一、可以创建多少个线程
能创建的线程数的具体计算公式如下:
(MaxProcessMemory - JVMMemory - ReservedOsMemory) / (ThreadStackSize) = Number of threads
MaxProcessMemory 指的是一个进程的最大内存,在32位的 windows下是 2G
JVMMemory JVM内存
ReservedOsMemory 保留的操作系统内存
ThreadStackSize 线程栈的大小,默认为1m
由多线程内存溢出产生的实战分析 https://www.jianshu.com/p/54cdcd0fc8a6
JVM最大线程数 https://www.cnblogs.com/princessd8251/articles/3914434.html
二、Redis相关深入
深入学习Redis(3):主从复制 https://www.cnblogs.com/kismetv/p/9236731.html
三、 MySQL数据量大时,delete操作无法命中索引
数据量无论多还是少时,select查询操作都能命中索引:
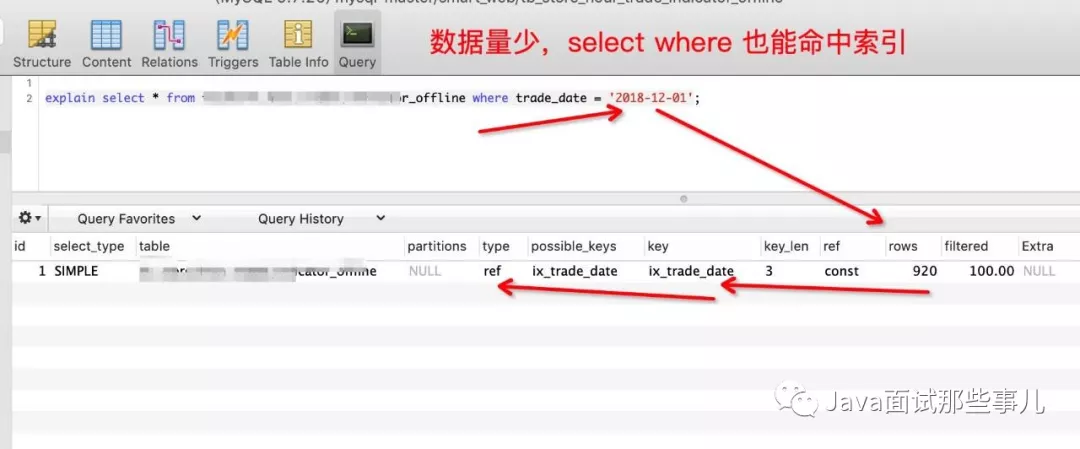

但是数据量少时,delete操作能命中索引,数据量特别大时,delete操作便没办法命中索引:
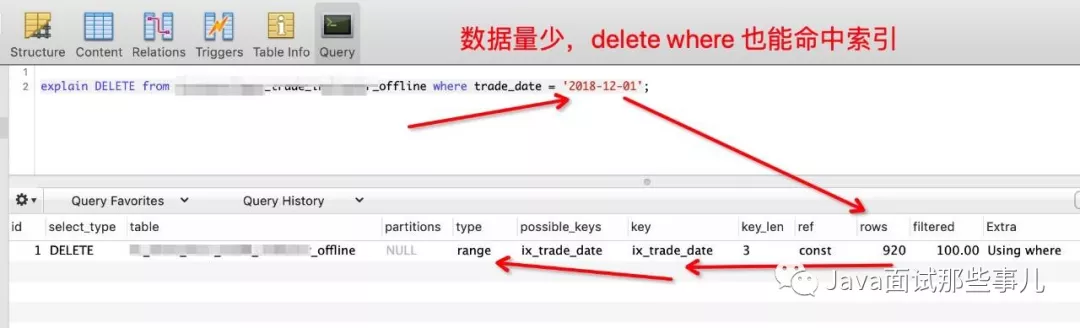
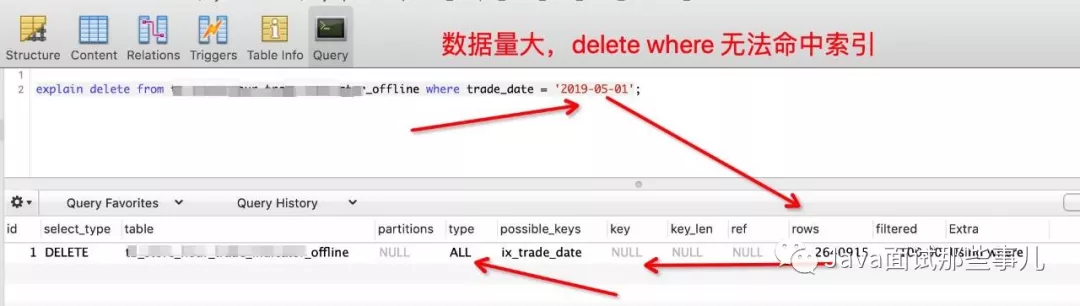
一条SQL语句走哪条索引是通过其中的优化器和代价分析两个部分来决定的。所以,随着数据的不断变化,最优解也要跟着变化。因此如果优化器计算出花费时间太长,就不会使用索引。
对于查询情况,其实MySQL提供给我们一个功能来引导优化器更好的优化,那便是MySQL的查询优化提示(Query Optimizer Hints)。比如,想让SQL强制走索引的话,可以使用 FORCE INDEX 或者USE INDEX;它们基本相同,不同点:在于就算索引的实际用处不大,FORCE INDEX也得要使用索引。
EXPLAIN SELECT * FROM yp_user FORCE INDEX(idx_gender) where gender=1 ;
同样,你也可以通过IGNORE INDEX来忽略索引。
EXPLAIN SELECT * FROM yp_user IGNORE INDEX(idx_gender) where gender=1 ;
虽然有MySQL Hints这种好用的工具,但我建议还是不要再生产环境使用,因为当数据量增长时,你压根儿都不知道这种索引的方式是否还适应于当前的环境,还是得配合DBA从索引的结构上去优化。
四、Java内存模型之happens-before
JMM使用happens-before的概念来阐述多线程之间的内存可见性。
在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。
happens-before原则非常重要,它是判断数据是否存在竞争、线程是否安全的主要依据,依靠这个原则,我们解决在并发环境下两操作之间是否可能存在冲突的所有问题。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。
1 i = 1; //线程A执行 2 j = i ; //线程B执行
例如对于上面的操作,假定使线程A执行1代码,线程B执行2代码。那么j 是否等于1呢?
