队列这个数据结构已经很熟悉了,就不多介绍,主要还是根据代码理解Doug Lea大师的一些其他技巧。
入队
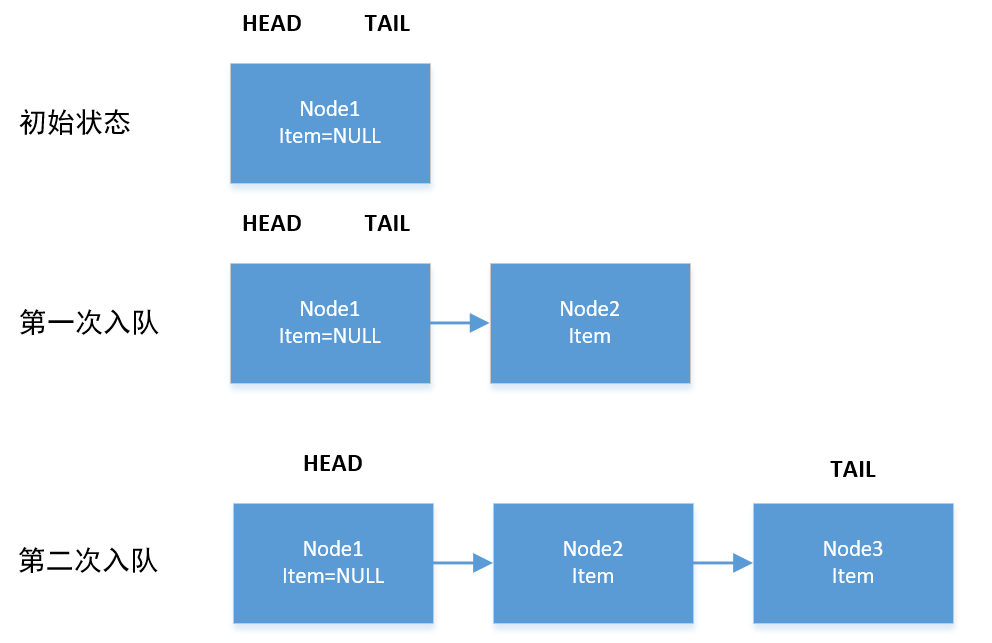
如图所示,很多人可能会很疑惑,为什么第一次入队后,TAIL没有指向Node2?答案是为了效率!Σ(っ °Д °;)っ 那这还能叫队列吗?当然,它依然符合先进先出(FIFO)的规则。只是TAIL变量不一定指向尾结点,那么来看看大师是怎么做的。
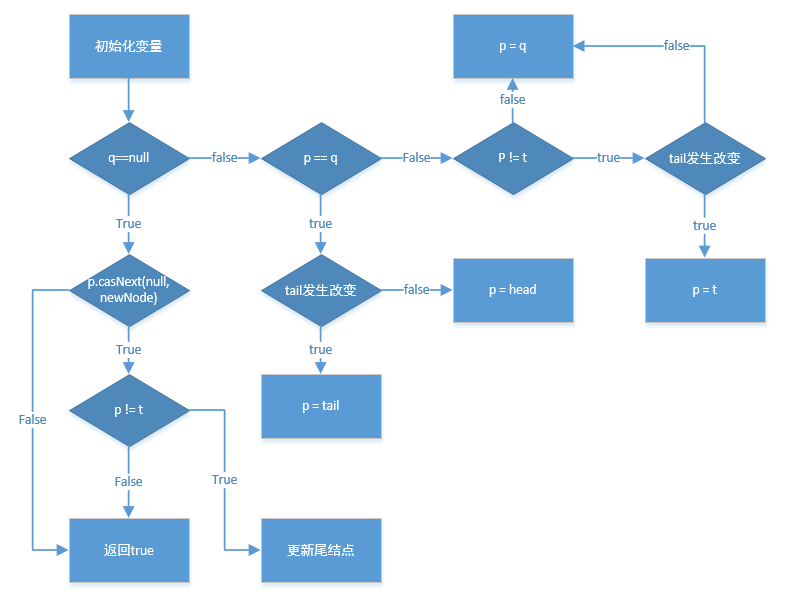
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p是tail结点
if (p.casNext(null, newNode)) {
// 判断p结点是否是尾结点
// 这一步不执行的话,不会对整体流程造成影响,至多是多一次循
// 环,相比CAS操作,更愿意多一次循环
if (p != t)
// 交换Tail结点,如果CAS更新失败表示已经有其他线程对其进行更新
casTail(t, newNode);
return true;
}
// CAS竞争失败,重新循环,竞争失败后q一般不会为null,除非又发生了出队
}
// HEAD和TAIL都指向同一个结点
// 一个线程执行入队,一个线程执行出队,假设前面都没有更新tail和head
// 执行出队的线程更新HEAD并设置其为自引用
// 那么就会发生这个条件想要的现象
else if (p == q)
// 如果tail发生了改变,那么就为p设置t,并重新寻找
// 如果tail未发生改变,head发生了改变,保
// 险方法就是重新从新head开始遍历
// 注意: -----只要在读取前完成tail发生更新就行了-----
p = (t != (t = tail)) ? t : head;
else
// p != t 表示p不是尾结点,发生的原因是 入队时没有更新尾结点
// t != (t = tail) 更新tail,如果tail被其他线程修改,则返回true
// 如果为true,重新将p设置为尾结点(此时尾结点已经更新了)
// 如果为false,p = q,继续循环下去
p = (p != t && t != (t = tail)) ? t : q;
}
}
第一次入队:
- 初始状态下head和tail都指向同一个item为null的结点
- tail没有后继结点
- 尝试CAS为tail设置next结点
- p == t,没有更新tail变量,直接返回true
注意offer永远都返回true
第二次入队:
- 初始状态下head和tail都指向同一个item为null的结点,但是next指向Node2
- tail有后继结点
- p != q,进入下个if语句
- p == t 返回false,整个三目运算符返回false,p = t
- 此时p没有后继结点
- 尝试CAS为p设置next
- p != t,更新tail结点,直接返回true
第二次入队多线程版
线程A执行入队,线程B执行出队
初始状态图如下所示:
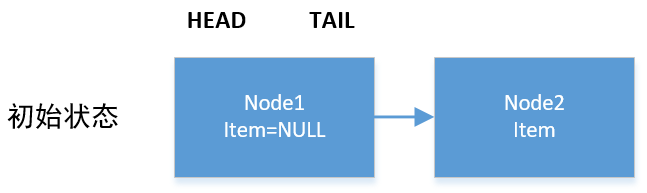
操作步骤如下表所示:
| 次序 | 线程A | 线程B |
