2019-oo-第三单元总结
——JML的应用
(1)梳理JML语言的理论基础、应用工具链情况
• JML语言的理论基础
• • 类规格
类的规格包括对数据状态的要求,即invariant(不变式:要求在所有可见状态下都必须满足的特性)和constraint(状态变化约束);
以及对方法的要求。
• •方法规格
方法规格是类规格的组成部分,是JML的重要内容,方法规格的核心内容包括三个方面,前置条件、后置条件和副作用约定。
前置条件是对方法输入参数的限制,如果不满足前置条件,则无法保证方法执行结果的正确性。前置条件通过requires子句来表示;
后置条件是对方法执行结果的限制,如果执行结果满足后置条件,则表示方法执行正确,否则执行错误。后置条件通过ensures子句来表示;
副作用指方法在执行过程中对输入对象或 this 对象进行了修改,使用关键词 assignable 或者 modifiable。
• •常见的原子表达式
\result:表示方法执行后的返回值。
\old( expr ):表示表达式 expr 在相应方法执行前的取值。
• •常见的量化表达式
\forall:全称量词修饰的表达式。
\exists:存在量词修饰的表达式。
\sum:返回给定范围内的表达式的和。
\product:返回给定范围内的表达式的乘积。
\max:返回给定范围内的表达式的最大值。
\min:返回给定范围内的表达式的最小值。
• 应用工具链情况
很多基于JML的验证、调试和测试工具已经非常成熟,比如Runtime Assertion Checker、Junit、OpenJml。利用这些工具,JML规范可以被自动进行动态检验。比如下文中体现的,通过SMT Solver、JMLUnit对代码进行静态推导和动态检查等等。
(2)部署SMT Solver
SMT(Satisfiability modulo theories)求解器在形式化方法、程序语言、软件工程、以及计算机安全、计算机系统等领域得到了广泛应用。
•-check
针对第九次作业的MyPath类,利用-check对规格格式进行了检查

出现了一些小错误,比如

发现是gitlab上官方jar包里的jml和代码中的变量名没有对上,修改后就正确了。
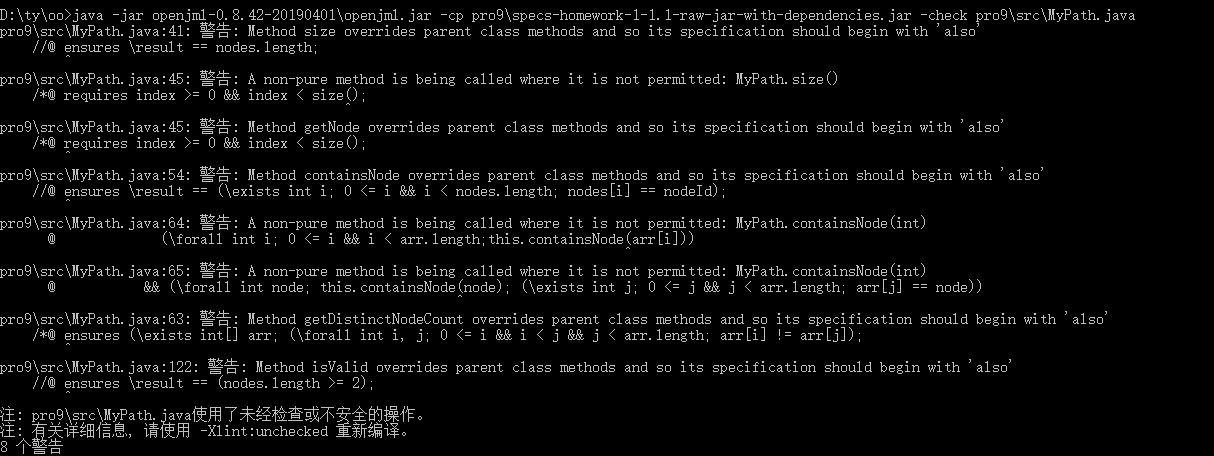
只剩下一些警告。
•-esc 进行静态检查
输入指令,

出现警告信息,如:

因为在CompareTo方法中,将传进来的参数(Path类的对象),转换成了MyPath类型,但并不能保证传进来的对象能够转换成MyPath类,经过检查发现,由于MyPath类继承了Path类,而Path类实现了Comparable<Path>接口,所以这里的CompareTo方法传参一定是Path类型,好像不能修正这个warning。
除此之外,还有下面这个warning,

