爬虫学习笔记 2
实践
1. 爬取网页的整体思路
一句话概括就是想办法遍历所有打开文章内容的链接。
1.2 选取内容网站
我选择的是偶然看到的一个小网站,内容丰富,结构也不复杂,更没有各种反爬机制。练手是可以的,为了表示尊重这里不敢说什么网站。

1.3 分析网站结构
1.3.1 确定基本页面
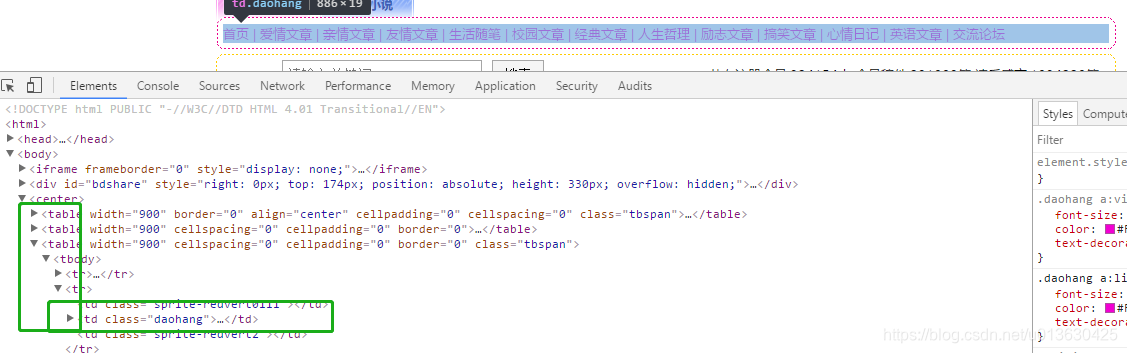
简单浏览就基本上可以确定网站的全部分类页面都在首页的banner导航栏里面,所以只要拿到首页直接选取导航栏里面的所有URL,就是接下来需要遍历的index_url_list[].
开发者模式,看一下网页基本都是table,导航栏就是第三个table里面的全部的<a>,全部加入到上述list中就拿到了第一步要遍历的url。
1.3.2 分析分类索引页面
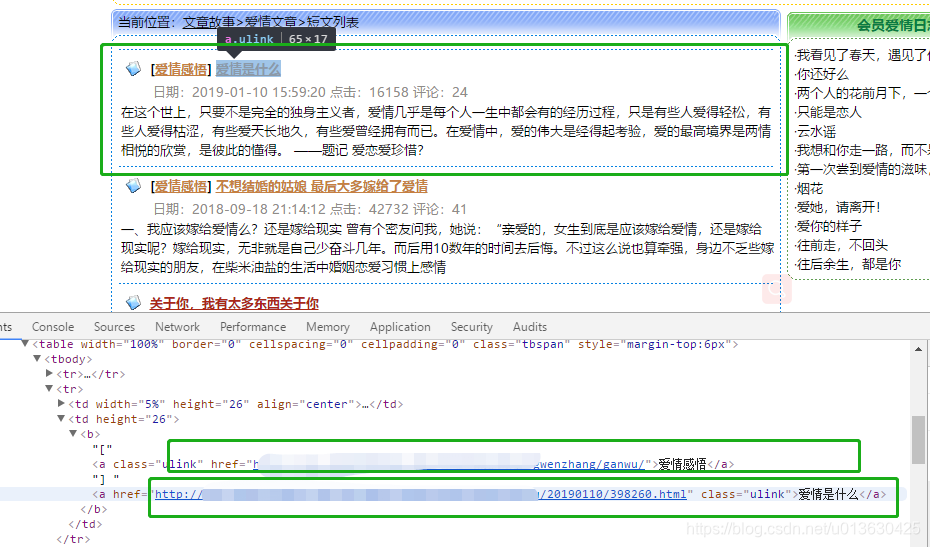
以爱情文章为例,打开页面可以看到文章的展示模板很简单,依次是【分类】文章标题,页面结构就是层次嵌套的table,所以只要数清楚从第几个table开始的内容就可以抓到文章的URL了。抓取url的时候可以看到,文章的URL是第二个<a>第一个是分类,但是分类和标题的class都是一样的,所以也不能用class抓,采用笨方法实现,判断标题那一行的<b>标签里面有几个<a>,如果有两个,只取第二个<a>的href,把本页所有的文章URL放入一个type_url_index[]分类URL索引列表里存起来。这样第一页的内容抓取完成。
拿分类页面的索引URL
def get_sanwen_index_url(soup):
"""
:param soup:传递一个页面的soup进行分析
:return: 返回当前页面的 url_list
"""
# 定义页面索引url_list
type_url_index = []
# 拿到分类索引页面里的url列表
type_table = soup.find_all('table') # 获取当前页面所有的table
print('table一共 ', type_table.__len__())
# 每页拿url_list
for j in range(10, type_table.__len__()):
b = type_table[j].find_all('b') # 从第10个table开始,每个table 里面拿 b ,b 里面包含标题
print('table ', j)
# print(type_table[j].get_text())
if b.__len__() > 0:
print(b[0].get_text())
# 每个b 里面拿第一或二个a
a = b[0].find_all('a')
if a.__len__() > 1:
type_url_index.append(a[1].get('href'))
elif a.__len__() == 1:
type_url_index.append(a[0].get('href'))
return type_url_index
1.3.3 分析处理‘下一页’
接下来就分析怎么抓下一页。
拉到页面最低端的下一页部分,经过分析,‘下一页’并没有可以作为标识的class或者id,而且里面的url不全,只有最后的HTML名称,不过幸好里面确实是链接,不是javascript(),目前的能力只够抓url,于是再次采用笨方法,查所有的<a>把内容为“下一页”的那个<a>的href取出来和当前分类index_url_list[]的URL拼装一下,组成下一页的url,直到"下一页"这个<a>不存在,这个分类下的索引就拿完了,进入下一个分类。

