2.1经验误差与过拟合
我们实际希望的,是在新样本上能表现的很好的学习器。为了达到这个目的,应该从样本中尽可能学出适用于所有潜在样本的"普遍规律",这样才能在遇到新样本时作出正确的判断。
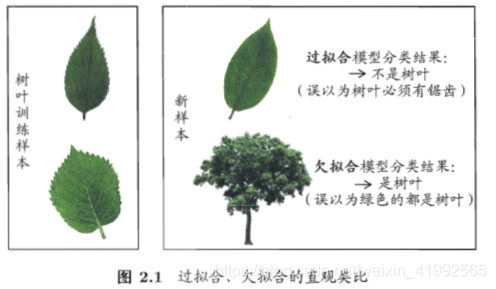
导致过拟合的因素:学习能力过于强大,把训练样本所包含的不太一般的特性学到了。
导致欠拟合的因素:学习能力低下
2.2评估方法
测试集应该尽可能与训练集互斥, 即测试样本尽量不在训练集中出现。
2.2.1 留出法
比较简单且常用,下面是划分训练集和测试集的sklearn的包
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(x,y,test_size=0.2)
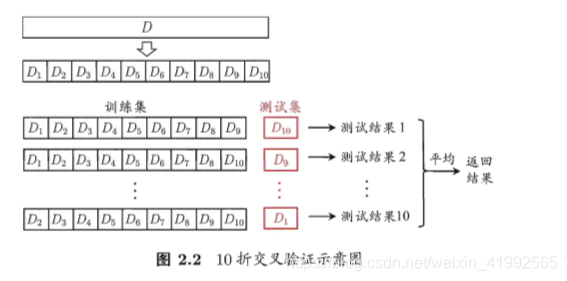
2.2.2 交叉验证法
2.2.3 自助法
现在有数据集D,其中有m个样本。采用m次有放回随机抽样。得到新的数据集D`。样本在m次采样中始终不被采到的概率是 取极限= 约等于0.368
于是就可以用D`作为训练集,没被采样到的数据作为测试集。这种方法适合数据集小,难以有效划分训练集和测试集的情况。
2.2.4 调参与最终模型
模型训练完后,应该把训练数据和测试数据整合从新训练模型,这个模型使用所有样本,这才是最终提交给用户的模型。
2.3.1 错误率与精度
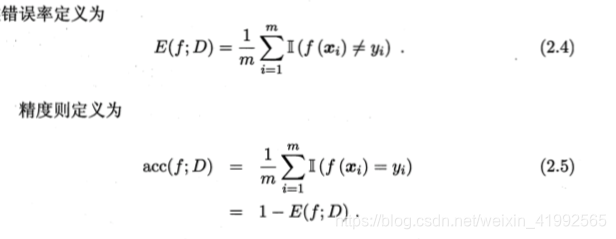
2.3.2 查准率、查全率与F1
查准率也叫"准确率",查全率也叫"召回率"

评估模型 “平衡点”(Break-Event Point,简称BEP),它是查准率=查全率时的取值,但是BEP还是过于简化了些,更常用的时F1度量:
书上未提的内容:任何一个阀值对应的点都会有一个F值,选取最大的F值为该分类器的F_score


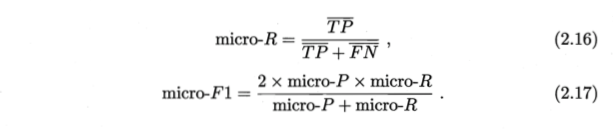
2.3.3 ROC与AUC
真正率和假正率:

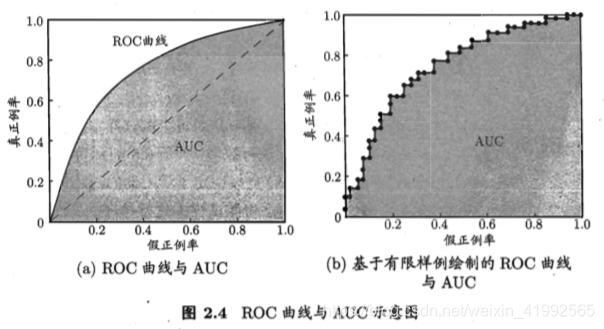
在分类算法比赛中也通常用AUC作为衡量分数(roc
曲线下的面积)
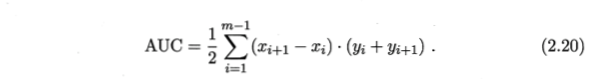
2.4.1 假设检验
通过推导得到泛化错误率e在学习器被测得错误率为e^得概率公式:
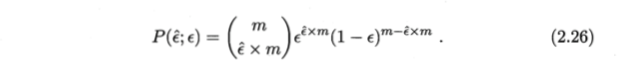
假设检验中的假设是对学习器泛化错误率分布的某种判断或猜想
若测试错误率小于临界值,即能够以1-α的置信度认为,学习器的泛化错误率不大于ε0,否则拒绝假设。
2.4.2 交叉验证t检验
通过t检验来多次重复留出法
这里更多得是统计知识,如果没有太多基础得话推荐看一下白话统计这本书