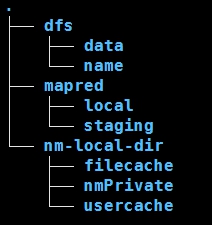
- Dfs:hdfs文件系统,data:datanode目录,name:namenode目录
- Mapred:MapReduce目录
Name目录:
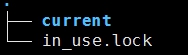
1.Current:里面包含edits、fsimage、seen_txid、VERSION
- edits 日志:客户端执行写操作会先写入edits日志,并且在内存中保留
- Fsimage :namenode的镜像文件,每次checkpoing(合并所有edits到一个fsimage的过程)产生的最终的fsimage,同时会生成一个.md5的文件用来对文件做完整性校验
- Seen_txid :非常重要,他代表namenode的edits*文件尾数,namenode重启时会循序从头跑 edits_0000001~到 seen_txid 的数字。如果format之后会是0
- Version :记录了集群的信息
- namespaceID/clusterID/blockpoolID:在联邦机制中很重要,联邦模式下,会有多个 NameNode 独立工作。每个的 NameNode 提供唯一的命名空(namespaceID),并管理一组唯一的文件块池(blockpoolID)
- cTime NameNode: 存储系统创建时间,首次格式化文件系统这个属性是 0,当文件系统升级之后,该值会更新到升级之后的时间戳
- In_use.lock:防止一台机器同时启动多个Namenode进程导致目录数据不一致
data目录:

current:包含version和bp目录:
BP-random integer-NameNode-IP address-creation time:BP代表BlockPool的,就是Namenode的VERSION中的集群唯一blockpoolID,IP部分和时间戳代表创建该BP的NameNode的IP地址和创建时间戳。bp目录下包括:dfsused,finalized,rbw
- dfsused目录:记录了dfs使用的容量的使用大小
- finalized文件夹:这两个目录都是用于实际存储HDFS BLOCK的数据,里面包含许多block_xx文件以及相应的.meta文件,.meta文件包含了checksum信息。
- rbw 文件夹:表示文件副本正在写入
- tmp文件夹 :表示该副本正在被创建。
说明:
- blk文件:HDFS中的文件块本身,存储的是原始文件内容
- 使用.meta后缀标识:元数据文件由一个包含版本和类型信息的头文件和一系列块的区域校验和组成
- 当数据目录中的块文件达到64个之后,DataNode会在该目录下建立一个子目录(subdirn),将这些块文件移动到该目录下,以避免一个目录存储过多的文件,影响了系统的性能。
- rbw文件:表示该副本正在写入或追加数据。
- rwr:如果DataNode宕机或重启,处于RBW状态的副本将转换为RWR状态,不会在接受新数据的写入。
- RUR :当租约到期,NameNode将为客户端关闭其所占用的副本,这将使该副本进入RUR状态。
Version
版本的信息