假定线程A的操作(i = 1)happens-before线程B的操作(j = i),那么可以确定线程B执行后 j = 1 一定成立,
如果A的操作和B的操作不存在happens-before原则,那么j = 1 不一定成立。
happens-before原则定义如下:
1. 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
2. 两个操作之间存在happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。
下面是happens-before原则规则:
1. 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
2. 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作;
3. volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
4. 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
5. 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
6. 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
7.线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
8. 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
上面八条是原生Java满足Happens-before关系的规则,但是我们可以对他们进行推导出其他满足happens-before的规则:
1. 将一个元素放入一个线程安全的队列的操作Happens-Before从队列中取出这个元素的操作
2. 将一个元素放入一个线程安全容器的操作Happens-Before从容器中取出这个元素的操作
3. 在CountDownLatch上的倒数操作Happens-Before CountDownLatch#await()操作
4. 释放Semaphore许可的操作Happens-Before获得许可操作
5. Future表示的任务的所有操作Happens-Before Future#get()操作
6. 向Executor提交一个Runnable或Callable的操作Happens-Before任务开始执行操作
如果两个操作不存在上述(前面8条 + 后面6条)任一一个happens-before规则,那么这两个操作就没有顺序的保障,JVM可以对这两个操作进行重排序。如果操作A happens-before操作B,那么操作A在内存上所做的操作对操作B都是可见的。
private int i = 0; public void write(int j ){ i = j; } public int read(){ return i; }
约定线程A执行write(),线程B执行read(),且线程A优先于线程B执行,那么线程B获得结果是什么?
我们就这段简单的代码一次分析happens-before的规则(规则5、6、7、8 + 推导的6条可以忽略,因为他们和这段代码毫无关系):
1、由于两个方法是由不同的线程调用,所以肯定不满足程序次序规则;
2、两个方法都没有使用锁,所以不满足锁定规则;
3、变量i不是用volatile修饰的,所以volatile变量规则不满足;
4、传递规则肯定不满足;
所以我们无法通过happens-before原则推导出线程A happens-before线程B,虽然可以确认在时间上线程A优先于线程B执行,但是就是无法确认线程B获得的结果是什么,可能获得0,也可能获得线程A指定的值,所以这段代码不是线程安全的。
因此如果想使该端代码满足A操作happens-before B操作,则只需满足规则2、3任一即可。,例如变量 i 定义为volatile类型的或者两个方法均加锁。
面试题:
public class ThreadSafeCache { int result; public int getResult() { return result; } public synchronized void setResult(int result) { this.result = result; } public static void main(String[] args) { ThreadSafeCache threadSafeCache = new ThreadSafeCache(); for (int i = 0; i < 8; i++) { new Thread(() -> { int x = 0; while (threadSafeCache.getResult() < 100) { x++; } System.out.println(x); }).start(); } try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } threadSafeCache.setResult(200); } }
在上面代码中,只对setResult操作加锁,而getResult操作未加锁,在main函数中,起了多个线程执行getResult方法,而在主线程中执行setResult操作。执行结果是子线程一直在执行while操作,无法返回。
问题解析:由于只对setResult操作加锁,而getResult操作未加锁,因此不同线程的set和get操作不满足happens-before原则,因此,多线程并发的同时进行set、get操作,A线程调用set方法,B线程调用get方法并不一定能对这个改变可见!!!
从而导致main线程执行的set操作改变的值无法对子线程可见,即main线程的set操作只是将值更新到main线程的缓存中,而子线程的get操作仍然是从各自的缓存中获取。
解决办法:(1)get操作也加锁,这时便可以满足happens-before原则2:一个unLock操作先行发生于后面对同一个锁的lock操作,从而可见。
(2)变量使用volatile修饰,从而满足happens-before原则3:对一个变量的写操作先行发生于后面对这个变量的读操作,从而可见。
参考:1、阿里一道Java并发面试题 https://mp.weixin.qq.com/s/i9ES7u5MPWCv1n8jYU_q_w
2、【死磕Java并发】-----Java内存模型之happens-before https://www.cnblogs.com/chenssy/p/6393321.html