版权声明:本人原创,码字辛苦,整理代码更是辛苦,转发请说明原处https://blog.csdn.net/qq_37815596谢谢! https://blog.csdn.net/qq_37815596/article/details/88557506
一、简单手动截图(手动截图,推荐使用,本人亲测成功)
1.开发者程序
- Chrome 开发者工具中其实自带了截图命令,按下 ⌘Command + ⌥Option + I(Windows 为 F12)快捷键,召唤出调试界面。
- 随后,按下 ⌘Command + ⇧Shift + P(Windows 为 Ctrl + Shift + P),输入命令 Capture full size screenshot(只输前几个字母就能找到),敲下回车,Chrome 就会自动截取整个网页内容并保存至本地。
- 除了普通长截图以外,你还可以利用这一功能截取手机版网页长图。只需要按下 ⌘Command + ⇧Shift + M (Windows 为 Ctrl + Shift + M)模拟移动设备,再按刚才的方法运行命令就可以了。在顶部的工具栏中,你可以选择要模拟的设备和分辨率等设置。
- 如果你想准确截取网页的某一部分,可以按下 ⌘Command + ⇧Shift + C(Windows 为 Ctrl + Shift + C)嗅探元素。选中想要的部分后,再运行 Capture node screenshot 命令,一张完美的选区截图就诞生了。
2.chrome的扩展程序
- 到chrome的应用商店添加Full Page Screen Capture

![]()
二、html2canvas实现对网站长截图(自动截图,推荐使用,本人亲测成功)
import React, { Component } from 'react';
import html2canvas from 'html2canvas'
import "./App.css"
import LeftFoot from "./[email protected]"
import RightFoot from "./[email protected]"
import purple from "./[email protected]"
class App extends Component {
componentDidMount() {
let shot = document.getElementById('press');
html2canvas(shot).then(function (canvas) {
document.body.appendChild(canvas);
let imgData = canvas.toDataURL('image/png');
console.log("imgData", imgData);
});
}
render() {
return (
<div id="press">
<img src={LeftFoot} alt="LeftFoot" width="500px" height="auto" />
<img src={RightFoot} alt="RightFoot" width="500px" height="auto" />
<img src={purple} alt="purple" width="150px" height="auto" />
</div>
);
}
}
export default App;三、html2canvas+jsPDF实现,页数多时,会自动分页(截图,推荐使用,本人亲测成功)
import React, { Component } from "react";
import { Button, Icon } from "semantic-ui-react";
import "semantic-ui-css/semantic.min.css";
import "./App.css";
import html2canvas from "html2canvas";
import jsPDF from "jspdf";
class App extends Component {
constructor(props) {
super(props);
this.download = this.download.bind(this);
}
download() {
html2canvas(document.body, {
useCORS: true,
allowTaint: false,
scale: 2
}).then(function (canvas) {
var contentWidth = canvas.width;
var contentHeight = canvas.height;
//一页pdf显示html页面生成的canvas高度;
var pageHeight = (contentWidth / 595.28) * 841.89;
//未生成pdf的html页面高度
var leftHeight = contentHeight;
//页面偏移
var position = 0;
//a4纸的尺寸[595.28,841.89],html页面生成的canvas在pdf中图片的宽高
var imgWidth = 595.28;
var imgHeight = (592.28 / contentWidth) * contentHeight;
var pageData = canvas.toDataURL("image/jpeg", 1.0);
var pdf = new jsPDF("", "pt", "a4");
//有两个高度需要区分,一个是html页面的实际高度,和生成pdf的页面高度(841.89)
//当内容未超过pdf一页显示的范围,无需分页
if (leftHeight < pageHeight) {
pdf.addImage(pageData, "JPEG", 0, 0, imgWidth, imgHeight);
} else {
while (leftHeight > 0) {
pdf.addImage(pageData, "JPEG", 0, position, imgWidth, imgHeight);
leftHeight -= pageHeight;
position -= 841.89;
//避免添加空白页
if (leftHeight > 0) {
pdf.addPage();
}
}
}
pdf.save("study.pdf");
});
}
render() {
return (
<div className="device-detail-container">
<Button basic onClick={() => this.download()}>
<Icon name="download" />
Download Report
</Button>
<p>学习下载</p>
</div>
);
}
}
export default App;
四、node实现(这个后台实现,比较复杂,不推荐使用)
- 下载node.js:https://nodejs.org/en/
- 找到node安装的目录(跟本章内容无关,仅仅作为一个小知识)
which node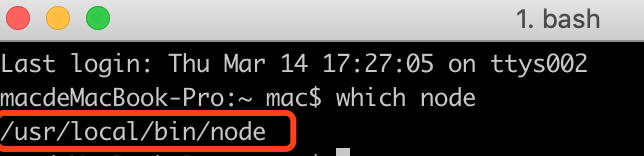
使用command+shift+G,在弹出的目录中填写/usr/local/bin/node就可以了

- 新建一个目录,将目录拖入到iTerm,在iTerm中执行命令
npm i puppeteer- 然后将代码粘贴到新建的test.js内
//开启浏览器模式
const puppeteer = require('puppeteer');
puppeteer.launch({ headless: false,executablePath: 'C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe'}).then(function (browser) {
browser.newPage().then(function (page) {
page.goto('https://www.baidu.com').then(function(){
page.screenshot({path: 'test.png',fullPage:true}).then(function (data) {
//图片资源 自行处理
console.log(data)
})
})
})
});
填自己的谷歌浏览器路径

- 然后执行node test.js
就能跑起来了
五、还有一种方法(本人没有亲自测试,只是看到,感觉不错)
Nodejs中利用phantom把html转为pdf或图片格式