文章目录
tip:可以直接看第四小节
HA简介
Hadoop-HA :
- linux环境配置:
1 网络配置 ip
2 防火墙
3 NTP时间服务器
4 ssh无秘钥访问 - 软件环境配置
jdk - Hadoop
| 第一台服务器1 | 第二台服务器 | 第三台服务器 |
|---|---|---|
| NameNode | NameNode | |
| DataNode | DataNode | DataNode |
| JournalNode | JournalNode | JournalNode |
| ZK | ZK | ZK |
| ResourceManager | ResourceManager | |
| NodeManager | NodeManager | NodeManager |
-
zookeeper
-
原理讲解:
HA : 高可用
HA原理:https://www.cnblogs.com/shenh062326/p/3870219.html
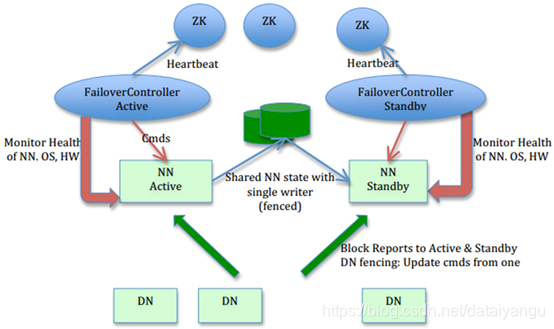
下面DN是datanode,上面的NN是namenode,一个namenode是active活跃状态,一个namenode是standby待机状态,当active的挂掉了,standby会立即启动,假设用户此时像hdfs存储文件,此时会产生log文件,当editlog发生变化,则直接写入JournalNode,以用来分享给其他NameNode。怎样能让它自动的高可用?FailOverController,ZK中的一个子模块,这个东西也是用来控制NameNode的,当一个NameNode切换到Standby状态的时候,FailOverController会通知Standby模块启动到active状态。
什么叫split-brain,脑裂,是一个不好的现象,需要规避脑裂的现象,什么是脑裂呢?假如目前有两个NameNode,只有一个能当领导,一个人当从属的,假如第一个已经确认是领导了,第二个机器只要发现第一个机器是活着的,就不能当领导,假设某一天第一台服务器和第二台服务器中间出现中断了,就意味着这两台NameNode其实是活着的,NameNode和DataNode之间通信是没有问题的,但是NameNode和NameNode之间的通信中断了,这样第二台NameNode通过心跳找不到第一台了,他以为第一台死了,他就自己去当领导了,第一台和第二胎也通信不了了,第一台认为自己是领导,第二胎死了就死了,反正不是领导,这样就会导致两台NameNode同时活跃,但是目前用户操作的原数据上传给谁?上传给第一个还是第二个?都会上传的,所以会出现抢占资源的情况,因为NameNode在整个资源环境中相当于一个心脏,相当于一个大脑,所以他们两个一分裂就叫脑裂。
如何解决脑裂的问题呢?隔离机制,在配置的时候需要实现无密钥登录,
<property>
<name>dfs.fencing.nethods</name>
<value>sshfence</value>
</property>
//fence什么意思?篱笆,围栏,隔离
//所以如果使用这个机制的话,就必须配置ssh无密钥登录。
现在为了防止脑裂,如上如,两个NameNode之间不是互相之间通信的,二是建立了中间一个第三方的一个节点,controller,这两个controller来决定到底谁应该党领导,每个NameNode都会给自己的controller上传自己的心跳信息,当controller发现自己的心跳信息没有了,报告另一台,自己挂掉了。
部分配置讲解:
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
//mycluster是当前集群的名称,为当前的hdfs集群起的名字
<property>
//这里的后面的mycluster要和上面的value值一致
<name>dfs.namenodes.mycluster</name>
//集群中有几个NameNode,这些NameNode叫什么
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenodes.rpc-address.mycluster.nn1</name>
//指定rpc的通信地址,
<value>machina1.example.cono.8082</value>
</property>
<property>
<name>dfs.namenodes.rpc-address.mycluster.nn2</name>
//指定rpc的通信地址,
<value>machina2.example.cono.8082</value>
</property>
<property>
<name>dfs.namenodes.http-address.mycluster.nn1</name>
//指定http的通信地址,
<value>machina1.example.cono.50070</value>
</property>
<property>
<name>dfs.namenodes.http-address.mycluster.nn2</name>
//指定http的通信地址,
<value>machina2.example.cono.50070</value>
</property>
<property>
<name>dfs.namenodes.sharad.edits.dir</name>
//qjournal中存储NameNode的editlog的文件路径
//这里是qjournal的地址,最后是集群的名称
<value>qjournal://node1.example.com:8485:node2.example.com:8485:node3:example.com:84f85/mycluster </value>
</property>
<property>
//配置故障转移使用dfs
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.COnfuguredFailoverProcyProvider</value>
</property>
zookeeper默认的投票机制:每个节点启动的时候都是先投自己,然后再同一投票结果,默认情况下myid大的党当领导。假如第一轮投票,第一个机器投出来自己1,并且传递给其他的服务器,然后第二个机器网络震荡了,自己的投票结果没有传给其他服务器,其他服务器已经处理完投票结果了,因为响应超时,所以就不等第二台服务器了,所以开始进行第二次投票,在进行第二次投票的同时,第二台机器恢复了,会把自己第一次投票的结果给其他的服务器,但是其他服务器已经在第二轮的投票中了,这个时候其他服务器接收到第二台机器的信息之后,发现信息比较老了,会直接让所有服务器放弃第二台服务器的投票。
总体:因为NameNode的信息需要写在JournalNode中,而JournalNode依赖于zookeeper,所以需要启动zookeeper
- 安装部署
step1 配置zookeeper
stop2 配置hadoop (hadoop-env.sh core-site.xml hdfs-site.xml yarn-site.xml)
