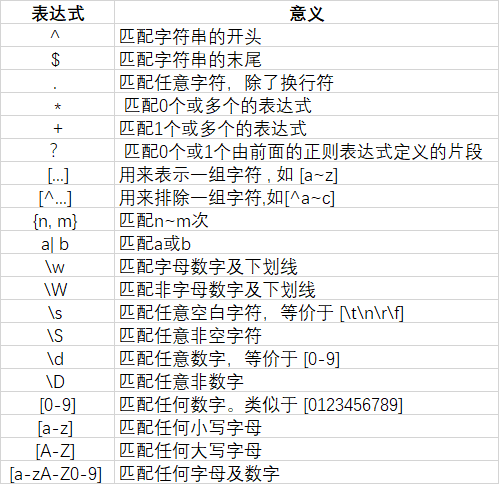
表达式
所以在上一篇的url匹配的正则代表空

准备数据
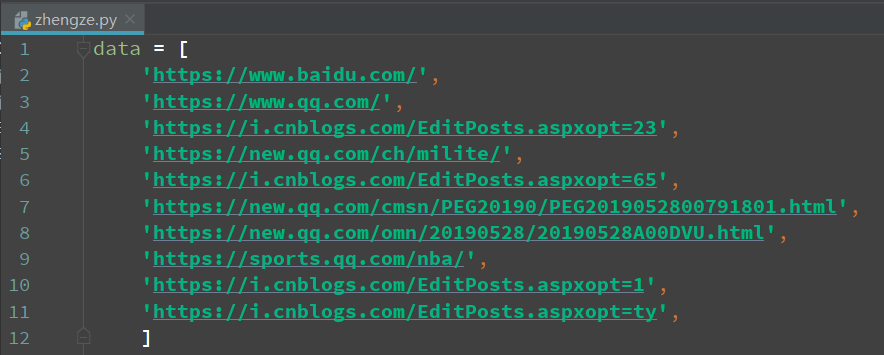
data = [
'https://www.baidu.com/',
'https://www.qq.com/',
'https://i.cnblogs.com/EditPosts.aspxopt=23',
'https://new.qq.com/ch/milite/',
'https://i.cnblogs.com/EditPosts.aspxopt=65',
'https://new.qq.com/cmsn/PEG20190/PEG2019052800791801.html',
'https://new.qq.com/omn/20190528/20190528A00DVU.html',
'https://sports.qq.com/nba/',
'https://i.cnblogs.com/EditPosts.aspxopt=1',
'https://i.cnblogs.com/EditPosts.aspxopt=ty',
]
不用正则,用string的方式情况下提取数据
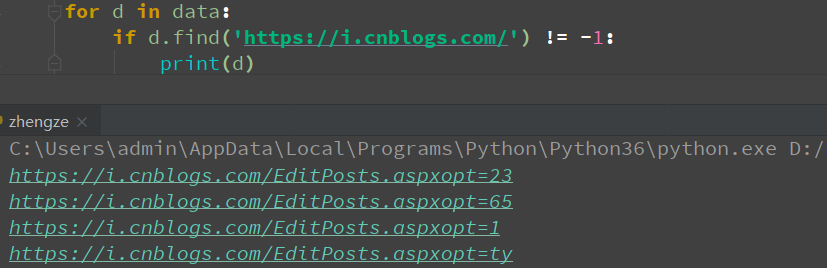
for d in data:
if d.find('https://i.cnblogs.com/') != -1:
print(d)
用正则
re.search():
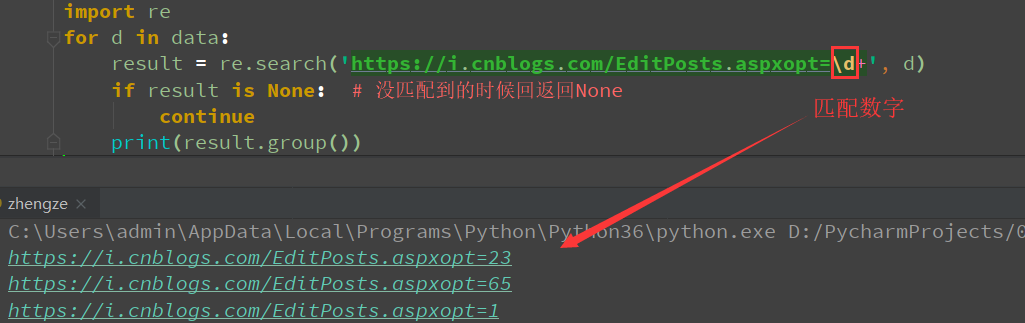
import re
for d in data:
result = re.search('https://i.cnblogs.com/EditPosts.aspxopt=\d+', d)
if result is None: # 没匹配到的时候回返回None
continue
print(result.group())
可见用正则匹配的更精确
re.findall():返回内容是list
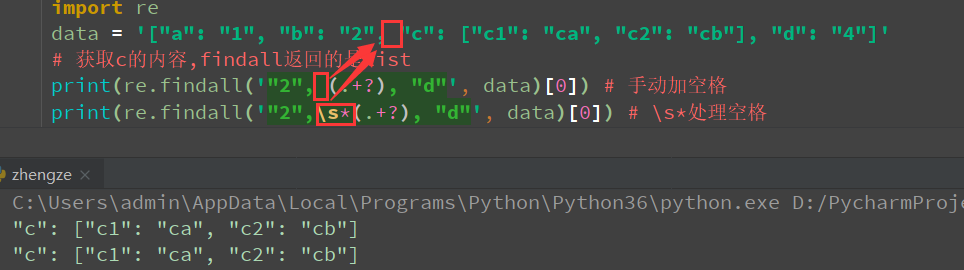
import re
data = '["a": "1", "b": "2", "c": ["c1": "ca", "c2": "cb"], "d": "4"]'
# 获取c的内容,findall返回的是list
print(re.findall('"2", (.+?), "d"', data)[0]) # 手动加空格
print(re.findall('"2",\s*(.+?), "d"', data)[0]) # \s*处理空格