抓取豆瓣首页菜单
一、分析
打开豆瓣首页:https://www.douban.com/,

通过前端位置定位,找到上图中的HTML代码
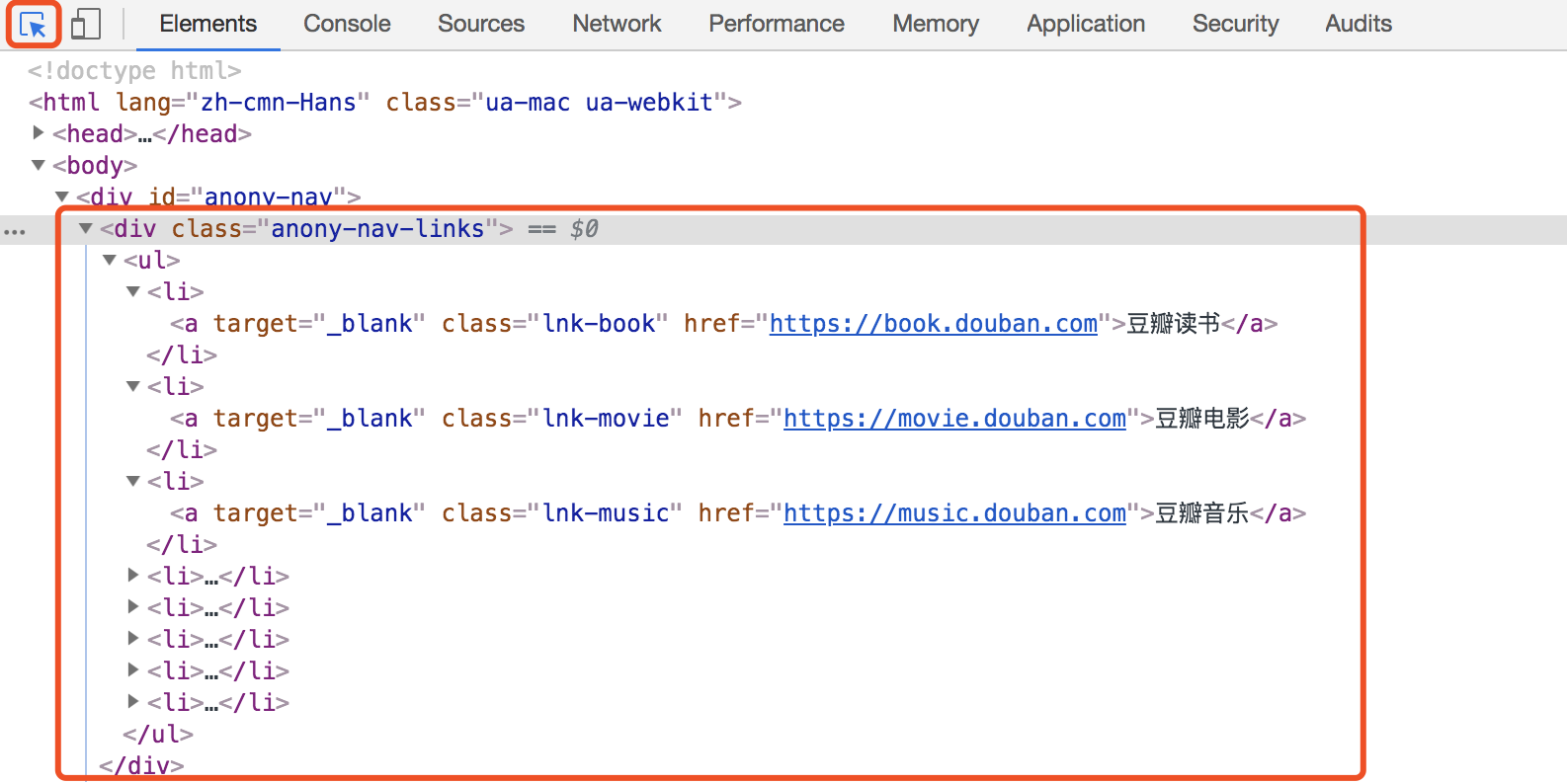
这里要找的代码就是
<div class="anony-nav-links"> ...... </div>
二、代码实现
1 import requests 2 from lxml import etree 3 4 def getPage(url): 5 try: 6 page = requests.get(url) 7 return page 8 except Exception as e: 9 print(str(e)) 10 11 def get_data() : 12 url = 'http://www.douban.com/' 13 data = getPage(url) 14 data.encoding = 'utf-8' 15 selector = etree.HTML(data.text) 16 informations = selector.xpath('//div[@class="anony-nav-links"]/ul/li') 17 for inf in informations: 18 print(inf.xpath('./a/text()')[0]) 19 20 def main() : 21 data = get_data() 22 23 if __name__ == '__main__': 24 main()
注意:XPath 可用来在 XML 文档中对元素和属性进行遍历,这里通过xpath解析元素和属性
运行结果:
豆瓣读书
豆瓣电影
豆瓣音乐
豆瓣小组
豆瓣同城
豆瓣FM
豆瓣时间
豆瓣豆品
成功抓取想要的信息。