如何查看官方文档:
一、Linux网络配置复习
1.1 CentOS 6
1)Linux网络配置
# vi /etc/udev/rules.d/70-persistent-net.rules
复制ATTR{address}=="00:0c:29:e1:bc:79"引号中的值到ifcfg-etho0中
# vi /etc/sysconfig/network-scripts/ifcfg-eth0
配置如下:
DEVICE=eth0
HWADDR=00:0C:29:E1:BC:79
TYPE=Ethernet
UUID=a6713a48-ce04-4bb5-9e4d-8f929976196c
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.122.10
GATEWAY=192.168.122.2
NETMASK=255.255.255.0
DNS1=114.215.126.16
DNS2=192.168.122.2
2)Linux防火墙
service iptables status (功能描述:查看防火墙状态)
chkconfig iptables –list (功能描述:查看防火墙开机启动状态)
service iptables stop (功能描述:临时关闭防火墙)
chkconfig iptables off (功能描述:关闭防火墙开机启动)
chkconfig iptables on (功能描述:开启防火墙开机启动)
1.2 CentOS 7
1)Linux网络配置
# vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
TYPE="Ethernet"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
NAME="eno16777736"
UUID="43d220b2-1f75-4811-8a4b-2cf798f36b46"
DEVICE="eno16777736"
ONBOOT="yes"
DNS1="192.168.122.2"
DNS2="202.102.227.68"
IPADDR=192.168.122.200
PREFIX=24
GATEWAY=192.168.122.2
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
NETMASK=255.255.255.0
2)Linux防火墙
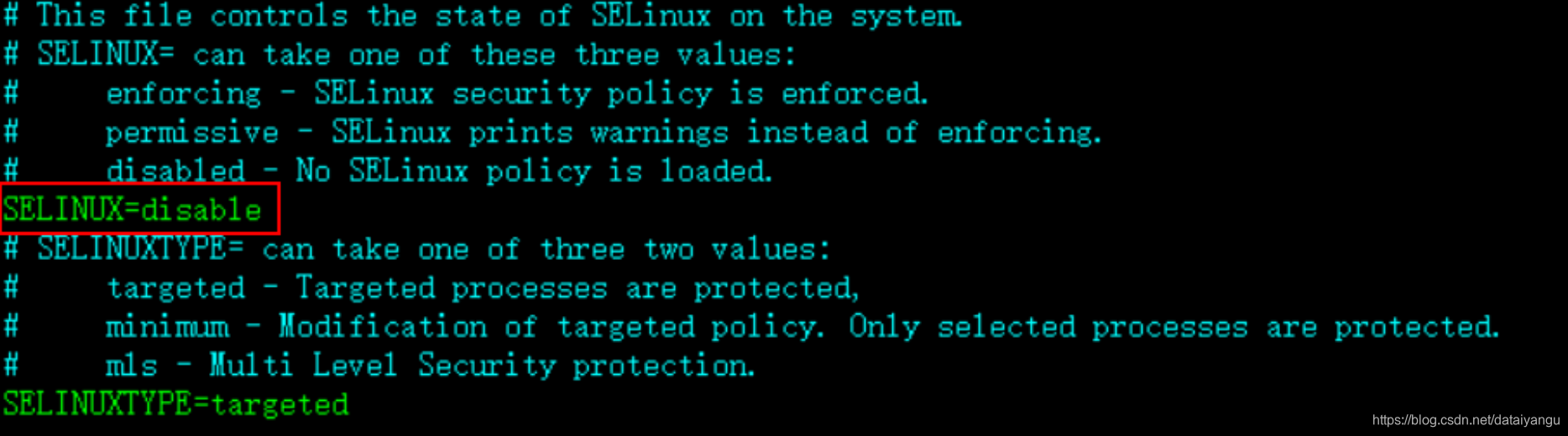
# vi /etc/sysconfig/selinux
将设置改为禁用:SELINUX=disabled,如图:
# systemctl stop firewalld.service(关闭防火墙)
# systemctl disable firewalld.service(防火墙开机禁用)
二、Linux软件环境配置
1.1 JDK安装
$ tar -zxf /opt/softwares/jdk-8u121-linux-x64.gz -C /opt/modules/
1.2 JDK环境变量配置
# vi /etc/profile
#JAVA_HOME
JAVA_HOME=/opt/modules/jdk1.8.0_121
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export
PATH=$PATH:$JAVA_HOME/bin
三、Linux 其他准备操作
3.1字符模式启动