1.3.4 获取文章页面的内容
打开文章详情页面,文章模板一如既往的table,经过分析,标题放在table里面的<h1>标签内,且,只有一个h1标签。文本内容是一个div,id是“wenzhangziti”,于是,直接取了h1和对应div里面text就可以了。遍历读取当前分类下全部的内容,之后保存到文件中。

1.4 保存文档
在每个分类都读取完以后,就把读取到的内容存一个txt文档,以首页取到的分类名作为文档名称。
这样就完成了。
下面贴上完整代码。
def get_sanwen(url: str, resolver: str):
"""
:url:网站首页
:resolver:解析器,默认为lxml,这里应该用html.parser
:爬取文章,学习记录,代码根本目的在于实现功能,不存在任何‘优质’可言
:return:
"""
# 进入首页
soup = get_url_soup(url, resolver)
# 定义首页的分类url 列表 - 想改为字典 但是 字典的元素操作太复杂,hhhh,,,
index_url_list = []
# 定义首页分类名 列表 index_title
index_title_list = []
# 获取索引页面全部的table
table_all = soup.find_all('table')
# 第4 [3]个是导航表格
index_table = table_all[3]
# 获取所有的导航链接
for link in index_table.find_all('a'):
index_url_list.append(link.get('href'))
index_title_list.append(link.get_text())
# print(url_index)
# 第一个链接是首页,最后一个是论坛,从第二个链接开始,到提前一个结束,逐一打开链接
for i in range(1, index_url_list.__len__() - 1):
# 各个分类单独的索引页的url列表 ,每循环一次重新创建
type_url_index = []
# 分析当前分类下有多少页 - 如果‘下一页’上面获取不到link 就结束,否则一直进入下一页,
# 定义下一页,从当前也开始
url_next = index_url_list[i]
# 默认有下一页
next_page = True
while next_page:
# 拿一个新的url_next
soup = get_url_soup(url_next, resolver)
# 暂停0.5秒
time.sleep(0.5)
# 解析当前页面,加入url列表中
type_url_index.extend(get_sanwen_index_url(soup))
# 获取全部的 a ,判断是否 string =‘下一页’
next_a = soup.find_all('a')
# 定义页面的a的text
context = ''
# 查询下一页
for a in next_a:
context += a.get_text()
if a.string == '下一页':
if a.get('href') != '': # 下一页不为空,就组合下一页
url_next = "%s%s" % (index_url_list[i], a.get('href')) # 这里url_index[] 后面本身有 / ,如果没有要加上
print(url_next)
time.sleep(0.5)
elif a.get('href') == '':
next_page = False
if '下一页' not in context:
# print(context)
next_page = False
# 拿到当前分类下所有文章的url列表,循环加载,写入文件,根据分类写不同的文件
# 定义文本
text = ''
for type_url in type_url_index:
soup = get_url_soup(type_url, resolver)
text += ' ' + soup.find('h1').get_text() + '\n\n' + soup.find(
id='wenzhangziti').get_text() + '\n\n\n\n\n'
with file_operation('D:\桌面文档\%s.txt' % (index_title_list[i]), 'wb+') as file:
file.write(text.encode('utf8')) # write()编码问题,将mode 设置为 'wb+' 读二进制,可以解决
print(index_title_list[i], 'ok')
附
在使用beautifulsoup,采用lxml解析器来解析这个网站的时候就遇到了页面怎么都读取不完整的问题,可能是页面不规范,采用html.parser解析器解决问题,这个容错性最高。