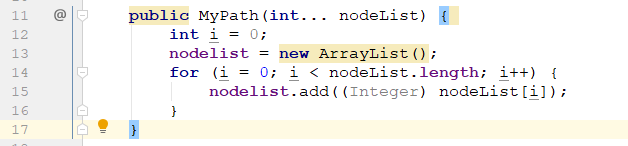
但i从0开始自增,应该不会出现negativ index,有一点点迷惑。
•-rac 进行动态检查

• (3)部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例, 并结合规格对生成的测试用例和数据进行简要分析
首先按照伦佬在讨论区的做法,走了一遍流程。
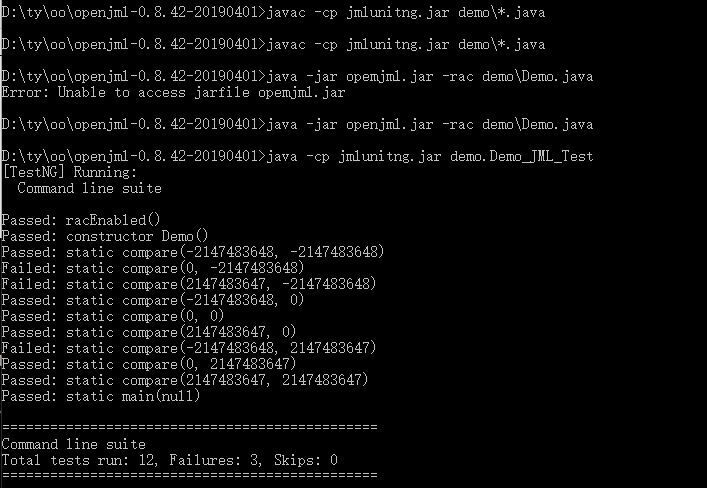
然后,对自己的第九次作业的MyPath类进行了相应实现。
1)先将pro9的path包复制到openjml的文件夹下,简化命令行的命令。
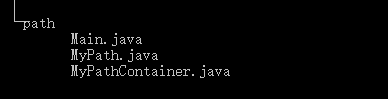
2)执行相应命令




得到如下的目录树
3)结合规格对生成的测试用例和数据进行简要分析
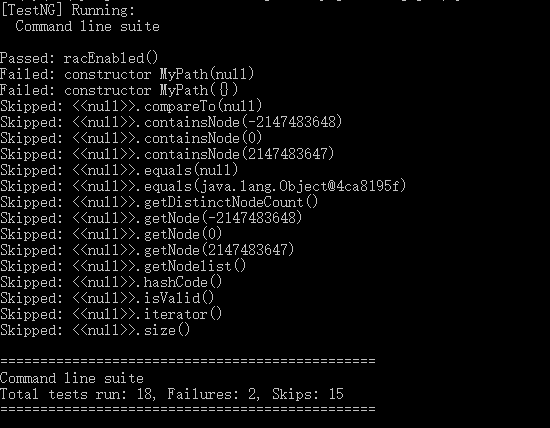
由于边界情况是null数组和空数组,两种情况下MyPath的建立都失败了,所以后续的方法都skip了。
• (4)按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
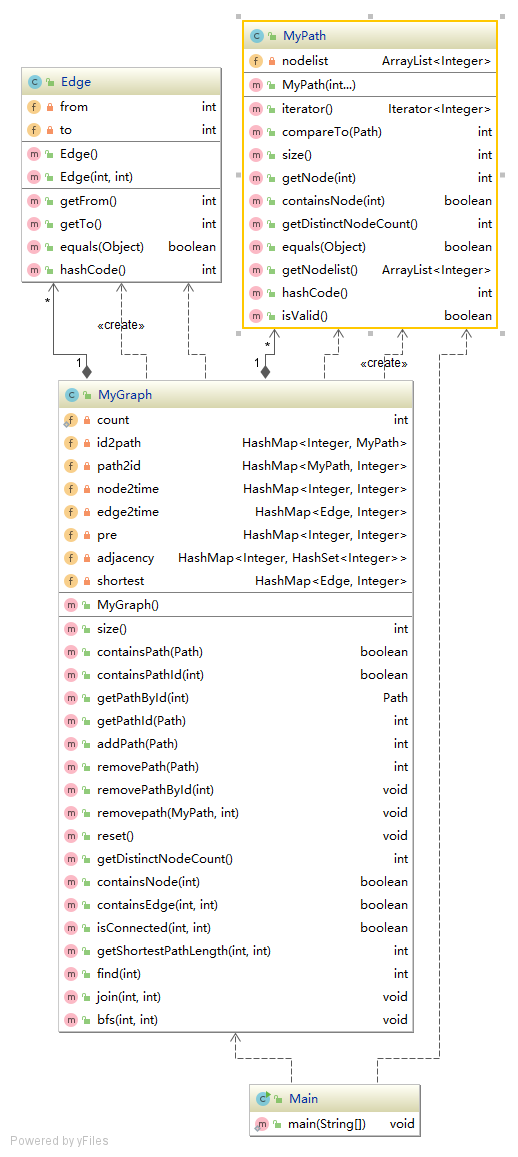
第一次作业:层次简单,通过AppRunner调用了MyPath和MyPathContainer类。