|---|---|---|
| 1 | ||
| 2 | node1.item == null,执行下个if语句 | |
| 3 | (q = node1.next) != null,执行下个if语句 | |
| 4 | p != q,执行后面的else语句 | |
| 5 | p = q | |
| 6 | node2.item != null | |
| 7 | p != h (p是node2) | |
| 8 | (q = p.next) == null,故将p设置为头结点,即将node2作为头结点 | |
| 9 | 将node1设置为自引用 | |
| 10 | q = p.next,即node1.next,因为自引用q == p | 返回item |
| 11 | q != null | |
| 12 | p == q | |
| 13 | t != (t = tail),即此时tail是否发生改变:true -> p =tail;false -> p = head |
在步骤13,如果有个线程C已经执行了入队且tail发生改变,那么p就直接紧跟着更新后的tail就行了;如果tail没更新,就要设置p = head,然后重新循环遍历。
出队
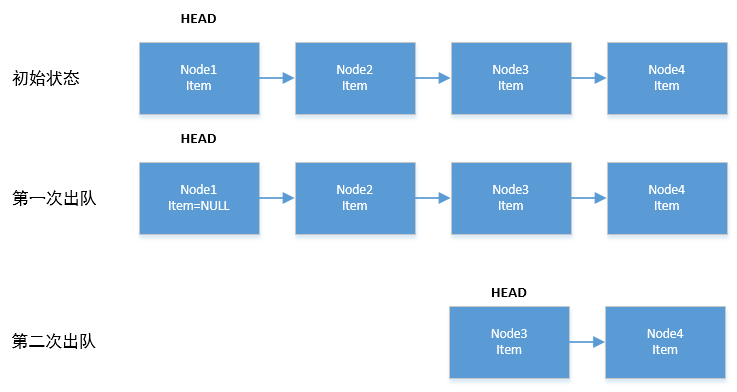
从图中可以看出每次出队会有两种可能:将首结点的item置空,不移除;或是将移除首结点。总结一下,就是每次出队更新HEAD结点时,当HEAD结点里有元素时,直接弹出HEAD结点内的元素,而不会直接更新HEAD结点。只有当HEAD结点里没有元素时,出队操作才会更新HEAD结点。这种做法是为了减少CAS更新HEAD结点的消耗,从而提高出队效率。
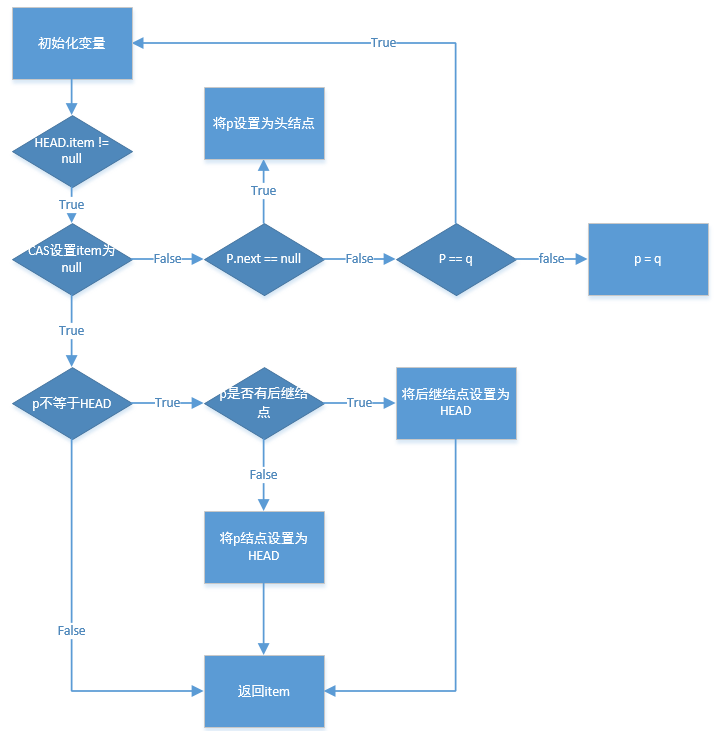
public E poll() {
restartFromHead:
for (;;) {
// p变量可以理解为游标、当前处理的结点,用于遍历的
// q变量可以理解为p变量的next
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// ① 先判断当前结点的值不为null 且 CAS更新p变量的item值
if (item != null && p.casItem(item, null)) {
// ②更新成功后,判断当前结点是否是头结点
// 这一步主要是为了节省CAS操作,因为少更新一次HEAD结点没什么影响
if (p != h)
// ③更新头结点
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
// ④ 获取当前结点的下一个结点,判断是否为null
// 一般发生于只有一个结点的情况
else if ((q = p.next) == null) {
// ⑤ 将当前结点设置为自引用
updateHead(h, p);
return null;
}
// ⑥ 如果当前结点出现自引用
// 一般发生在一个线程更新了头结点,让p结点自引用时,p才会等于q
else if (p == q)
// 重新获取一个头结点
continue restartFromHead;
else
// p = p.next
p = q;