# cat /etc/inittab
# systemctl set-default multi-user.target,来设置无界面启动linux
# systemctl set-default graphical.target,来设置有界面启动linux
3.2 配置NTP时间服务器
3.2.1检查时区
对于我们当前这种案例,主要目标是把z01这台服务器设置为时间服务器,剩下的z02,z03这两台机器同步z01的时间,我们需要这样做的原因是因为,整个集群架构中的时间,要保持一致。
检查当前系统时区,使用命令:# date -R

注意这里,如果显示的时区不是+0800,你可以删除localtime文件夹后,再关联一个正确时区的链接过去,命令如下:
# rm -rf /etc/localtime
# ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3.2.2同步时间
# ntpdate pool.ntp.org
3.2.3修改NTP配置文件
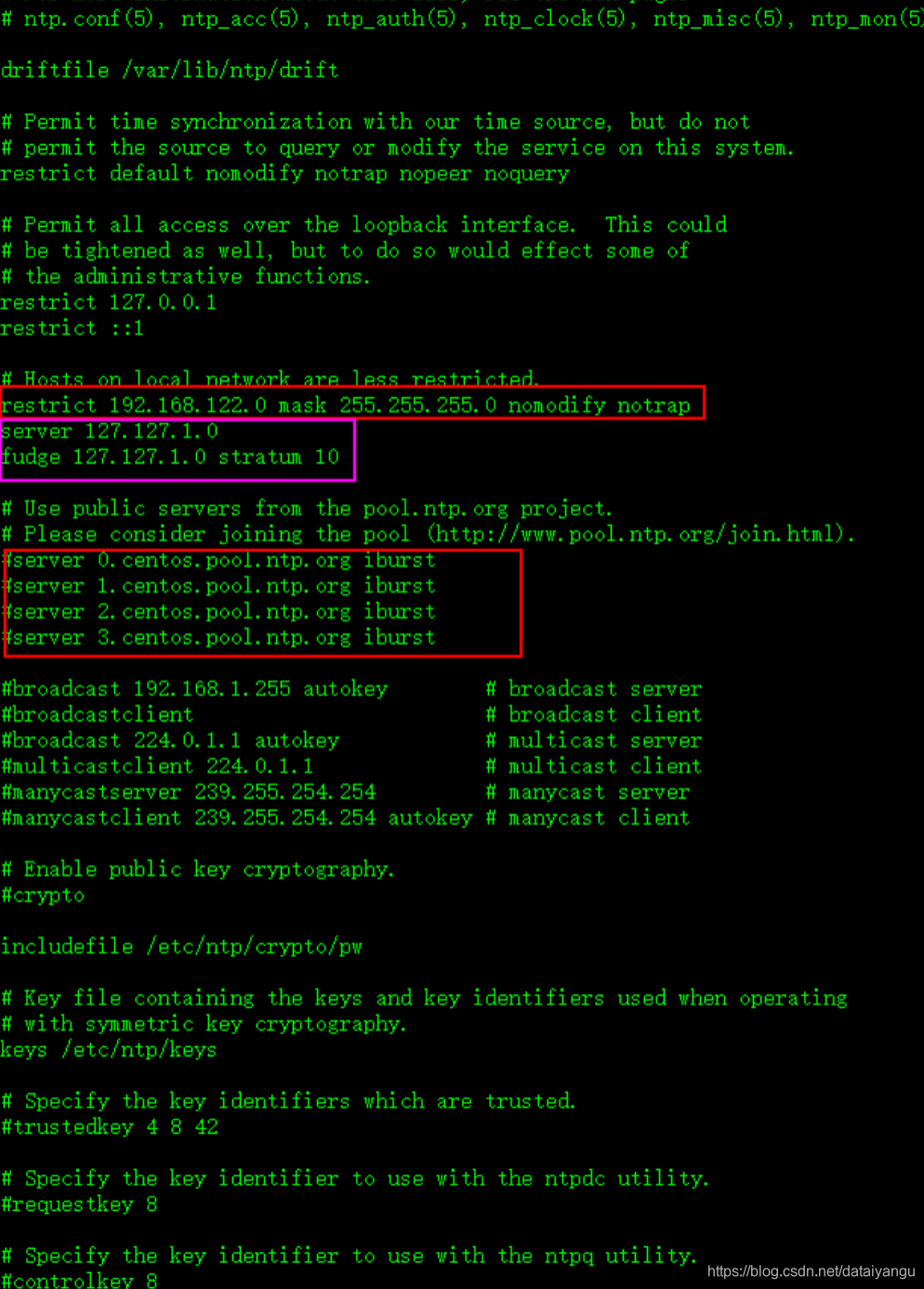
# vi /etc/ntp.conf
去掉下面这行前面的# ,并把网段修改成自己的网段:
restrict 192.168.122.0 mask 255.255.255.0 nomodify notrap
注释掉以下几行:
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
#server 2.centos.pool.ntp.org
把下面两行前面的#号去掉,如果没有这两行内容,需要手动添加
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10
最后,如图所示:
3.2.4重启ntp服务
# systemctl start ntpd.service,注意,如果是centOS7以下的版本,使用命令:service ntpd start
# systemctl enable ntpd.service,注意,如果是centOS7以下的版本,使用命令:chkconfig ntpd on
3.2.5集群其他节点去同步这台时间服务器时间
首先需要关闭这两台计算机的ntp服务
# systemctl stop ntpd.service,centOS7以下,则:service ntpd stop
# systemctl disable ntpd.service,centOS7以下,则:chkconfig ntpd off
# systemctl status ntpd,查看ntp服务状态
# pgrep ntpd,查看ntp服务进程id
同步第一台服务器z01的时间:
# ntpdate z01

3.2.6制定计划任务,周期性同步时间
# crontab -e
*/10 * * * * /usr/sbin/ntpdate z01
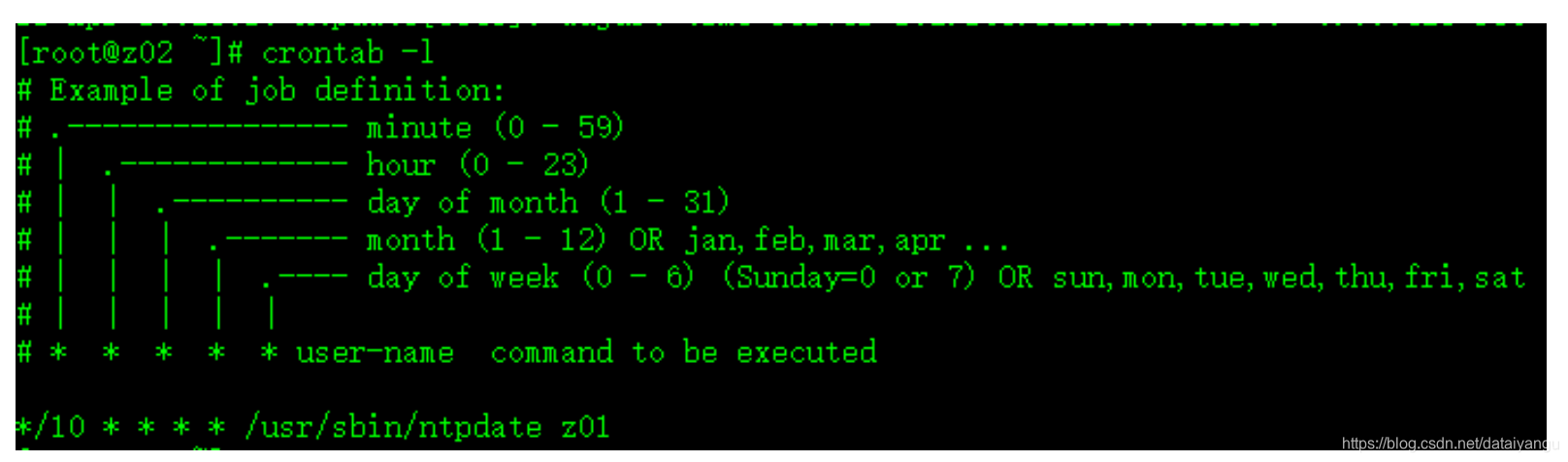
3.2.7重启定时任务
# systemctl restart crond.service,centOS7以下使用:service crond restart,其他台机器的配置同理
3.3 ssh无秘钥登录
配置hadoop集群,首先需要配置集群中的各个主机的ssh无密钥访问
在z04上,通过如下命令,生成一对公私钥对
$ ssh-keygen -t rsa,一顿回车操作,这条命令执行完毕后(注意使用普通用户执行该命令),会在/home/z/.ssh/目录下生成两个文件:id_rsa 和 id_rsa.pub,如图所示:
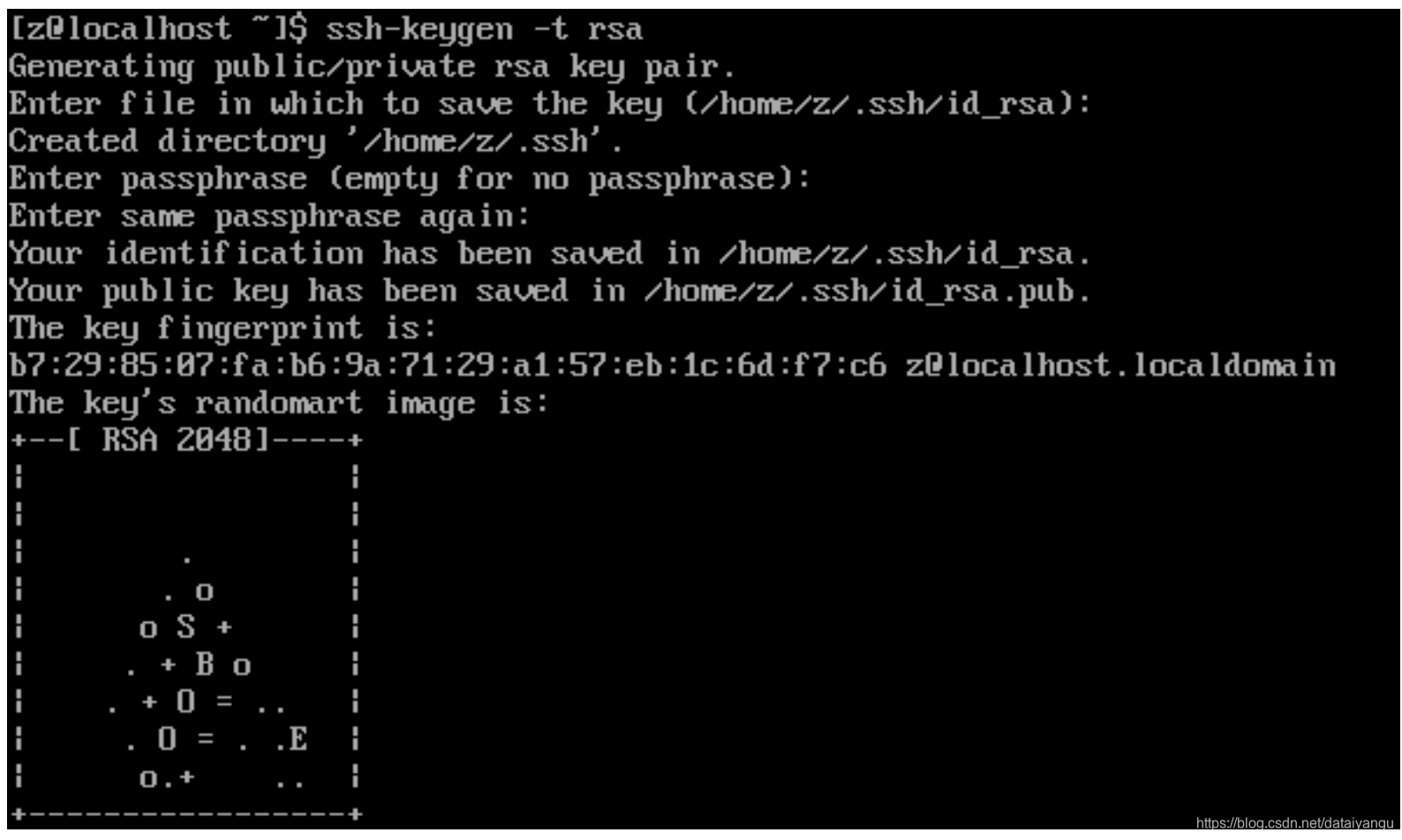
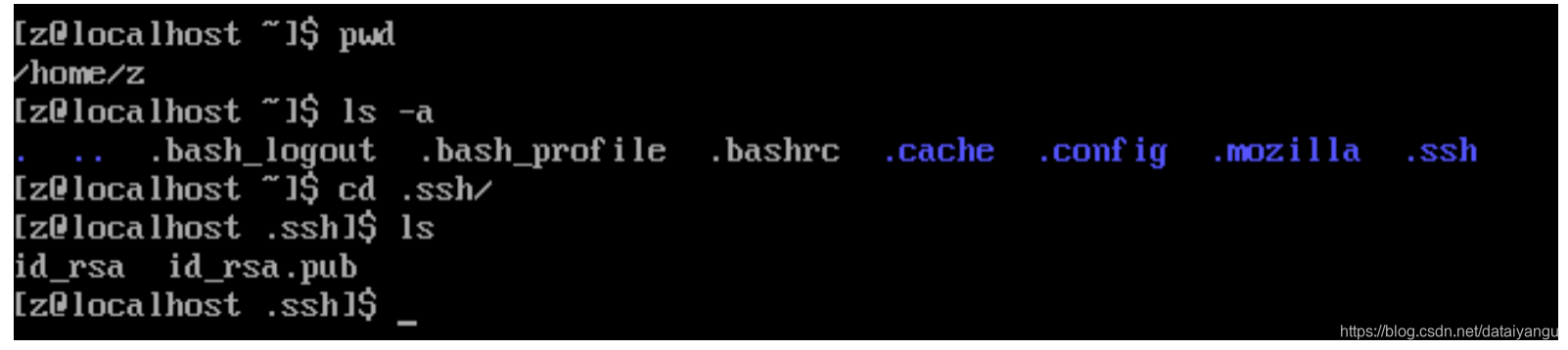
生成之后呢,把z01生成的公钥拷贝给z01,z02,z03这三台机器,对,没错,包含当前机器。
$ ssh-copy-id z01
$ ssh-copy-id z02
$ ssh-copy-id z03
完成后,其他机器同理。
四、CDH安装
4.1 CDH之zookeeper
4.1.1修改zoo.cfg配置文件
修改conf目录下的zoo.cfg文件,如果没有该文件,请自行重命名sample.cfg文件,修改内容为:
dataDir=/opt/modules/cdh/zookeeper-3.4.5-cdh5.3.6/zkData
server.1=z01:2888:3888
server.2=z02:2888:3888
server.3=z03:2888:3888
同时创建dataDir属性值所指定的目录
4.1.2在zkData目录下创建myid文件,修改值为1,如:
$ cd /opt/modules/cdh/zookeeper-3.4.5-cdh5.3.6/zkData
$ touch myid
$ echo 1 > myid
4.1.3将zookeeper安装目录scp到其他机器节点
$ scp -r /opt/modules/cdh/zookeeper-3.4.5-cdh5.3.6/ z05:/opt/modules/cdh/
$ scp -r /opt/modules/cdh/zookeeper-3.4.5-cdh5.3.6/ z06:/opt/modules/cdh/
4.1.4修改其他机器节点的myid文件为2和3
$ echo 2 > myid
$ echo 3 > myid
4.1.5在每个节点上启动zookeeper以及查看状态
$ bin/zkServer.sh start
$ bin/zkServer.sh status
4.2 CDH 之hadoop
4.2.1NameNode HA
- hdfs-site.xml
<configuration>
<!-- 指定数据冗余份数 备份数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
//注意这里的名称和core-site中配置的名称必须一致
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
//这里的mycluster和上面名称一致
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>z04:8020</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>z05:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>z04:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>z05:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<!--namenode上的数据在editlog发生变化的时候,会单节点写入到JournalNode上
即只有一个NameNode能写,另一个NameNode读的状态-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://z04:8485;z05:8485;z06:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<!--根据实际情况而定-->
