在神经网络的结构设计方面,往往遵循如下要点:
- 输入层的单元数等于样本特征数。
- 输出层的单元数等于分类的类型数。
- 每个隐层的单元数通常是越多分类精度越高,但是也会带来计算性能的下降,因此,要平衡质量和性能间的关系。
- 默认不含有隐藏层(感知器),如果含有多个隐层,则每个隐层上的单元数最好保持一致。
因此,对于神经网络模块,我们考虑如下设计:
- 设计 sigmoid 函数作为激励函数:

def sigmoid(z):
"""sigmoid
"""
return 1 / (1 + np.exp(-z))
def sigmoidDerivative(a):
"""sigmoid求导
"""
return np.multiply(a, (1-a))- 设计初始化权值矩阵的函数:
def initThetas(hiddenNum, unitNum, inputSize, classNum, epsilon):
"""初始化权值矩阵
Args:
hiddenNum 隐层数目
unitNum 每个隐层的神经元数目
inputSize 输入层规模
classNum 分类数目
epsilon epsilon
Returns:
Thetas 权值矩阵序列
"""
hiddens = [unitNum for i in range(hiddenNum)]
units = [inputSize] + hiddens + [classNum]
Thetas = []
for idx, unit in enumerate(units):
if idx == len(units) - 1:
break
nextUnit = units[idx + 1]
# 考虑偏置
Theta = np.random.rand(nextUnit, unit + 1) * 2 * epsilon - epsilon
Thetas.append(Theta)
return Thetas- 定义参数展开和参数还原函数:
def unroll(matrixes):
"""参数展开
Args:
matrixes 矩阵
Return:
vec 向量
"""
vec = []
for matrix in matrixes:
vetor = matrix.reshape(1,-1)[0]
vec = np.concatenate((vec,vector))
return vec
def roll(vector, shapes):
"""参数恢复
Args:
vector 向量
shapes shape list
Returns:
matrixes 恢复的矩阵序列
"""
matrixes = []
begin = 0
for shape in shapes:
end = begin + shape[0] * shape[1]
matrix = vector[begin:end].reshape(shape)
begin = end
matrixes.append(matrix)
return matrixes- 定义梯度校验过程:
def gradientCheck(Thetas,X,y,theLambda):
"""梯度校验
Args:
Thetas 权值矩阵
X 样本
y 标签
theLambda 正规化参数
Returns:
checked 是否检测通过
"""
m, n = X.shape
# 前向传播计算各个神经元的激活值
a = fp(Thetas, X)
# 反向传播计算梯度增量
D = bp(Thetas, a, y, theLambda)
# 计算预测代价
J = computeCost(Thetas, y, theLambda, a=a)
DVec = unroll(D)
# 求梯度近似
epsilon = 1e-4
gradApprox = np.zeros(DVec.shape)
ThetaVec = unroll(Thetas)
shapes = [Theta.shape for Theta in Thetas]
for i,item in enumerate(ThetaVec):
ThetaVec[i] = item - epsilon
JMinus = computeCost(roll(ThetaVec,shapes),y,theLambda,X=X)
ThetaVec[i] = item + epsilon
JPlus = computeCost(roll(ThetaVec,shapes),y,theLambda,X=X)
gradApprox[i] = (JPlus-JMinus) / (2*epsilon)
# 用欧氏距离表示近似程度
diff = np.linalg.norm(gradApprox - DVec)
if diff < 1e-2:
return True
else:
return False- 计算代价计算函数:

def computeCost(Thetas, y, theLambda, X=None, a=None):
"""计算代价
Args:
Thetas 权值矩阵序列
X 样本
y 标签集
a 各层激活值
Returns:
J 预测代价
"""
m = y.shape[0]
if a is None:
a = fp(Thetas, X)
error = -np.sum(np.multiply(y.T,np.log(a[-1]))+np.multiply((1-y).T, np.log(1-a[-1])))
# 正规化参数
reg = -np.sum([np.sum(Theta[:, 1:]) for Theta in Thetas])
return (1.0 / m) * error + (1.0 / (2 * m)) * theLambda * reg- 设计前向传播过程:

def fp(Thetas, X):
"""前向反馈过程
Args:
Thetas 权值矩阵
X 输入样本
Returns:
a 各层激活向量
"""
layers = range(len(Thetas) + 1)
layerNum = len(layers)
# 激活向量序列
a = range(layerNum)
# 前向传播计算各层输出
for l in layers:
if l == 0:
a[l] = X.T
else:
z = Thetas[l - 1] * a[l - 1]
