版权声明:版权所有,转载请注明出处 https://blog.csdn.net/songchuwang1868/article/details/90144080
如果对ptmalloc的基本设计还不熟悉,请先看:https://blog.csdn.net/songchuwang1868/article/details/89951543
一、bin数组
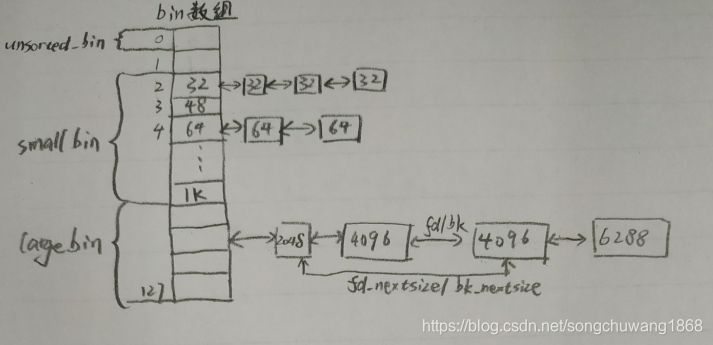
bin数组大体分成三个部分:
1、unsored bin数组
- 暂存一些没有排序的数据
- unsored bin数组中的块马上就会分配给用户或者放到small/large bin数组中
2、small bin数组
- 每项指向一个双向链表,链表中每一项都是一样的大小
- 最小32Byte,16Byte递增,直到1K
3、large bin数组
- 每项是一个范围
- 每项指向的是双向链表,双向链表维护有序的块,除了fd和bk外还有fd_nextsize和bk_nextsize的使用
二、fast bin数组

- 独立于前面的bin数组
- 最小32Byte,16Byte递增,直到128Byte
- 单向链表,便于使用CAS实现无锁操作
- 使用arena分配内存时,先到fast bin中找,找到匹配的块直接返回,找到更大的块,切割需要的大小返回。由于fast bin中的块很散碎而没有找到,摘取fast bin中所有的块,进行合并。将合并后更大的块放到unsored bin中,遍历unsored bin找需要的块,遍历过程中顺便将unsored bin中的块放到small bin和large bin中。
三、arena
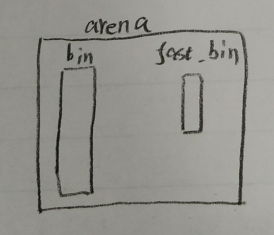
- 每个arena中包含了一个bin和一个fast_bin
- 每个进程中有最多有N个arena,N=cpu_num*2(32位系统),也就是说arena数仅仅与cpu数目相关
- ptmalloc是C库中的功能,所以必定在用户层上,所以必定每个进程一份,也就是说每个进程有N个arena。所有跨越进程的共享资源都在内核中维护
- 同一个进程中的多个线程共享这对应进程中的N个arena
- 多个线程可以绑定到同一个arena上,当部分arena耗尽的情况下,一个线程也可能切换到其他arena
四、top chunk
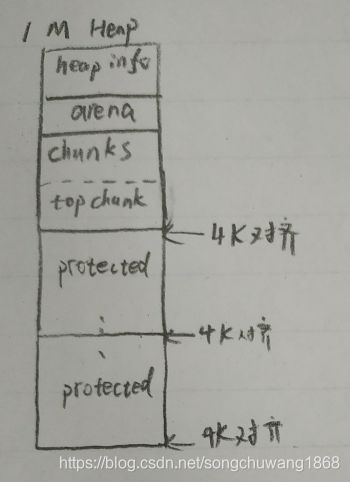
- 每当arena管理的内存不够时,使用mmap(非主arena)或者brk(主arena)分配1M大小的堆空间
- 虽然分配了1M的空间,但不是直接使用,而是每次用4K,也就是每次用一个页面。未用到的页面设定为protected页,如果用户误写了protected页,段错误
- 在一个可用页中切割chunk
- top chunk指向已切割chunk的最后,换言之,每次切割新的chunk,从top chunk处开始
- 当归还内存时,归还的chunk会与top chunk合并(也就是top chunk上移)
五、heap
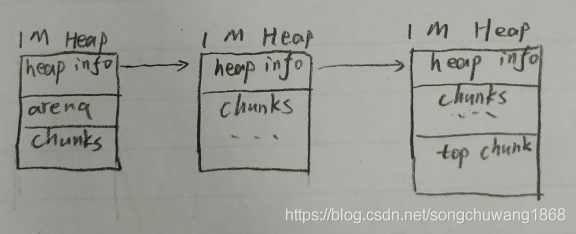
- 这里的heap不是内存布局中的heap,而是一个malloc中的结构体
- arena可能使用的内存超过1M,会分配多个Heap,并用链表维护
- top chunk位域最后一个heap的最后一个chunk的后面
- arena位于第一个Heap中
- Heap1 M对齐,任意一个chunk要找到自己属于哪一个arena是很容易的,只看自己的高位,便能找到自己所属的heap,再定位到相应的arena
- 归还内存,使top chunk位移到heap开始的地方,说明整个heap都归还了,ptmalloc将整个heap还给系统
- ptmalloc这里存在一个槽点,如果中间的heap基本空闲(但有几个chunk还没有回收),但对应的heap却得不到回收
六、thread cache
最新版的ptmalloc向tc malloc学习,使用了线程局部存储来优化设计,线性局部存储不熟请看:https://blog.csdn.net/songchuwang1868/article/details/90143332
ptmalloc中的thread cache有如下特点:
- tcache与small bin类似,最小32Byte,16Byte递增,直到1K
- 每个链表最多7个chunk
- 每次申请内存,先到thread cache中找,没有再到arena中取找