两个类都仅按照规格实现了必须的方法。主要通过各种HashMap来存容器、边、点的关系,减小containsPath、containsNode这些方法的复杂度。
第二次作业:
第二次作业添加的方法主要是判断两个顶点是否连通,以及求两个点的最短路径,分别采取了并查集和bfs的方法来解决这两个问题。
在这次作业中,我没有采用继承,而是复制了上次作业中MyPath类和MyPathContainer类中的大多数代码,对bfs维护一个邻接表,一个中间结果保存表,对并查集维护一个pre数组,即可。
又因为要判断边是否存在,所以考虑构建一个边类,即Edge类,有起点和终点,为hashmap的相关方法重写了hashCode和equals方法。
第三次作业:
结构如下:
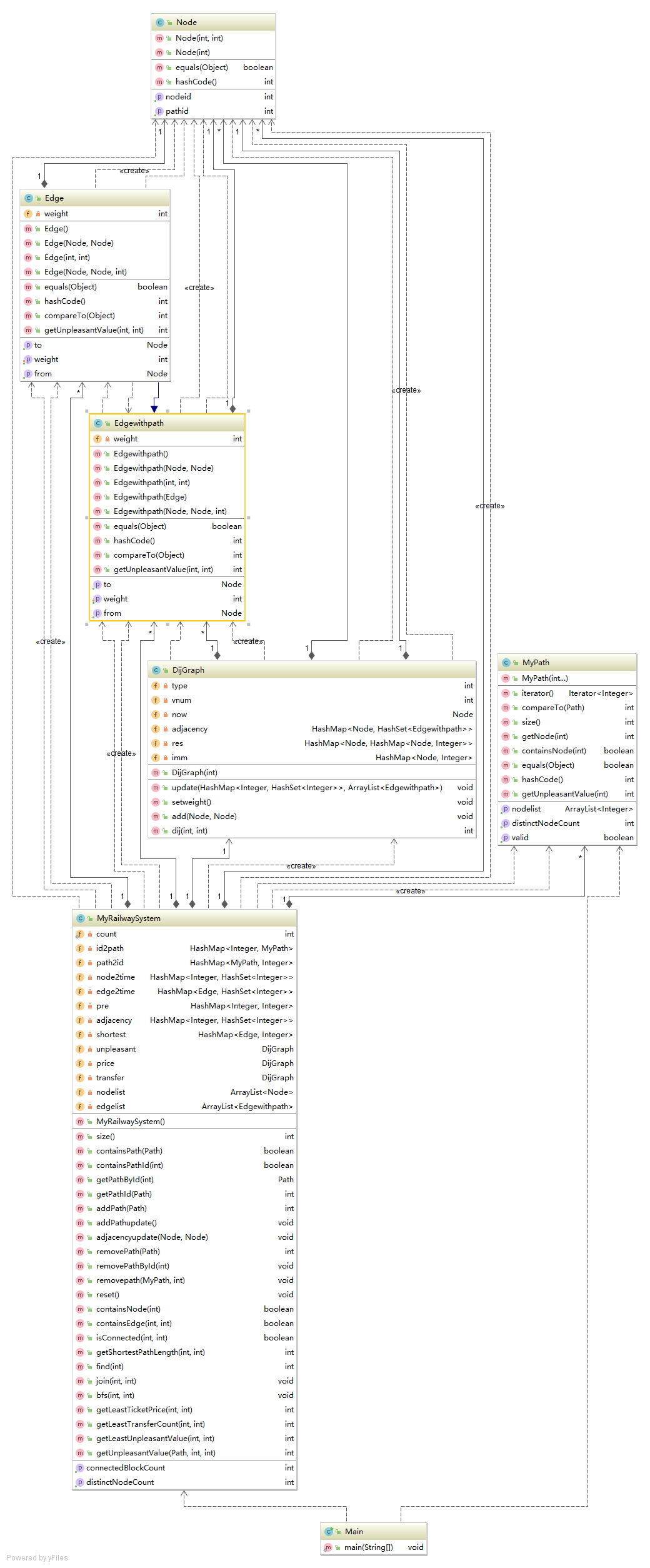
本次作业新添了三个”最短“问题,即最少换乘次数,最少票价,最小不满意度,和一个连通块数,连通块用并查集染色,即可直接用上次作业的代码解决。
对于最短问题,统一采取”拆点+dij“的做法,只是不同问题不同的边权,所以抽象出一个DijGraph类,大部分代码直接复用了第二次作业的Graph类,在RailwaySystem里,初始化三个DijGraph类,分别对应着三个问题。
由于需要换乘,拆点,所以原先用id直接代替结点的方式就不可取了,重新构建了一个Node类,来保存NodeId和PathId,
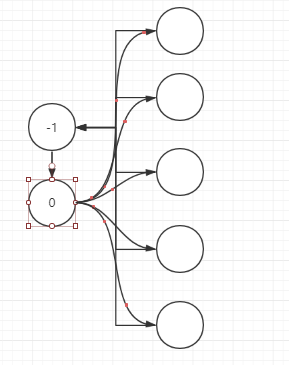
关于拆点,有”菊花点“和”蜘蛛点“两种,前者为每一个点设置两个虚点,即起点和终点,分别设pathid为0和-1,对于每个NodeId,从终点到起点连边的边权为y,其余同NodeId不同PathId的点到终点连边边权为0,起点到,其余同NodeId不同PathId的点连边的边权也为0。对于”蜘蛛点“,即对于同一个NodeId的(n+2)个个点,两两构建边(n为这个NodeId的不同路径数),这样做构建的边数相当之大,导致后序遍历及其他操作非常缓慢。所以最后重构成了前一种连边的方式,下面即这种连边的示意图。
