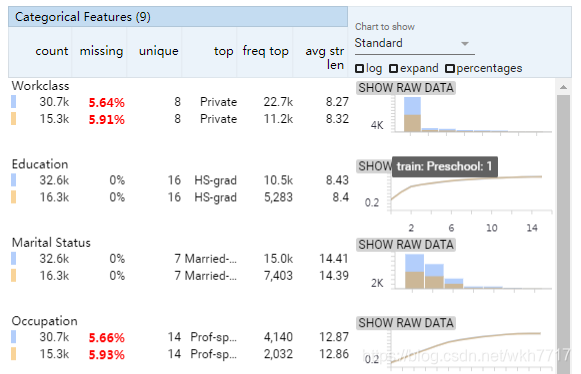
Overview提供一个或多个数据集的高级视图。它生成特征的可视化统计分析,还可以用于比较两个或多个数据集之间的统计信息,可以处理离散值和连续值。
Feature Statistics Protocol Buffer
- 存储ML系统输入数据的单个特性列的汇总统计信息
- 顶层原型是DatasetFeatureStatisticsList(DFSL),是一系列的DatasetFeatureStatistics(DFS),每个FDS表示单个数据集的特征统计信息,它包含一系列的FeatureNameStatistics(包含单个数据集中单个特性的统计信息)
- feature statistics取决于datasets的数据类型(numeric, string, or raw bytes),numeric类型
- numeric类型包含:最大值、均值、中值、最小值、方差、缺失比例、0值比例等
- string类型包含:string平均长度, 唯一值个数,缺失值比例,top等
- 可选项weighted统计:如果数据集中有weight特征,则可进行带权值统计,显示时可在权值统计和普通统计之间进行视图切换
- 可选项custome统计:自定义统计特性
Feature Statistics Generation
numpy、pandas、tensorflow包需要安装
from generic_feature_statistics_generator import GenericFeatureStatisticsGenerator
import pandas as pd
df = pd.DataFrame({'num' : [1, 2, 3, 4], 'str' : ['a', 'a', 'b', None]})
proto = GenericFeatureStatisticsGenerator().ProtoFromDataFrames([{'name': 'test', 'table': df}])
将pandas转化为Proto形式,pandas读入,再用ProtoFromDataFrames转换
注:上面这种方式适用与小数据,大量数据需要采用spark处理
Visualization
from IPython.core.display import display, HTML
import base64
protostr = base64.b64encode(proto.SerializeToString()).decode("utf-8")
HTML_TEMPLATE = """<link rel="import" href="/nbextensions/facets-dist/facets-jupyter.html" >
<facets-overview id="elem"></facets-overview>
<script>
document.querySelector("#elem").protoInput = "{protostr}";
</script>"""
html = HTML_TEMPLATE.format(protostr=protostr)
display(HTML(html))
protoInput有三种形式:
- DatasetFeatureStatisticsList javascript实例
- UInt8Array(protocol buffer的序列化二进制文件)
- base-64编码的序列化protocol buffer(如上例所示)
Understanding the Visualization
- numeric特征展示
- string特征展示
dive
Dive是一种工具,可以交互式地探索多达数万个多维数据点,允许用户在高级概览和低级细节之间无缝切换。每个示例在可视化中都表示为一个单独的项,并且这些点可以通过它们的特征值在多个维度中进行面/桶形定位。通过将平滑动画和缩放与面板和过滤相结合,Dive可以很容易地发现复杂数据集中的模式和异常值
Getting Started
Providing Data to Dive
数据格式如下:
[{
"name": "apple",
"category": "fruit",
"calories": 95
},{
"name": "broccoli",
"category": "vegetable",
"calories": 50
},{
...Many more foods...
}]
- 不需要所有的数据都具有相同key,允许存在缺失值
- 只能处理numeric和string类型数据,array之类的复杂数据类型会优先转化为string
Providing Sprites For Dive to Render
可以替换展示形式
Navigating the Dive Controls
- Faceting Controls
XY轴选择,连续型数据等分成不同的段,离散型进行数值统计,值太多归为other - Positioning Controls
默认情况下直接将数据堆叠在一起或者放在散点图中 - Color Controls
- Display Controls 每个点呈现什么
示例程序
只需要把数据替换一下,其他的形式可以不用更改
import sys
sys.path.append('./python')
# 读入数据
import pandas as pd
features = ["Age", "Workclass", "fnlwgt", "Education", "Education-Num", "Marital Status",
"Occupation", "Relationship", "Race", "Sex", "Capital Gain", "Capital Loss",
"Hours per week", "Country", "Target"]
train_data = pd.read_csv(
# "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data",
'E:/PyProject/facets/facets_overview/adult.data',
names=features,
sep=r'\s*,\s*',
engine='python',
na_values="?")
test_data = pd.read_csv(
# "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.test",
'E:/PyProject/facets/facets_overview/adult.test',
names=features,
sep=r'\s*,\s*',
skiprows=[0],
engine='python',
na_values="?")
#展示
from IPython.core.display import display, HTML
jsonstr = train_data.to_json(orient='records')
HTML_TEMPLATE = """
<script src="https://cdnjs.cloudflare.com/ajax/libs/webcomponentsjs/0.7.24/webcomponents-lite.js"></script>
<link rel="import" href="https://raw.githubusercontent.com/PAIR-code/facets/master/facets-dist/facets-jupyter.html">
<facets-dive id="elem" height="600"></facets-dive>
<script>
var data = {jsonstr}; #数据
document.querySelector("#elem").data = data;
</script>"""
html = HTML_TEMPLATE.format(jsonstr=jsonstr)
display(HTML(html))