版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/huaishu/article/details/89949872
数据库查询类型
- 点查:主键ID查询
- 多点:返回多条记录
- 范围:大于、小于
- 匹配查询:like
- 极值查询:max
- 排序:order by
- 分组查询:group by
- 连接查询:多表联合
数据结构
B、B-、B+树
离根越远的节点越不可能被存放在RAM中,B+树NULL值不在索引中



B+ Tree索引优点
- 全值匹配:指的是和索引中所有列进行匹配
- 匹配最左前缀:假设以(姓,名,出生日期)三个数据项建立复合索引,可以查找所有姓的人
- 匹配列前缀: name like '刘%'
- 匹配范围值:where date>='201900509',注意范围查询只在复合索引的优先排序的第一列。
- 精确匹配前面列并范围匹配后一列:注意范围第一个范围查询后面的列无法再使用索引查询
- 只访问索引的查询:即查询只需访问索引,而无需访问数据行。(此时应想到索引中的覆盖索引)
B+ Tree索引缺点
- 如果不是按照索引的最左列开始查找,则无法使用索引
- 不能跳过索引中的列
- 如果查询中包括某个列的范围查询,则其右边所有列都无法使用索引优化查询
哈希结构
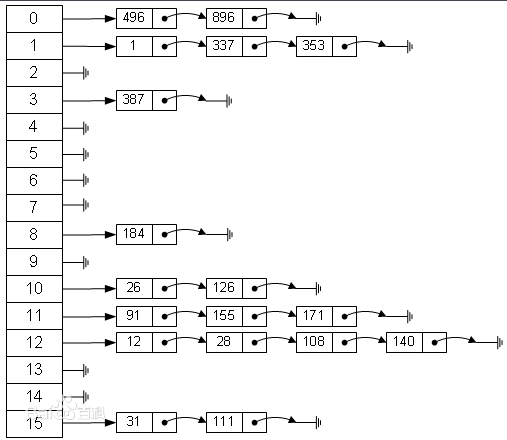
哈希索引优点
- 快速查询:参与索引的字段只要进行Hash运算之后就可以快速定位到该记录,时间复杂度约为1
哈希索引缺点
- 哈希索引只包含哈希值和行指针,所以不能用索引中的值来避免读取行
- 哈希索引数据并不是按照索引值顺序存储的,所以也就无法用于排序和范围查询
- 哈希索引也不支持部分索引列查询,因为哈希索引始终是使用索引列的全部数据进行哈希计算的。
- 哈希索引只支持等值比较查询,如=,IN(),<=>操作
- 如果哈希冲突较多,一些索引的维护操作的代价也会更高
Bitmap位图
位图索引与倒排索引类似,后者主要使用在全文检索。
10行其中一列数据
10 20 30 20 10 30 10 30 20 30
那么会建立三个位图,如下:
BLOCK1 KEY=10 1 0 0 0 1 0 1 0 0 0
BLOCK2 KEY=20 1 0 0 0 1 0 1 0 0 0
BLOCK3 KEY=30 1 0 0 0 1 0 1 0 0 0优点:
- 适合决策支持系统;
- 当select count(XX) 时,可以直接访问索引中一个位图就快速得出统计数据;
- 当根据键值做and,or或 in(x,y,..)查询时,直接用索引的位图进行或运算,快速得出结果行数据。
缺点:
- 不适合键值较多的列(重复值较少的列);
- 不适合update、insert、delete频繁的列,代价很高。
索引类型


聚簇索引:利用主键建立的索引,其物理存放顺序与主键顺序一致。因为数据只有一个物理存放顺序,所以一个表只有一个聚簇索引。 (字典拼音查字)
非聚簇索引(二级索引,辅助索引):除了聚簇索引之外,其余所有的索引都是非聚簇索引(字典部首查字)
非聚簇索引可以通过覆盖的方法来减少访问下层关系表的次数(直接访问索引)具有比稀疏的聚簇索引更好的性能(与稠密的聚簇索引相当)
稠密索引:对一个数据页至多只有一个指向它的指针,降低系统响应时间
稀疏索引:相对于稠密索引,稀疏索引只为某些搜索码值建立索引记录;在搜索时,找到其最大的搜索码值小于或等于所查找记录的搜索码值的索引项,然后从该记录开始向后顺序查询直到找到为止
唯一索引:允许null值存在,减少排序
主键索引:利用主键建立的索引
组合索引:多数据项建立索引,一个索引包含(覆盖)所要查询的字段的值,可以覆盖索引
多表连接
嵌套循环连接
哈稀连接