在Dij算法中,要建立key为边,value为最小权值的Hashmap来保存中间结果,但是为指令”容器中是否存在某一条边”构建的Edge类并不考虑结点的pathId是否相同,所以要重构一个Edgewithpath类,from和to都是Node类型,且还要加一个Weight属性来保存权值。两个Edge类之间可以有继承关系。
• (5)按照作业分析代码实现的bug和修复情况
第一次作业无bug。
第二次作业bug出现在addpath时,邻接表更新的时候,Edge2time这个hashmap,即边表更新有误。这一次作业其实思路也很简单,由于add/remove这种对图操作的指令最多只有20条,所以重点在保存中间结果,和正确更新,写的时候为减少重复代码,就给删除path的两条指令即REMOVE_PATH和REMOVE_PATH_BY_ID,构建了一个方法,在这个方法里执行了邻接表,最短路径中间结果保存表,并查集的前序表,的清零工作,同时调用了reset方法,重新构建pre前序表,和adjacency邻接表,整理得较为清晰,然而忽略了addpath的情况。
第三次作业真的是非常非常非常痛心了,交前一个小时魔改,把“蜘蛛点”改成了“菊花点“,解决了可能t掉的隐患,觉得自己稳了,没想到最后爆了6个点,全是因为一句话的问题,在MyPath类中,有一句比较用的”==“而不是equals,虽然我记得上一次作业专门检查过,这里没有问题,可能是检查不全面,总之,是非常遗憾了!
• (6)阐述对规格撰写和理解上的心得体会
与自然语言相比,JML减少了二义性,也更为的复杂和繁琐,很多简单的描述都需要大段的逻辑描述,刚开始学习的时候感到很不适应,openjml也大段大段地报错。但后来逐渐发现根据规格写代码效率很高。
首先,思路清晰,架构简洁,几次作业中,都只需要我们完成少数类的方法填写,即基于规格和需求出发,完成方法的实现,不需要我们自己构建一些风格丑陋的架构(虽然最后一次作业我的风格也并不美)。
其次,利用junit等工具可以很好地对代码进行测试,虽然自己写test也有不完全的时候,但已经比随机测试要让人放心得多了。
但是使用openjml等工具链的时候,会发现已有的资料非常少,导致很难上手,一点也不新手友好!还好有很多大佬写出了科普贴,我才能完成这次博客作业,再次感谢!!