GIT
1.什么是git?
Git是目前世界上最先进的分布式版本控制系统。可以有效、高速地处理从很小到非常大的项目版本管理。 Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。Torvalds 开始着手开发 Git 是为了作为一种过渡方案来替代 BitK
2.git和svn的区别
其实在我们的日常学习或者工作中我们也用过和git类似的仓库,比如svn,那么我们节说一下这两者的区别
- SVN是集中式版本控制系统,版本库是集中放在中央服务器的,而干活的时候,用的都是自己的电脑,所以首先要从中央服务器哪里得到最新的版本, 然后干活,干完后,需要把自己做完的活推送到中央服务器。集中式版本控制系统是必须联网才能工作,如果在局域网还可以,带宽够大,速度够快,如果在互联网 下,如果网速慢的话,就纳闷了。
- Git是分布式版本控制系统,那么它就没有中央服务器的,每个人的电脑就是一个完整的版本库,这样,工作的时候就不需要联网了,因为版本都是在 自己的电脑上。既然每个人的电脑都有一个完整的版本库,那多个人如何协作呢?比如说自己在电脑上改了文件A,其他人也在电脑上改了文件A,这时,你们两之 间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
分布式相比于集中式的最大区别在于开发者可以提交到本地,每个开发者通过克隆(git clone),在本地机器上拷贝一个完整的Git仓库
3.什么是版本控制系统:
- 版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统
4.什么是分布式版本控制系统:
- 分布式版本控制系统(Distributed Version Control System,简称 DVCS), 在这类系统中,像 Git、Mercurial、Bazaar 以及 Darcs 等,客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。
5.git的功能特性
- 从服务器上克隆数据库(包括代码和版本信息)到单机上
- 在自己的机器上创建分支,修改代码
- 在单机上自己创建的分支上提交代码
- 在单机上合并分支
- 新建一个分支,把服务器上最新版的代码fetch下来,然后跟自己的主分支合并
- 生成补丁(patch),把自己的补丁发送给主开发者
- 看主开发者的反馈,如果主开发者发现两个一般开发者之间有冲突(他们之间可以合作解决的冲突),就会要求他们先解决冲突,然后由其中一个人提交。如果主开发者可以自己解决,或者没有冲突,就通过
- 一般开发者之间解决冲突的方法,开发者之间可以使用pull命令解决冲突,解决完冲突之后再向主开发者提交补丁
Git本地仓库的搭建与使用
1.安装git
[root@server1 ~]# yum install -y git
2.创建我们的本地仓库,并且初始化
[root@server1 ~]# mkdir demo #这里创建的版本库的名字为demo
[root@server1 ~]# cd demo/
[root@server1 demo]# ls -a
. ..
[root@server1 demo]# git init #进行初始化,需要在版本库目录中(这里的版本库目录为demo
Initialized empty Git repository in /root/demo/.git/
[root@server1 demo]# l.
. .. .git
[root@server1 demo]# ls .git/
branches config description HEAD hooks info objects refs
可以发现当前目录下多了一个.git的目录,这个目录是Git来管理版本库的,一般不要手动修改这个.git目录里面的文件。
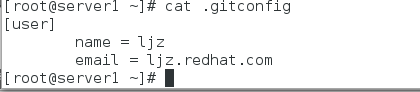
3.添加用户信息
初始化完后,接下来就要设置用户名和邮件地址,每次Git提交都会附带上这些信息,其实这些信息可以说时仓库所有者的标签,也可以说是联系人信息
[root@server1 demo]# git config --global user.name ljz
[root@server1 demo]# git config --global user.email ljz.redhat.com
查看用户名和邮箱
4.创佳文件,查看仓库文件状态
[root@server1 demo]# touch file1
[root@server1 demo]# echo redhat > file1
[root@server1 demo]# git status
# On branch master
#
# Initial commit
#
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# file1
nothing added to commit but untracked files present (use "git add" to track)
[root@server1 demo]# git status -s
?? file1 ##新添加的未跟踪的文件前面有??标志
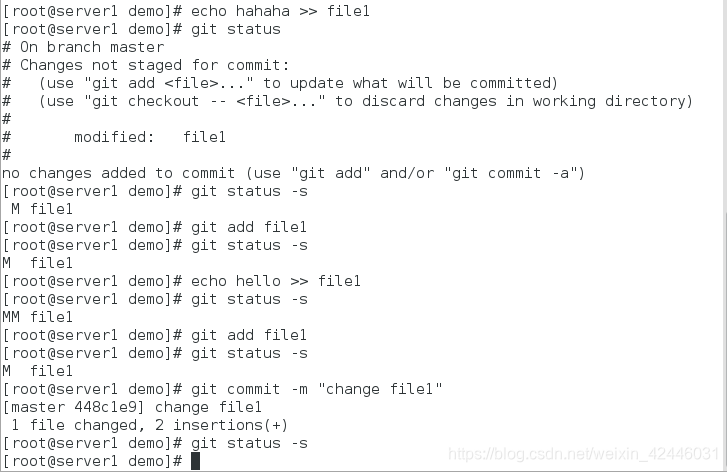
5.添加文件,也就是把文件放到暂存区
[root@server1 demo]# git add file1
[root@server1 demo]# git status
# On branch master
#
# Initial commit
#
# Changes to be committed:
# (use "git rm --cached <file>..." to unstage)
#
# new file: file1
#
[root@server1 demo]# git status -s
A file1 ##A表示已经添加到暂存区了
6.提交更改,实际上就是把暂存区的所有内容提交到当前分支
[root@server1 demo]# git commit -m "add file1"
[master (root-commit) 6be0829] add file1
1 file changed, 1 insertion(+)
create mode 100644 file1
[root@server1 demo]# git status -s 提交完后我们就会发现状态栏就没有文件了
7.git status的状态显示分类
- 新添加的未跟踪文件前面有 ?? 标记,
- 新添加到暂存区中的文件前面有 A 标记,
- 修改过的文件前面有 M 标记。
- 出现在右边的 M 表示该文件被修改了但是还没放入暂存区,
- 出现在靠左边的 M 表示该文件被修改了并放入了暂存区。
- MM表示工作区被修改并提交到暂存区后又在工作区中被修改了,所以在暂存区和工作区都有该文件被修改了的记录
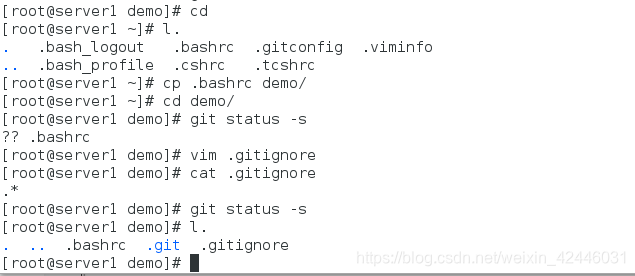
8.忽略文件
一般我们总会有些文件无需纳入 Git 的管理,也不希望它们总出现在未跟踪文件列表。 通常都是些自动生成的文件,比如日志文件,或者编译过程中创建的临时文件等。 在这种情况下,我们可以创建一个名为 .gitignore 的文件,列出要忽略的文件模式。
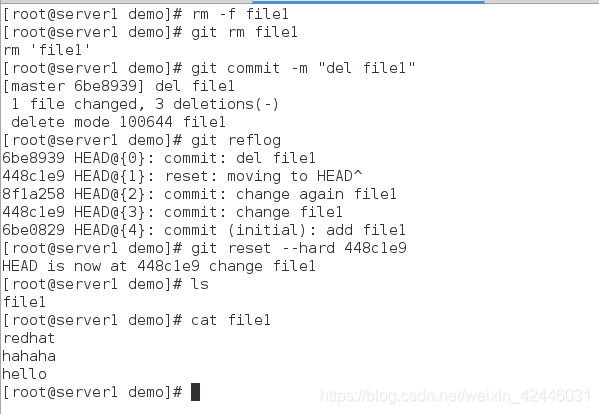
9.版本回退
像这样,你不断对文件进行修改,然后不断提交修改到版本库里,Git也是一样,每当你觉得文件修改到一定程度的时候,就可以“保存一个快照”,这个快照在Git中被称为commit。一旦你把文件改乱了,或者误删了文件,还可以从最近的一个commit恢复,然后继续工作,而不是把几个月的工作成果全部丢失。
(1) git checkout – file
-
以丢弃工作区的修改,就是让这个文件回到最近一次git commit或git add时的状态
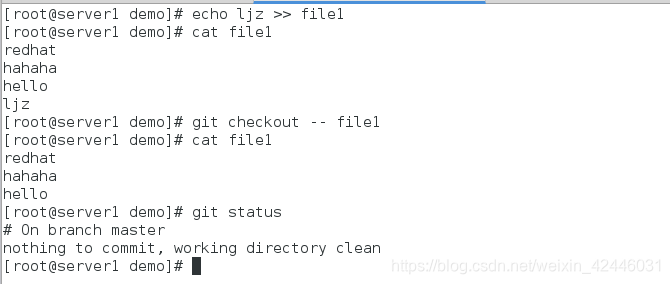
其实这些都可以通过状态的查看找到相应的命令
(2) git log命令显示从最近到最远的提交日志