<value>/home/z/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/data/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
</configuration>
* core-site.xml
<configuration>
//给集群起个名字
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/cdh/hadoop-2.5.0-cdh5.3.6/data</value>
</property>
</configuration>
完成后远程拷贝给其他服务器
命令操作:
启动服务
在各个JournalNode节点上,输入以下命令启动journalnode服务:
$ sbin/hadoop-daemon.sh start journalnode
在[nn1]上,对其进行格式化,并启动
$ bin/hdfs namenode -format
$ sbin/hadoop-daemon.sh start namenode
通过jps 发现多了NameNode说明成功
在[nn2]上,同步nn1的元数据信息,并启动
//启动之前先去第一台机器上面拉取备份的信息
$ bin/hdfs namenode -bootstrapStandby
$ sbin/hadoop-daemon.sh start namenode
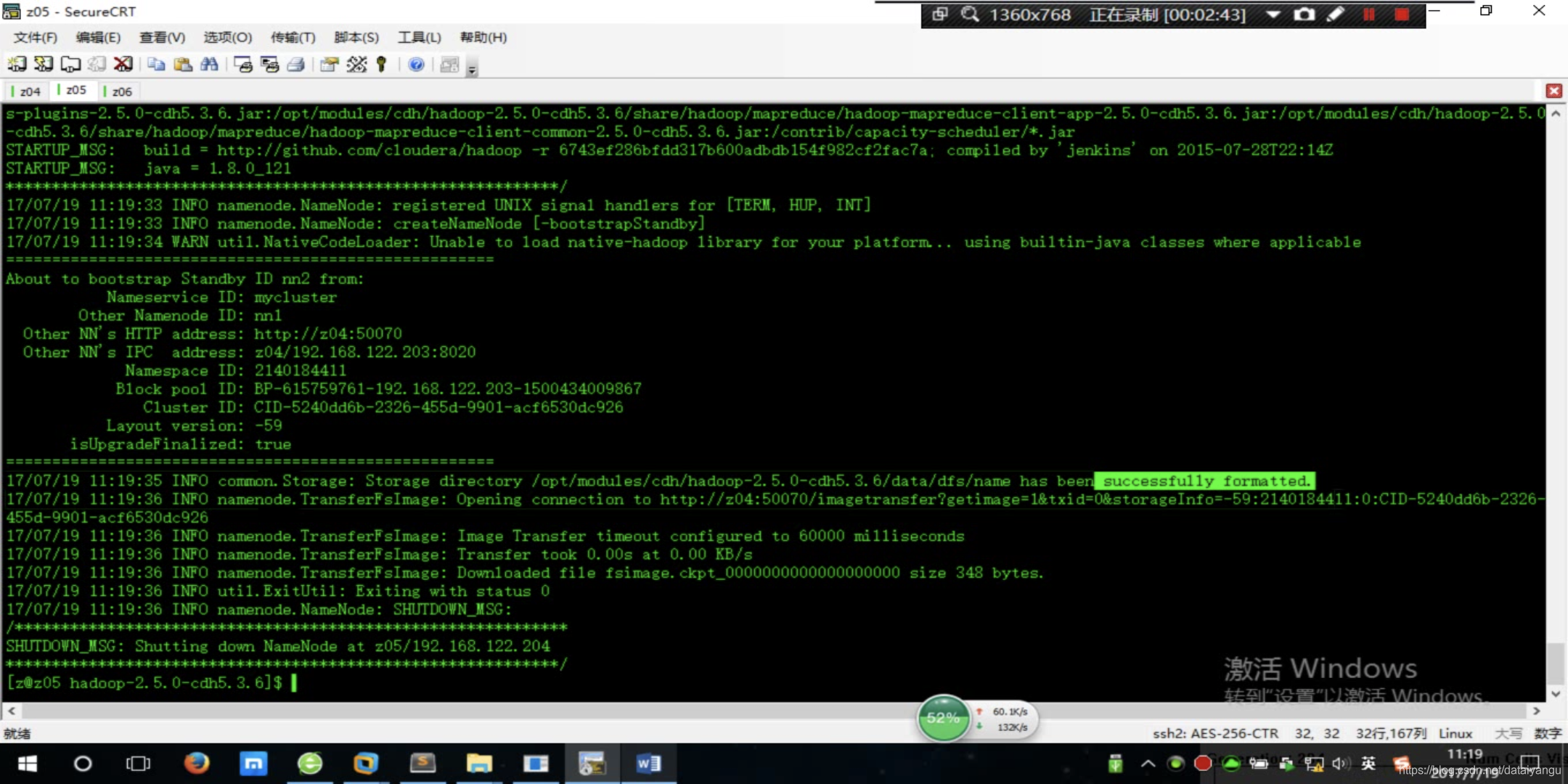
出现上面的successfully字样说明拉取成功了
通过jps 查看NameNode是否启动成功,如果没有上面拉取这步的话,是不能够成功的。
也存在启动起来之后过段时间又死掉了,这种情况可能是配置文件不对,或者机器的内存cpu等不够用了,导致自动挂掉。
访问z04:50070 z05:50070都能成功访问
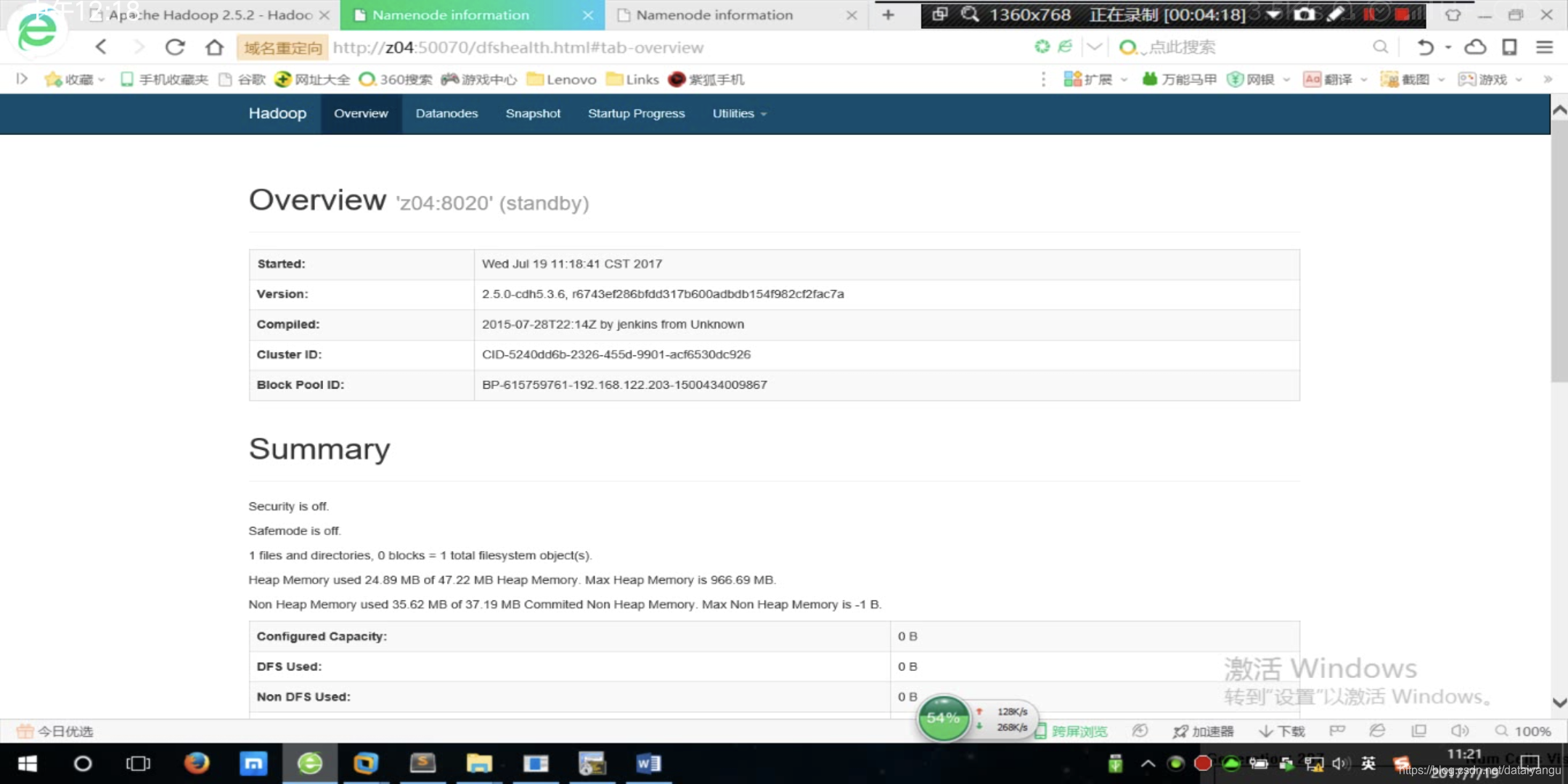
但是通过上图可以看到两台机器都是standby的,说明当前两个namenode都是无法使用的待命状态,为什么呢?因为还没有配置ZK Contoller,故障自动转移。
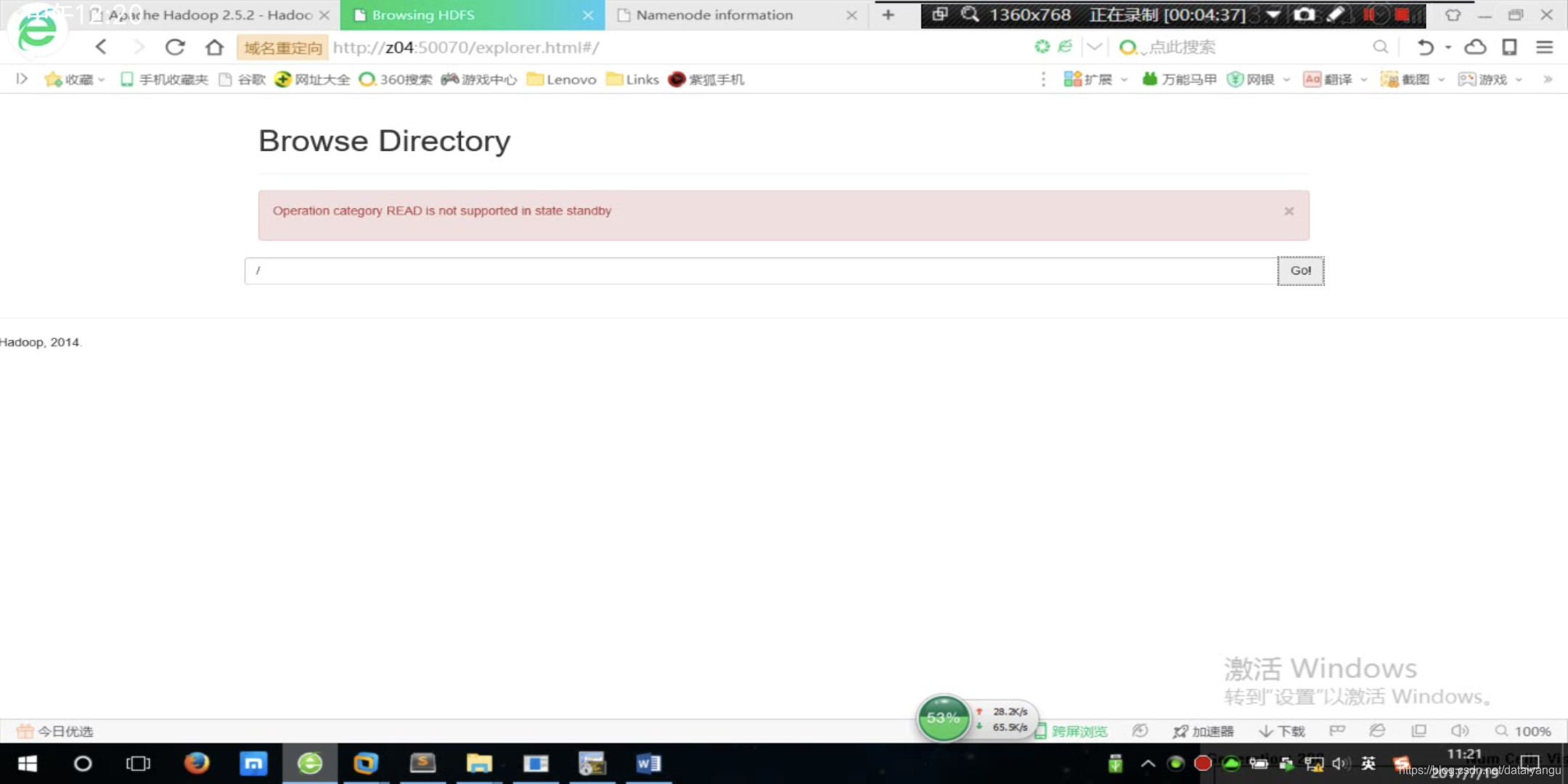
访问路径发现报错,意思就是想要读取目录是不允许在待机的目录上工作的
手动把nn1设置为active
$ bin/hdfs haadmin -transitionToActive nn1
运行完之后可能会宝如下的错误
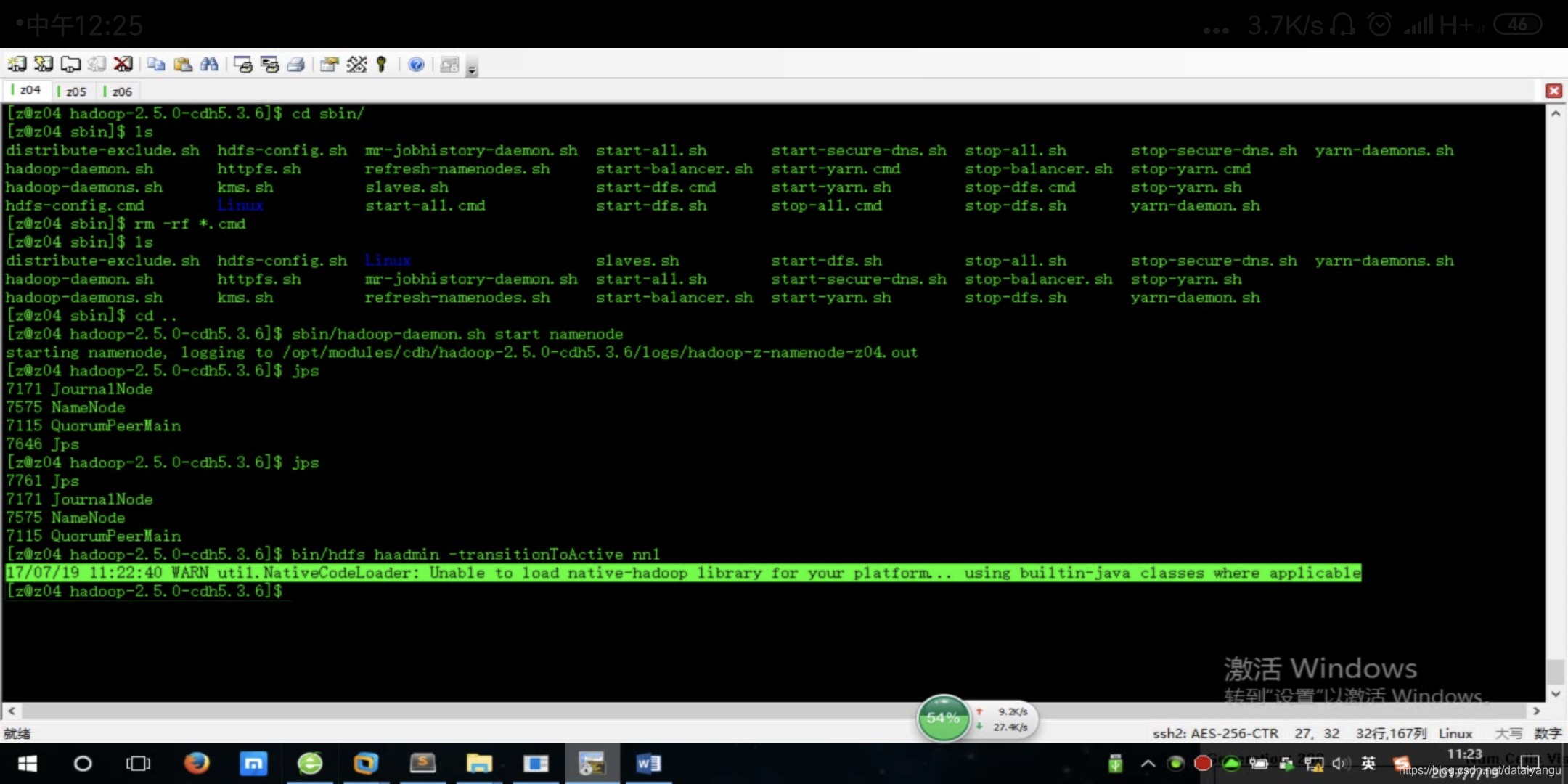
因为java可以调用c++的动态库,有些复杂的函数用java运行起来效率比较低,用c或者c++写,写完之后打包成.so的动态库,通过jni的机制调用c++的方法。
这里报错的原因是:hadoop_home/lib/native里面是空的,运行方法的时候去这里找c++的代码,没有找到,所以就用java代码替代了。
这个错误不影响使用。
现在再查看页面,发现不报错了,
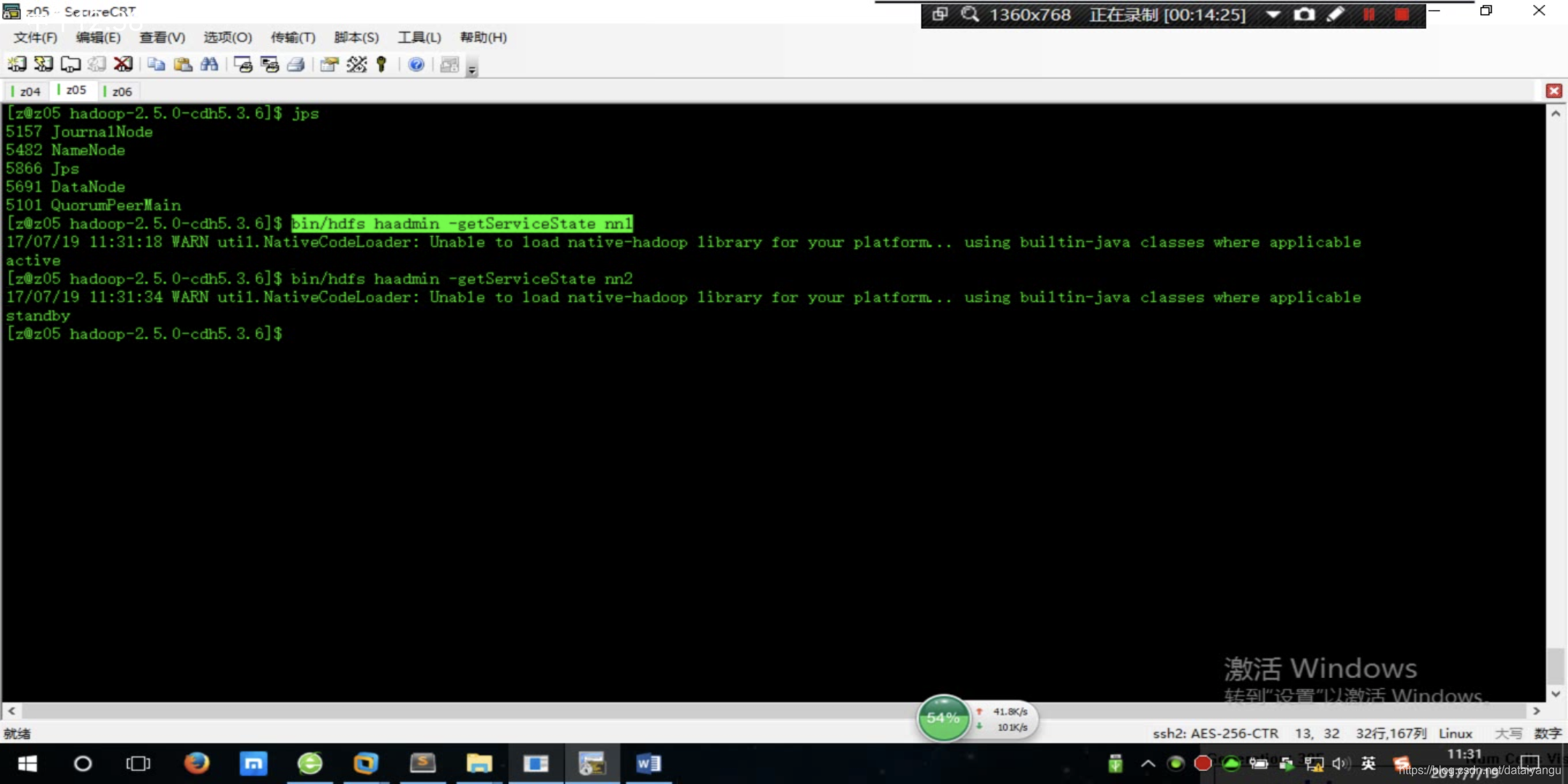
查看服务状态(是否active)
$ bin/hdfs haadmin -getServiceState nn1
配置故障自动转移(默认active挂掉之后standby是不会自动激活的)