a[l] = sigmoid(z)
# 除输出层外,需要添加偏置
if l != layerNum - 1:
a[l] = np.concatenate((np.ones((1, a[l].shape[1])), a[l]))
return a- 设计反向传播过程
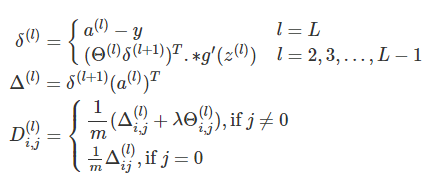
def bp(Thetas, a, y, theLambda):
"""反向传播过程
Args:
a 激活值
y 标签
Returns:
D 权值梯度
"""
m = y.shape[0]
layers = range(len(Thetas) + 1)
layerNum = len(layers)
d = range(len(layers))
delta = [np.zeros(Theta.shape) for Theta in Thetas]
for l in layers[::-1]:
if l == 0:
# 输入层不计算误差
break
if l == layerNum - 1:
# 输出层误差
d[l] = a[l] - y.T
else:
# 忽略偏置
d[l] = np.multiply((Thetas[l][:,1:].T * d[l + 1]), sigmoidDerivative(a[l][1:, :]))
for l in layers[0:layerNum - 1]:
delta[l] = d[l + 1] * (a[l].T)
D = [np.zeros(Theta.shape) for Theta in Thetas]
for l in range(len(Thetas)):
Theta = Thetas[l]
# 偏置更新增量
D[l][:, 0] = (1.0 / m) * (delta[l][0:, 0].reshape(1, -1))
# 权值更新增量
D[l][:, 1:] = (1.0 / m) * (delta[l][0:, 1:] +
theLambda * Theta[:, 1:])
return D- 获得了梯度后,设计权值更新过程:
![]()
def updateThetas(m, Thetas, D, alpha, theLambda):
"""更新权值
Args:
m 样本数
Thetas 各层权值矩阵
D 梯度
alpha 学习率
theLambda 正规化参数
Returns:
Thetas 更新后的权值矩阵
"""
for l in range(len(Thetas)):
Thetas[l] = Thetas[l] - alpha * D[l]
return Thetas- 综上,我们能得到梯度下降过程:
- 前向传播计算各层激活值
- 反向计算权值的更新梯度
- 更新权值
def gradientDescent(Thetas, X, y, alpha, theLambda):
"""梯度下降
Args:
X 样本
y 标签
alpha 学习率
theLambda 正规化参数
Returns:
J 预测代价
Thetas 更新后的各层权值矩阵
"""
# 样本数,特征数
m, n = X.shape
# 前向传播计算各个神经元的激活值
a = fp(Thetas, X)
# 反向传播计算梯度增量
D = bp(Thetas, a, y, theLambda)
# 计算预测代价
J = computeCost(Thetas,y,theLambda,a=a)
# 更新权值
Thetas = updateThetas(m, Thetas, D, alpha, theLambda)
if np.isnan(J):
J = np.inf
return J, Thetas- 则整个网络的训练过程如下:
- 默认由系统自动初始化权值矩阵
- 默认为不含有隐层的感知器神经网络
- 默认隐层单元数为 5 个
- 默认学习率为 1
- 默认不进行正规化
- 默认误差精度为 10−210−2
- 默认最大迭代次数为 50 次
在训练之前,我们会进行一次梯度校验来确定网络是否正确:
def train(X, y, Thetas=None, hiddenNum=0, unitNum=5, epsilon=1, alpha=1, theLambda=0, precision=0.01, maxIters=50):
"""网络训练
Args:
X 训练样本
y 标签集
Thetas 初始化的Thetas,如果为None,由系统随机初始化Thetas
hiddenNum 隐藏层数目
unitNum 隐藏层的单元数
epsilon 初始化权值的范围[-epsilon, epsilon]
alpha 学习率
theLambda 正规化参数
precision 误差精度
maxIters 最大迭代次数
"""
# 样本数,特征数
m, n = X.shape
# 矫正标签集
y = adjustLabels(y)
classNum = y.shape[1]
# 初始化Theta
if Thetas is None:
Thetas = initThetas(
inputSize=n,
hiddenNum=hiddenNum,
unitNum=unitNum,
classNum=classNum,
epsilon=epsilon
)
# 先进性梯度校验
print 'Doing Gradient Checking....'
checked = gradientCheck(Thetas, X, y, theLambda)
if checked:
for i in range(maxIters):
error, Thetas = gradientDescent(
Thetas, X, y, alpha=alpha, theLambda=theLambda)
if error < precision:
break
if error == np.inf:
break
if error < precision:
success = True
else:
success = False
return {
'error': error,
'Thetas': Thetas,
'iters': i,
'success': error
}
else:
print 'Error: Gradient Cheching Failed!!!'