}
}
}
第一次出队:
- 初始状态所有item不为null,尝试更新结点的item(一般情况下都是成功的),更新成功后结点item为null
- 判断 p == h,不满足条件,直接返回item值
第二次出队:
- Node1.item为null,进入下个条件
- (q = p.next) != null,进入下个条件
- p != q,进入下个条件
- p = q,重新循环
- Node2.item不为null,尝试更新结点的item,更新成功后结点item为null
- 判断 p != h,满足条件
- 判断p结点(Node2)是否有后继结点,如果有就将后继结点作为HEAD,否则将P作为HEAD
- 返回item值
第二次出队多线程版1:
线程A和线程B同时执行poll()方法,假设线程A稍快
| 线程A | 线程B |
|---|---|
| A1. Node1.item为null | B1. Node1.item为null |
| A2. (q = p.next) != null | B2. (q = p.next) != null |
| A3. p != q | B3. p != q |
| A4. p = q,循环 | B4. p = q,循环 |
| A5. Node2.item不为null,尝试更新结点item,更新成功,item值为null | B5. |
| A6. 满足条件 p != h | B6. Node2.item为null |
| A7. 判断p结点(Node2)是否有后继结点 | B7. (q = p.next) != null |
| A8. | B8. p != q |
| A9. | B9. p = q 循环 |
| A10. | B10. Node3.item不为null,尝试更新结点item,更新成功,item值为null |
| A11. 将后继结点即Node3设置为HEAD | B11. |
| A12. 返回item | B12. 满足条件 p != h |
| A13. | B13. 判断p结点(Node2)是否有后继结点 |
| A14. | B14. 由于HEAD已经被修改,所以CAS更新失败 |
| A15. | B15. 返回item |
这里主要是想讲即便HEAD更新发生冲突,有一次没有更新,也不会影响整体的流程,大不了下次出队的时候多出队一个。
第二次出队多线程版2:
线程A和线程B同时执行poll()方法,假设线程A稍快
| 线程A | 线程B |
|---|---|
| A1. Node1.item为null | B1. Node1.item为null |
| A2. (q = p.next) != null | B2. (q = p.next) != null |
| A3. p != q | B3. p != q |
| A4. p = q,循环 | B4. p = q,循环 |
| A5. Node2.item不为null,尝试更新结点item,更新成功,item值为null | B5. |
| A6. 满足条件 p != h | B6. Node2.item为null |
| A7. 判断p结点(Node2)是否有后继结点 | B7. |
| A8. 将后继结点即Node3设置为HEAD | B8. |