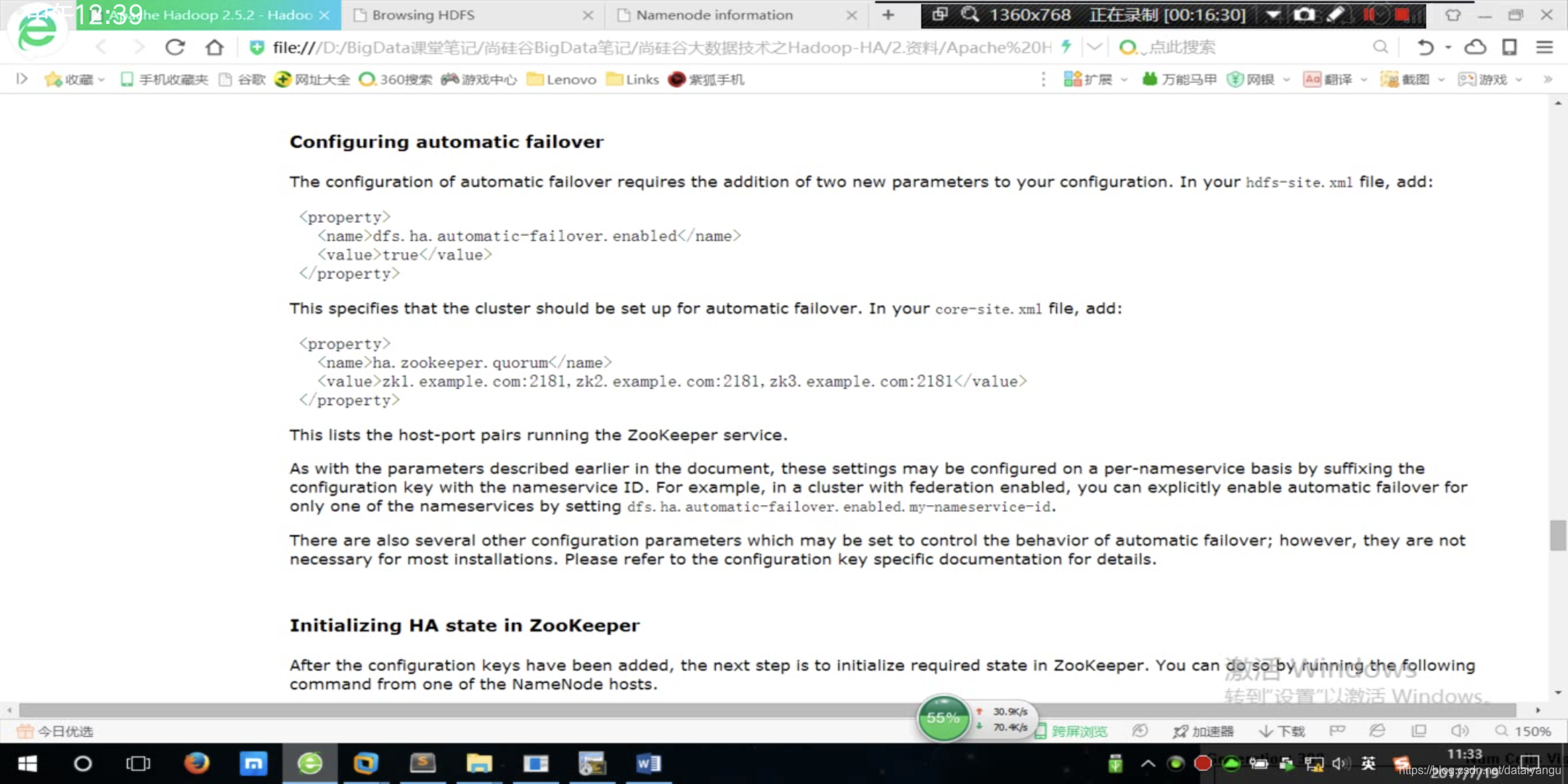
添加如上图的两个配置,图中写道:in your hdfs-site.xml file add:
在hdfs-site.xml文件中添加:
//配置是否开启自动故障转移,属性设置为true
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
在core-site.xml文件中添加:
//配置zookeeper的集群地址
<property>
<name>ha.zookeeper.quorum</name>
<value>czy-1:2181,czy-2:2181,czy-3:2181</value>
</property>
配置完之后将集群全部停掉,有一个快速方法
//会分别停掉namenode datanode zkcontroller journelnode
sbin/stop-dfs.sh
小tip:如果在启动某个几点,告诉你已经启动了这个节点,可是去查看的时候又确实没有启动这个节点?
进入hadoop_home/tmp文件,有一堆pid文件,进程id文件,在linux中每一个进程是以一个进程文件来体现的,当启动进程的时候会挂载一个进程文件,如果非法结束掉了某个节点,比如突然关机了,还没有来得及删除这个文件,也没有来得及改写,就会导致下次启动这个进程的时候,机器去这个目录中扫描一遍,告诉你这个进程已经启动了,但是通过jps看得时候,这个进程确实没有启动,所以如何解决呢?到tmp目录下将对应的pid rm掉。
接着:初始化HA在zookeeper中的状态
//到hadoop_home目录下
bin/hdfs zkfc -formatZK
可以看到在zookeeper中建了一个目录
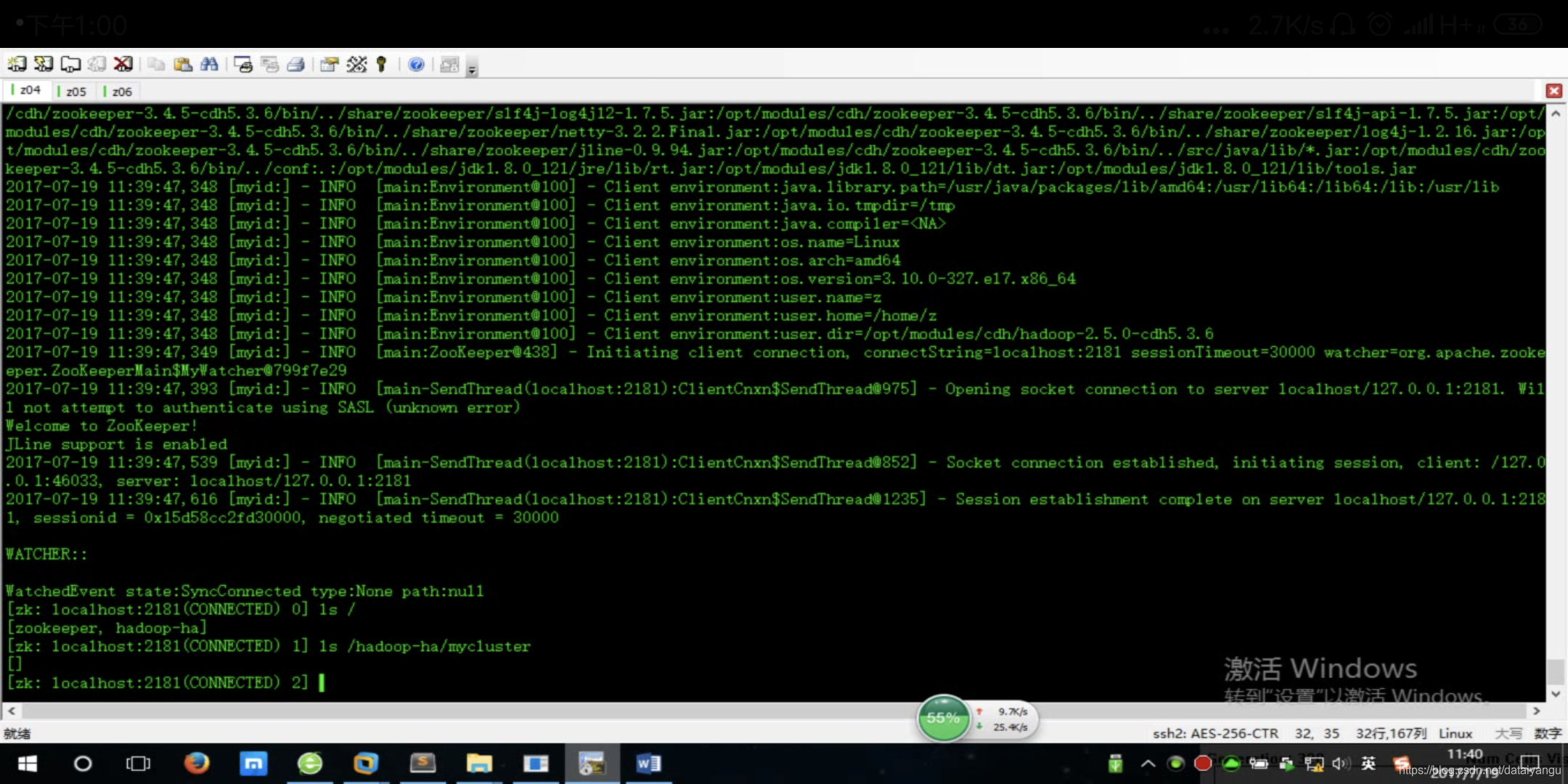
因为刚刚初始化创建的,所以是空的
启动集群
//在哪个机器上启动都可以
sbin/start-dfs.sh
通过jps发现多了 DFSZKFailoverController,即故障自动转移
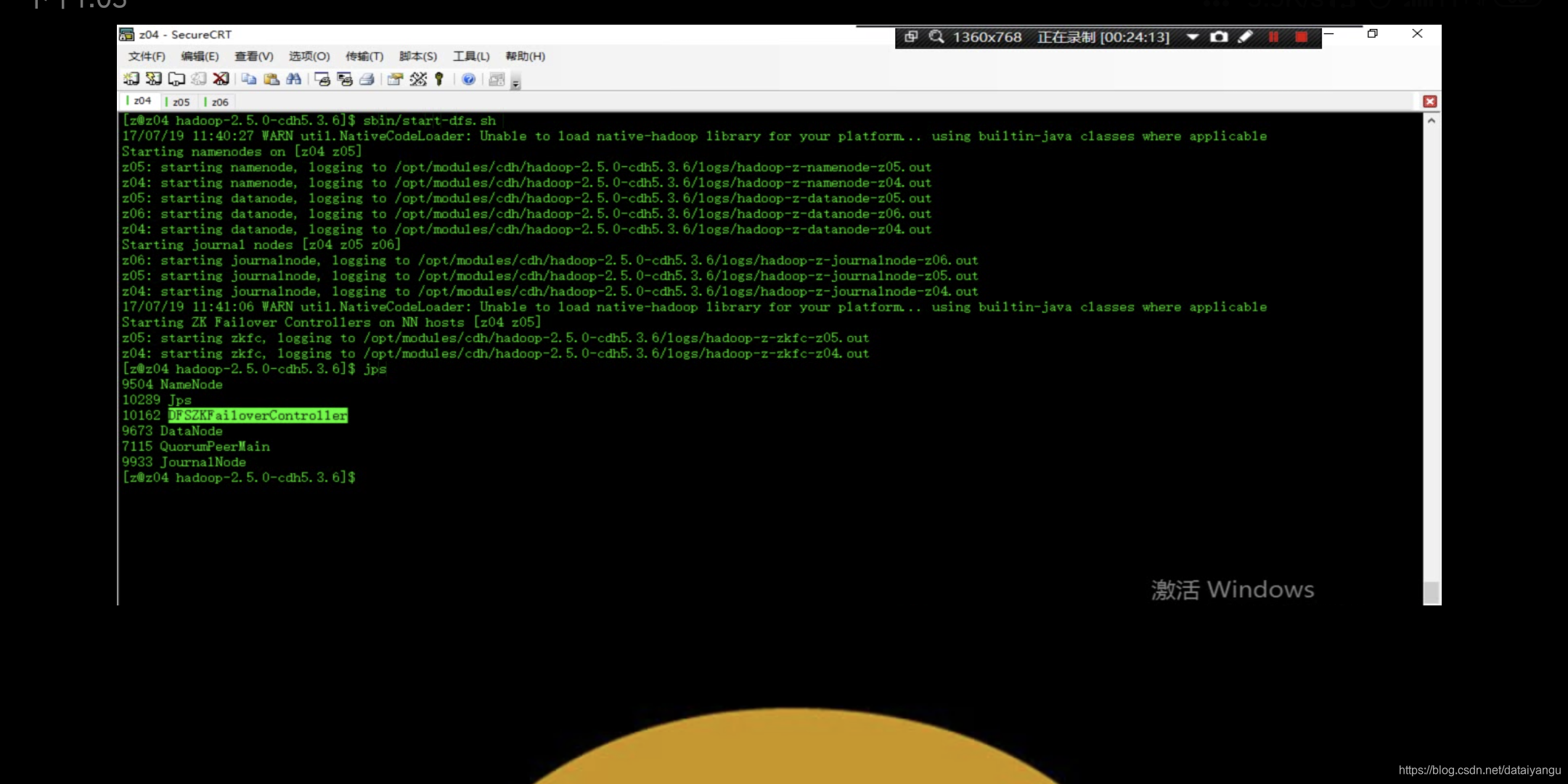
可能会报错
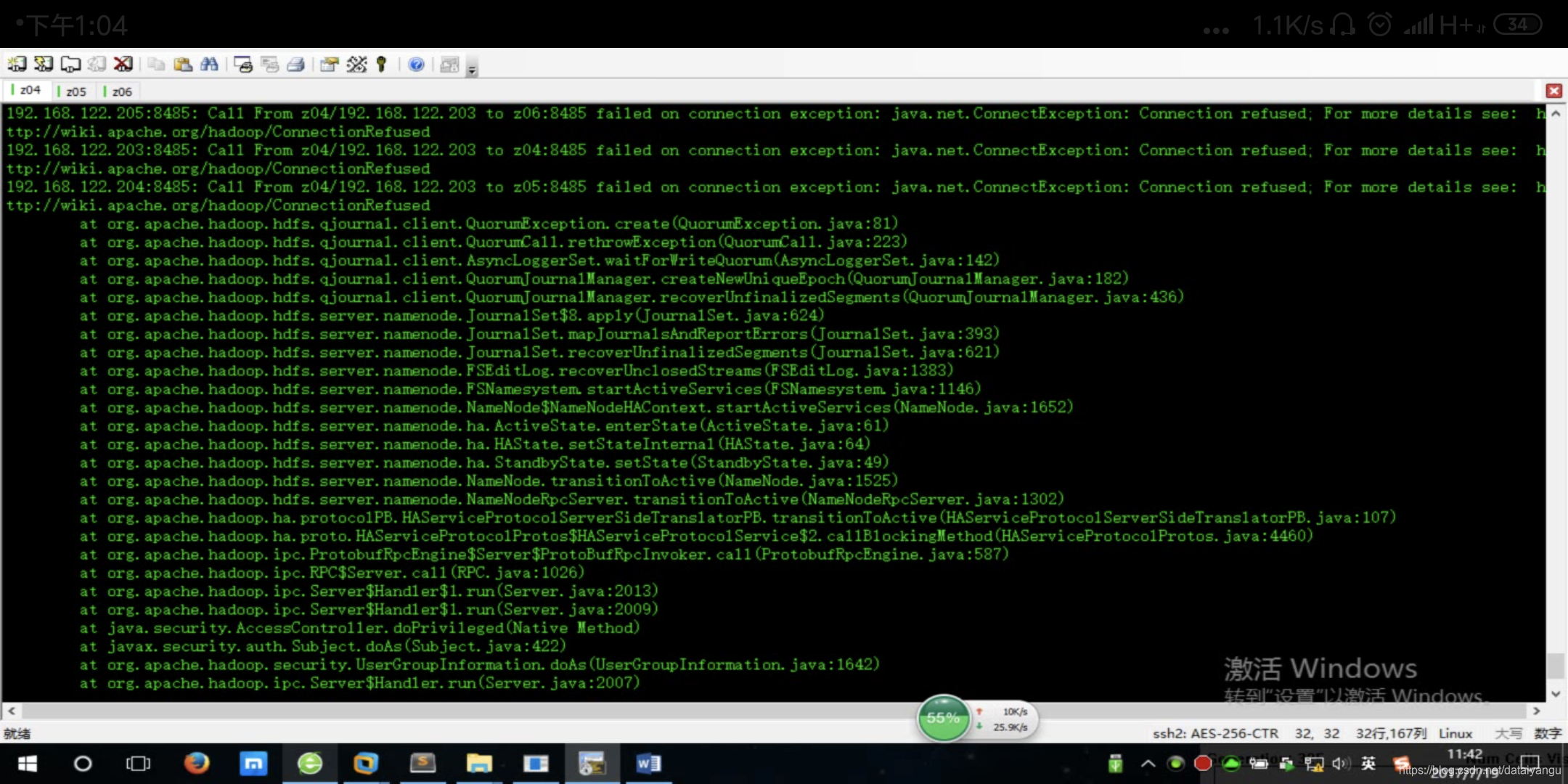
namenode挂掉了,这个问题是因为journalnode的端口和视频中红蜘蛛(录制app)的端口是冲突的,将红蜘蛛拔掉就好了
4.2.2ResourceManager HA
ResourceManager HA和NameNode HA是有区别的,没有JournalNode和controller,是直接把ResourceManager的状态信息写到了zookeeper里。
- yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
//是否支持mapreduce_shuffle,和ha内关系
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
//日志聚合
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
//日志文件系统
//任务历史服务
<property>
<name>yarn.log.server.url</name>
<value>http://z01:19888/jobhistory/logs/</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!--启用resourcemanager ha-->