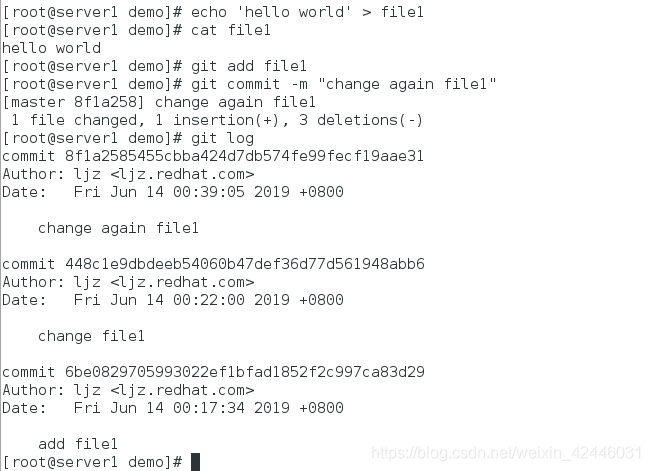
(3)git log --pretty=oneline查看简略日志信息

(4) git reflog查看历史记录

(5) git reset --hard HEAD^
- 上一个提交状态就是HEAD,上上一个提交状态就是HEAD^
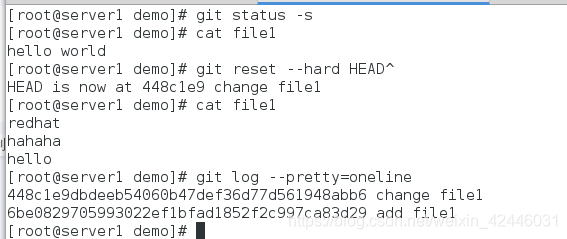
(5) git reset --hard … 回退到指定状态

10.删除后恢复
- 删除后没有提交,直接:git checkout – file即可
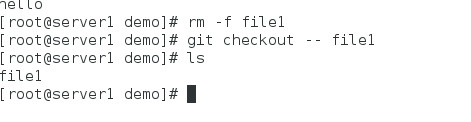
- 删除且提交后: git reset --hard 指定状态