app
1 基于spark的用户程序,包含了一个driver program和集群中多个executor 2 driver和executor存在心跳机制确保存活
3 --conf spark.executor.instances=5 --conf spark.executor.cores=8 --conf spark.executor.memory=80G
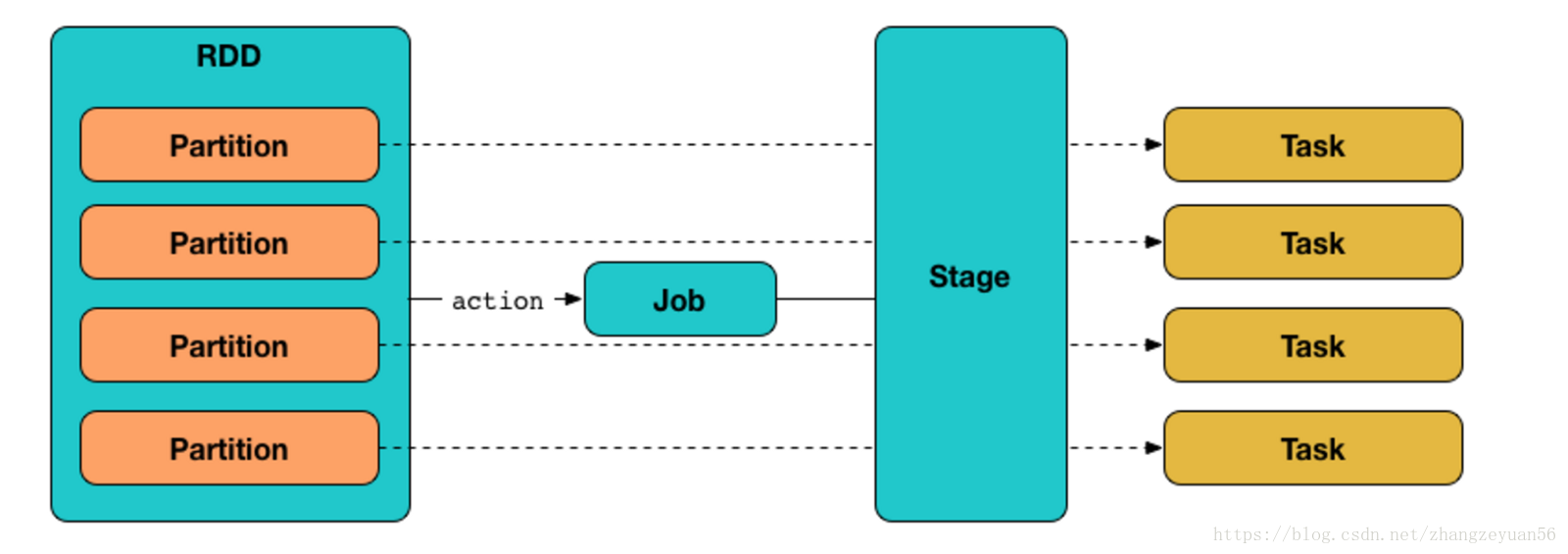
rdd
1 弹性分布式数据集 2 只读的、分区(partition)记录的集合 3 初代rdd处于血统的顶层,记录任务所需的数据的分区信息,每个分区数据的读取方法 4 子代rdd不真正的存储信息,只记录血统信息 5 真正的数据读取,应该是task具体被执行的时候,触发action操作的时候才发生的
算子
1 分为transformation和action 2 transformation: map filter flatMap union groupByKey reduceByKey sortByKey join 3 action: reduce collect count first saveAsTextFile countByKey foreach
partition
1 rdd存储机制类似hdfs,分布式存储 2 hdfs被切分成多个block(默认128M)进行存储,rdd被切分为多个partition进行存储 3 不同的partition可能在不同的节点上 4 再spark读取hdfs的场景下,spark把hdfs的block读到内存就会抽象为spark的partition 5 将RDD持久化到hdfs上,RDD的每个partition就会存成一个文件,如果文件小于128M,就可以理解为一个partition对应hdfs的一个block。反之,如果大于128M,就会被且分为多个block,这样,一个partition就会对应多个block。
job
1 一个action算子触发一个job 2 一个job中有好多的task,task是执行job的逻辑单元(猜测是根据partition划分任务) 3 一个job根据是否有shuffle发生可以分为好多的stage
stage
1 rdd中的依赖关系(血统)分为宽依赖和窄依赖 2 窄依赖:父RDD的一个分区只被一个子RDD的分区使用,不产生shuffle,即父子关系为“一对一”或者“多对一” 3 宽依赖:产生shuffle,父子关系为“一对多”或者“多对多” 4 spark根据rdd之间的依赖关系形成DAG有向无环图,DAG提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是rdd之间的宽窄依赖 5 遇到宽依赖就划分stage 6 每个stage包含一个或多个task任务 7 这些task以taskSet的形式提交给TaskScheduler运行 8 stage是由一组并行的task组成 9 stage切割规则:从后往前,遇到宽依赖就切割stage。
10 一个stage以外部文件或者shuffle结果作为开始,以产生shuffle或者生成最终结果时结束
11 猜测stage与TaskSet为一一对应的关系
task
1 分为两种:shuffleMapTask和resultTask 2 拆分task猜测和partition有关 3 --conf spark.default.parallelism=1000 设置task并行的数量 4 个人理解以上各种概念都是抽象概念,即简单的理解为全部发生在driver端,只有task相关的信息会被序列化发送到executor去执行
参考链接:
https://www.cnblogs.com/jechedo/p/5732951.html
https://www.2cto.com/net/201802/719956.html
https://blog.csdn.net/fortuna_i/article/details/81170565
https://www.2cto.com/net/201712/703261.html
https://blog.csdn.net/zhangzeyuan56/article/details/80935034
https://www.jianshu.com/p/3e79db80c43c?from=timeline&isappinstalled=0