//重点,真正的HA需要的配置开始
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
//当前ResourceManager集群的名称
<value>cluster-yarn1</value>
</property>
//指定那哪辆台机器实现ResourceManager高可用
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
//第一台地址 z02是地址
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>z05</value>
</property>
//第二台地址
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>z06</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>z01:2181,z02:2181,z03:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
//固定的就这么写就行了
<property>
<name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
教程中示在z05和z06两个机器配置ResourceManager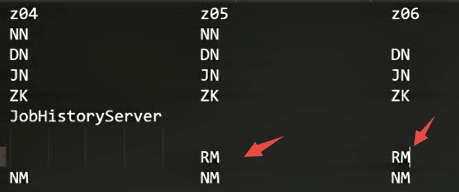
完成后远程拷贝给其他服务器
$ scp etc/hadoop/yarn-site.xml z05:/opt/modules/hadoop-2.5.0/etc/hadoop/
通过jps查看每个服务器的zookeeper服务QuorumPeerMain已经运行,没有运行则开启,方式前文已经说过,不再赘述。
在z05中执行:
$ sbin/start-yarn.sh (启动集群中所有的ResourceManger和NodeManager)
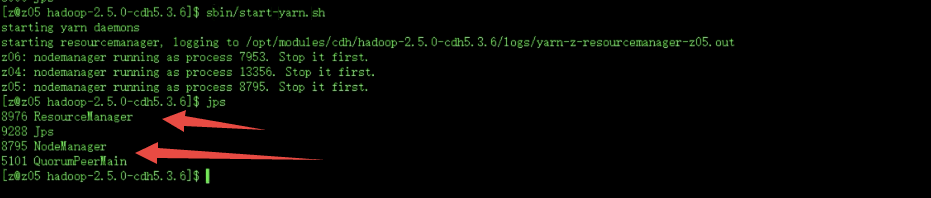
这里注意ResourceManager在哪台机器,就在哪台机器执行这个命令,如果在其他的机器执行命令,ResourceManager会启动不起来,三个机器只会启动NodeManger
页面访问z05:8088
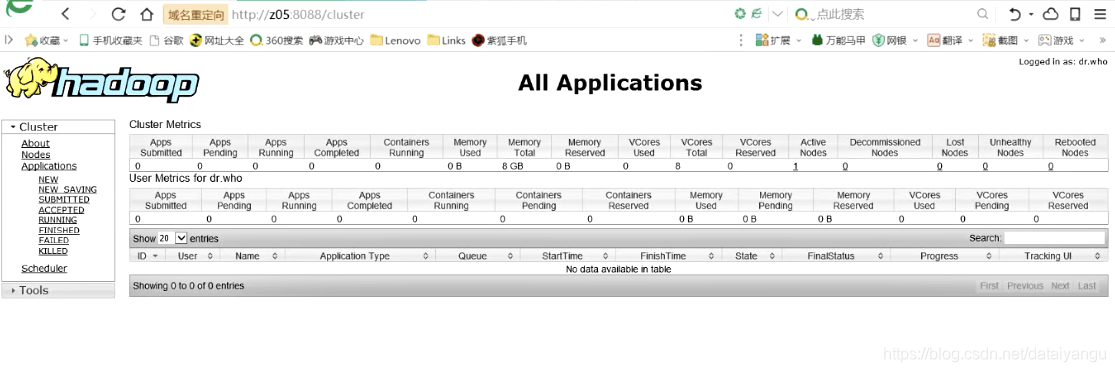
在z06中执行:
$ sbin/yarn-daemon.sh start resourcemanager(同样启动ResourceManager)
查看服务状态
$ bin/yarn rmadmin -getServiceState rm1
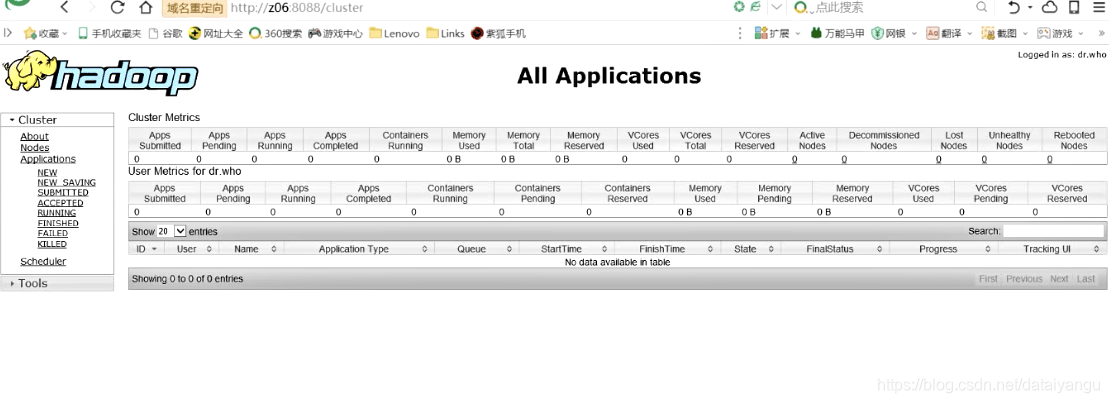
访问z06:8088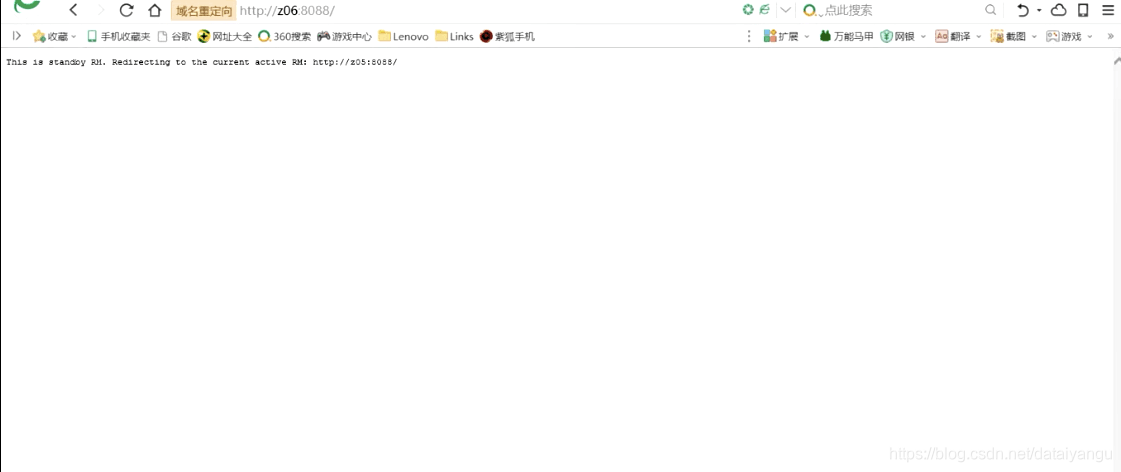
紧接着就会跳转到:
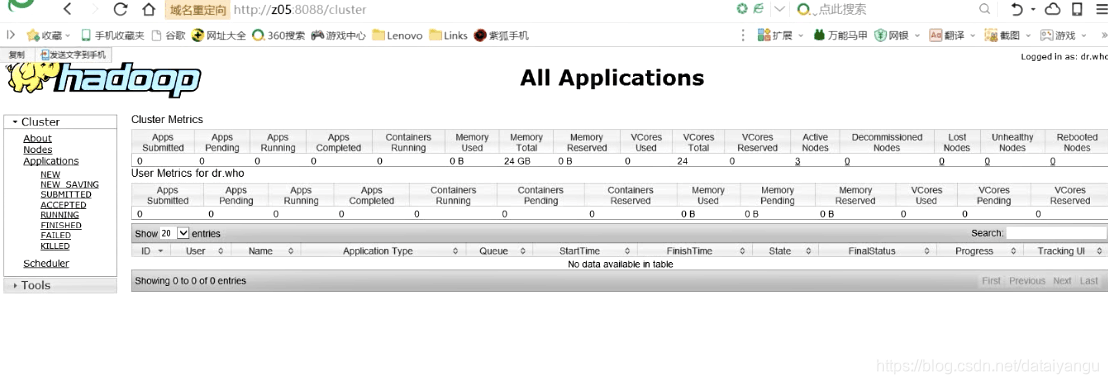
测试
将z05机器的ResourceManager杀掉
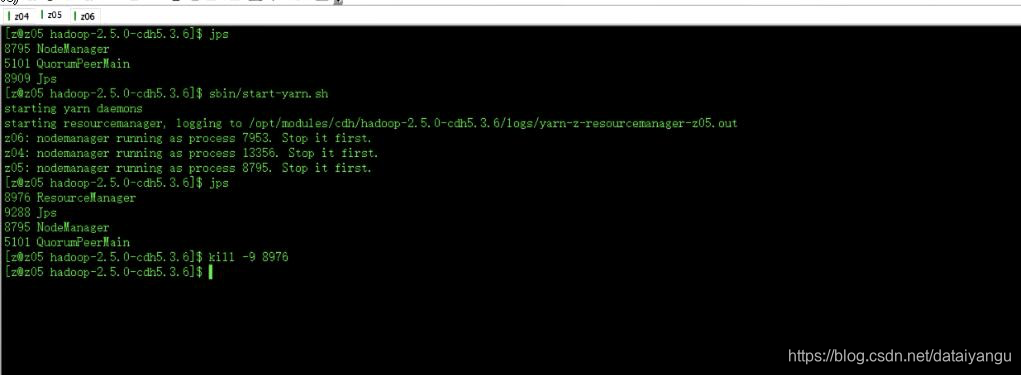
z06会自动上去充分陷阵
具体哪个ResourceManager响应,取决于zookeeper的中保存的ResourceManager的状态。
$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /input/ /output/