return {
'error': None,
'Thetas': None,
'iters': 0,
'success': False
}训练结果将包含如下信息:(1)网络的预测误差 error;(2)各层权值矩阵 Thetas;(3)迭代次数 iters;(4)是否训练成功 success。
- 预测函数:
def predict(X, Thetas):
"""预测函数
Args:
X: 样本
Thetas: 训练后得到的参数
Return:
a
"""
a = fp(Thetas,X)
return a[-1]完整的神经网络模块为:
# coding: utf-8
# neural_network/nn.py
import numpy as np
from scipy.optimize import minimize
from scipy import stats
def sigmoid(z):
"""sigmoid
"""
return 1 / (1 + np.exp(-z))
def sigmoidDerivative(a):
"""sigmoid求导
"""
return np.multiply(a, (1-a))
def initThetas(hiddenNum, unitNum, inputSize, classNum, epsilon):
"""初始化权值矩阵
Args:
hiddenNum 隐层数目
unitNum 每个隐层的神经元数目
inputSize 输入层规模
classNum 分类数目
epsilon epsilon
Returns:
Thetas 权值矩阵序列
"""
hiddens = [unitNum for i in range(hiddenNum)]
units = [inputSize] + hiddens + [classNum]
Thetas = []
for idx, unit in enumerate(units):
if idx == len(units) - 1:
break
nextUnit = units[idx + 1]
# 考虑偏置
Theta = np.random.rand(nextUnit, unit + 1) * 2 * epsilon - epsilon
Thetas.append(Theta)
return Thetas
def computeCost(Thetas, y, theLambda, X=None, a=None):
"""计算代价
Args:
Thetas 权值矩阵序列
X 样本
y 标签集
a 各层激活值
Returns:
J 预测代价
"""
m = y.shape[0]
if a is None:
a = fp(Thetas, X)
error = -np.sum(np.multiply(y.T,np.log(a[-1]))+np.multiply((1-y).T, np.log(1-a[-1])))
# 正规化参数
reg = -np.sum([np.sum(Theta[:, 1:]) for Theta in Thetas])
return (1.0 / m) * error + (1.0 / (2 * m)) * theLambda * reg
def gradientCheck(Thetas,X,y,theLambda):
"""梯度校验
Args:
Thetas 权值矩阵
X 样本
y 标签
theLambda 正规化参数
Returns:
checked 是否检测通过
"""
m, n = X.shape
# 前向传播计算各个神经元的激活值
a = fp(Thetas, X)
# 反向传播计算梯度增量
D = bp(Thetas, a, y, theLambda)
# 计算预测代价
J = computeCost(Thetas, y, theLambda, a=a)
DVec = unroll(D)
# 求梯度近似
epsilon = 1e-4
gradApprox = np.zeros(DVec.shape)
ThetaVec = unroll(Thetas)
shapes = [Theta.shape for Theta in Thetas]
for i,item in enumerate(ThetaVec):
ThetaVec[i] = item - epsilon
JMinus = computeCost(roll(ThetaVec,shapes),y,theLambda,X=X)
ThetaVec[i] = item + epsilon
JPlus = computeCost(roll(ThetaVec,shapes),y,theLambda,X=X)
gradApprox[i] = (JPlus-JMinus) / (2*epsilon)
# 用欧氏距离表示近似程度
diff = np.linalg.norm(gradApprox - DVec)
if diff < 1e-2:
return True
else:
return False
def adjustLabels(y):
"""校正分类标签
Args:
y 标签集
Returns:
yAdjusted 校正后的标签集
"""
# 保证标签对类型的标识是逻辑标识
if y.shape[1] == 1:
classes = set(np.ravel(y))
classNum = len(classes)
minClass = min(classes)
if classNum > 2:
yAdjusted = np.zeros((y.shape[0], classNum), np.float64)
for row, label in enumerate(y):
yAdjusted[row, label - minClass] = 1
else:
yAdjusted = np.zeros((y.shape[0], 1), np.float64)
for row, label in enumerate(y):
if label != minClass:
yAdjusted[row, 0] = 1.0
return yAdjusted
return y
def unroll(matrixes):
"""参数展开
Args:
matrixes 矩阵
Return:
vec 向量
"""
vec = []
for matrix in matrixes:
vector = matrix.reshape(1, -1)[0]
vec = np.concatenate((vec, vector))
return vec
def roll(vector, shapes):
"""参数恢复
Args:
vector 向量
shapes shape list
Returns:
matrixes 恢复的矩阵序列
"""
matrixes = []
begin = 0
for shape in shapes:
end = begin + shape[0] * shape[1]
matrix = vector[begin:end].reshape(shape)
begin = end
matrixes.append(matrix)
return matrixes
def fp(Thetas, X):
"""前向反馈过程
Args:
Thetas 权值矩阵
X 输入样本
Returns:
a 各层激活向量
"""
layers = range(len(Thetas) + 1)
layerNum = len(layers)
# 激活向量序列
a = range(layerNum)
# 前向传播计算各层输出
for l in layers:
if l == 0:
a[l] = X.T
else:
z = Thetas[l - 1] * a[l - 1]
a[l] = sigmoid(z)
# 除输出层外,需要添加偏置
if l != layerNum - 1:
a[l] = np.concatenate((np.ones((1, a[l].shape[1])), a[l]))
return a
def bp(Thetas, a, y, theLambda):
"""反向传播过程
Args:
a 激活值
y 标签
Returns:
D 权值梯度
"""
m = y.shape[0]
layers = range(len(Thetas) + 1)
layerNum = len(layers)
d = range(len(layers))
delta = [np.zeros(Theta.shape) for Theta in Thetas]
for l in layers[::-1]:
if l == 0:
# 输入层不计算误差
break
if l == layerNum - 1:
# 输出层误差
d[l] = a[l] - y.T
else:
# 忽略偏置
d[l] = np.multiply((Thetas[l][:,1:].T * d[l + 1]), sigmoidDerivative(a[l][1:, :]))
for l in layers[0:layerNum - 1]:
delta[l] = d[l + 1] * (a[l].T)
D = [np.zeros(Theta.shape) for Theta in Thetas]
for l in range(len(Thetas)):
Theta = Thetas[l]
# 偏置更新增量
D[l][:, 0] = (1.0 / m) * (delta[l][0:, 0].reshape(1, -1))
# 权值更新增量
D[l][:, 1:] = (1.0 / m) * (delta[l][0:, 1:] +
theLambda * Theta[:, 1:])
return D
def updateThetas(m, Thetas, D, alpha, theLambda):
"""更新权值
Args:
m 样本数
Thetas 各层权值矩阵
D 梯度
alpha 学习率
theLambda 正规化参数
Returns:
Thetas 更新后的权值矩阵
"""
for l in range(len(Thetas)):
Thetas[l] = Thetas[l] - alpha * D[l]
return Thetas
def gradientDescent(Thetas, X, y, alpha, theLambda):
"""梯度下降
Args:
X 样本
y 标签
alpha 学习率
theLambda 正规化参数
Returns:
J 预测代价
Thetas 更新后的各层权值矩阵
"""
# 样本数,特征数
m, n = X.shape
# 前向传播计算各个神经元的激活值
a = fp(Thetas, X)
# 反向传播计算梯度增量
D = bp(Thetas, a, y, theLambda)
# 计算预测代价
J = computeCost(Thetas,y,theLambda,a=a)
# 更新权值
Thetas = updateThetas(m, Thetas, D, alpha, theLambda)
if np.isnan(J):
J = np.inf
return J, Thetas
def train(X, y, Thetas=None, hiddenNum=0, unitNum=5, epsilon=1, alpha=1, theLambda=0, precision=0.01, maxIters=50):
"""网络训练
Args:
X 训练样本
y 标签集
Thetas 初始化的Thetas,如果为None,由系统随机初始化Thetas
hiddenNum 隐藏层数目
unitNum 隐藏层的单元数
epsilon 初始化权值的范围[-epsilon, epsilon]
alpha 学习率
theLambda 正规化参数
precision 误差精度
maxIters 最大迭代次数
"""
# 样本数,特征数
m, n = X.shape
# 矫正标签集
y = adjustLabels(y)
classNum = y.shape[1]
# 初始化Theta
if Thetas is None:
Thetas = initThetas(
inputSize=n,
hiddenNum=hiddenNum,
unitNum=unitNum,
classNum=classNum,
epsilon=epsilon
)
# 先进性梯度校验
print 'Doing Gradient Checking....'
checked = gradientCheck(Thetas, X, y, theLambda)
if checked:
for i in range(maxIters):
error, Thetas = gradientDescent(
Thetas, X, y, alpha=alpha, theLambda=theLambda)
if error < precision:
break
if error == np.inf:
break
if error < precision:
success = True
else:
success = False
return {
'error': error,
'Thetas': Thetas,
'iters': i,
'success': error
}
else:
print 'Error: Gradient Cheching Failed!!!'
return {
'error': None,
'Thetas': None,
'iters': 0,
'success': False
}
def predict(X, Thetas):
"""预测函数
Args:
X: 样本
Thetas: 训练后得到的参数
Return:
a
"""
a = fp(Thetas,X)
return a[-1]