| A9. 返回item | B9. (q = p.next) != null |
| A10. | B10. p == q |
| A11. | B11. 重新获取HEAD并执行遍历 |
这个例子主要表达了当A线程先修改了首结点,并将原来的首结点设置为自引用时,B线程在循环过程中会执行到一条语句(q = p.next),然后在下一个条件语句中进入continue restartFromHead,重新获取HEAD变量并遍历
总结
ConcurrentLinkedQueue主要内容都已经学习过了,其中分析的过程花费了一个早上,吃完饭回来坐下才有了一些思路。学习的难点主要还是在它不同于普通的队列,它的tail和head变量不会时刻指向头结点和尾结点,这也造就了代码的复杂性,否则如下所示即可:
public boolean offer(E item){
checkNotNull(item);
for(;;){
Node<T> node = new Node(item);
if(tail.casNext(null, node) && casTail(tail, node)){
return true;
}
}
}但是这样和上面的例子比起来,就有性能的差距,差距主要体现在CAS写竞争方面:
最悲观的角度,ConcurrentLinkedQueue的offer方法需要执行两次 CAS (假设不发生竞争,其实我觉得不会有CAS竞争发生),上面的通用代码方法也需要执行两次,这里持平。
最乐观的角度,ConcurrentLinkedQueue只需要执行一次CAS,上面的通用方法仍需要两次。
原本是参考《Java并发编程的艺术》,但是里面的实现和现在不同了,所以根据现在的实际情况写了一份。当然,里面的主线思路仍然没有发生改变——尽量减少CAS操作。书上的代码是通过hops变量来控制多久需要更新一次值,大致思路如下所示:
遍历前,hops = 0
HEAD---
|
Node1 -> Node2 -> Node3 -> Node4
|
TAIL---假设现在要插入Node5,就要从TAIL变量位置(Node1位置)开始往后遍历,总共要循环三次才能找到最后一个尾结点,此时计数器hops就等于3,当Node5插入成功后,判断hops的值是否达到阈值,如果达到了,就更新tail变量;反之则不更新,直接返回。
遍历完后,hops = 3,达到阈值(假设达到了),将tail变量更新给Node5
HEAD---
|
Node1 -> Node2 -> Node3 -> Node4 -> Node5
|
TAIL---ConcurrentLinkedQueue初看以为很简单,其实逻辑还是挺复杂的,拓展了对队列的看法。今天在写这篇博客时,感觉一头雾水,因为CAS操作不像锁那样简单,代码块锁住就能放心执行,CAS只对单个操作保证可见性和原子性,很担心后面的线程会对其进行什么修改,今天过后总结了一下写并发容器的思路:
- 在了解某个方法的实现时,需要分清局部变量和共享变量,在理清了局部变量的含义后,将重点放在共享变量上
- 如果方法里某个语句没看懂(一头雾水型,突然就来了这么一句),请往多线程方向思考。
- 多对方法进行多线程分析(有助于理清思路),用md表格的例子写出来,很清晰,如果感觉md表格难以阅读,可以看这个网站 MD表格生成器