Hadoop2.X开源软件及生态系统的最新发展综合分析
一、Hadoop版本概述
目前Hadoop的发行版除了Apache的开源版本之外,还有华为发行版、Intel发行版、Cloudera发行版(CDH)、Hortonworks发行版(HDP)、MapR等,所有这些发行版均是基于Apache Hadoop衍生出来的,因为Apache Hadoop的开源协议允许任何人对其进行修改并作为开源或者商业产品发布。国内大多数公司发行版是收费的,比如Intel发行版、华为发行版等。不收费的Hadoop版本主要有国外的四个,分别是Apache基金会hadoop、Cloudera版本(CDH)、Hortonworks版本(HDP)、MapR版本。
二、Hadoop2.x基本原理与架构
Apache Hadoop 是一个开源软件框架,可安装在一个商用机器集群中,使机器可彼此通信并协同工作,以高度分布式的方式共同存储和处理大量数据。最初,Hadoop 包含以下两个主要组件:Hadoop Distributed File System (HDFS) 和一个分布式计算引擎,该引擎支持以 MapReduce 作业的形式实现和运行程序。Hadoop2.x相比较于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了很大的提高,Hadoop2中有两个重要的变更:
(1)HDFS的NameNode可以以集群的方式布署,增强了NameNode的水平扩展能力和高可用性,分别是:HDFS Federation与HA;
(2)MapReduce将Job Tracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的组件,并更名为YARN(Yet Another Resource Negotiator)。

图1 Hadoop2.x架构图
2.1 HDFS
2.1.1 HDFS概述
HDFS仍然采用master/slave模式。主控节点仍然是NameNode,从节点仍然是多个DataNode。NameNode记录数据集的元数据。由于每个大文件load到HDFS时,都会被分割成默认64MB的数据块(Block),且这些数据块被分散到多个DataNode中做并行处理,因此NameNode需要管理一个文件分成了哪些Block,这些Block又分散在哪些DataNode上。这些映射关系就是元数据。当DataNode上的Block发生变化时,需向NameNode报告更新元数据。客户端操作数据时,需向NameNode查询元数据,在查询到数据所在的DataNode后,直接与DataNode交互,执行读/写操作。不同的数据块Block会有多个副本(主要是为了数据安全)。Rack是机架,一份数据的多个副本可能存在不同机架的服务器上。
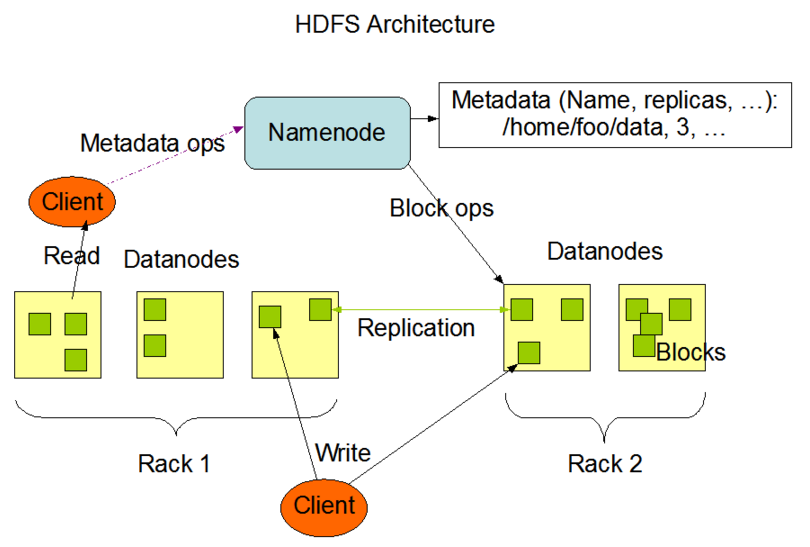
图2 HDFS架构图
2.1.2 HA
Hadoop2.x中HDFS的HA主要指的是可以同时启动2个NameNode。在2.0中增加了stand-by NameNode(SNN),而主节点称为active NameNode(ANN),其中一个处于工作(Active)状态,另一个处于随时待命(Standby)状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。ANN和SNN共享第三方存储,是热备方案,可自动failover。如图3所示,它展示了一个在Hadoop2下实现HA的一种方式结构:

图3 Hadoop下实现HA的架构图
2.1.3 HDFS Federation
1)全新的Federation架构
HA解决了单节点失败的问题,但是NameNode的扩展性差的问题仍然没有解决。 NameNode联盟工作方式如下:将多个DataNode存储的Block的元数据分成多个Block Pool(并非是一对一的关系),而一个NameNode可以管理多个Block Pool。由此每个NameNode管理一部分元数据,且相互独立,不需要任何协调工作。架构图如图4所示:

图4 HDFS Federation架构图
2.2 YARN
2.2.1 YARN基本架构
YARN 并不是下一代MapReduce(MRv2),下一代MapReduce与第一代MapReduce(MRv1)在编程接口、数据处理引擎(MapTask和ReduceTask)是完全一样的, 可认为MRv2重用了MRv1的这些模块,不同的是资源管理和作业管理系统,MRv1中资源管理和作业管理均是由Job Tracker实现的,集两个功能于一身,而在MRv2中,将这两部分分开了。 其中,作业管理由ApplicationMaster实现,而资源管理由新增系统YARN完成,由于YARN具有通用性,因此YARN也可以作为其他计算框架的资源管理系统,不仅限于MapReduce,也是其他计算框架(例如Spark)的管理平台。

图5 Hadoop2.x局部架构图
从图5中可以看出,Hadoop2中的MapReduce则是专门处理数据分析,而YARN则做为资源管理器而存在。YARN本质上是一个分布式资源管理与调度系统。它包括唯一的资源管理器(Resource Manager) 、每个作业一个的应用管理器(Application Master)、每个机器一个的节点管理器(Node Manager)。
该架构将JobTracker中的资源管理及任务生命周期管理(包括定时触发及监控),拆分成两个独立的服务,用于管理全部资源的ResourceManager以及管理每个应用的ApplicationMaster,ResourceManager用于管理向应用程序分配计算资源,每个ApplicationMaster用于管理应用程序、调度以及协调。一个应用程序可以是经典的MapReduce架构中的一个单独的Job任务,也可以是这些任务的一个DAG(有向无环图)任务。ResourceManager及每台机上的NodeManager服务,用于管理那台主机的用户进程,形成计算架构。每个应用程序的ApplicationMaster实际上是一个框架具体库,并负责从ResourceManager中协调资源及与NodeManager(s)协作执行并监控任务。如图6所示:

图6 YARN架构图
在 YARN 架构中,一个全局 ResourceManager 以主要后台进程的形式运行,它通常在专用机器上运行,在各种竞争的应用程序之间仲裁可用的集群资源。ResourceManager 会追踪集群中有多少可用的活动节点和资源,协调用户提交的哪些应用程序应该在何时获取这些资源。ResourceManager 是惟一拥有此信息的进程,所以它可通过某种共享的、安全的、多租户的方式制定分配(或者调度)决策(例如,依据应用程序优先级、队列容量、ACLs、数据位置等)。
在用户提交一个应用程序时,一个称为 ApplicationMaster 的轻量型进程实例会启动来协调应用程序内的所有任务的执行。这包括监视任务,重新启动失败的任务,推测性地运行缓慢的任务,以及计算应用程序计数器值的总和。这些职责以前分配给所有作业的单个 JobTracker。ApplicationMaster 和属于它的应用程序的任务,在受 NodeManager 控制的资源容器中运行。
NodeManager 是 TaskTracker 的一种更加普通和高效的版本。没有固定数量的 map 和 reduce slots,NodeManager 拥有许多动态创建的资源容器。容器的大小取决于它所包含的资源量,比如内存、CPU、磁盘和网络 IO。目前,仅支持内存和 CPU (YARN-3)。未来可使用 cgroups 来控制磁盘和网络 IO。一个节点上的容器数量,由配置参数与专用于从属后台进程和操作系统的资源以外的节点资源总量(比如总 CPU 数和总内存)共同决定。
2.2.2 YARN应用程序提交过程
当键入 hadoop jar 命令,将应用程序提交到 ResourceManager。ResourceManager 维护在集群上运行的应用程序列表,以及每个活动的 NodeManager 上的可用资源列表。ResourceManager 需要确定哪个应用程序接下来应该获得一部分集群资源。该决策受到许多限制,比如队列容量、ACL 和公平性。ResourceManager 使用一个可插拔的 Scheduler。Scheduler 仅执行调度;它管理谁在何时获取集群资源(以容器的形式),但不会对应用程序内的任务执行任何监视,所以它不会尝试重新启动失败的任务。
在 ResourceManager 接受一个新应用程序提交时,Scheduler 制定的第一个决策是选择将用来运行 ApplicationMaster 的容器。在 ApplicationMaster 启动后,它将负责此应用程序的整个生命周期。首先也是最重要的是,它将资源请求发送到 ResourceManager,请求运行应用程序的任务所需的容器。资源请求是对一些容器的请求,用以满足一些资源需求。
三、Hadoop商业发行版的对比分析
Hadoop 是一个开源项目,先后有许多公司在其框架基础上进行了增强并且发布了商业版本。Hadoop项目的最大诱惑在于使用者可以根据自身的业务需要定制差异化的功能。在Apache开源社区,Hadoop把所有的相关项目组成一个完整的生态系统,用户几乎不费吹灰之力就可以通过搭配一些组件来实现一个完整功能。Hadoop商业发行版的提供者们通过优化核心代码、增强易用性、提供技术支持和持续版本升级为Hadoop平台实现了许多新功能。市场上受认可的Hadoop商业发行版的提供者主要有Cloudera(CDH),MapR和Hortonworks。
总体来看,Hadoop商业版的区别如下表所示:
| 版本 |
优点 |
缺点 |
| CDH |
CDH有一个友好的用户界面及一些实用的工具,比如:Impala |
CDH相对MapR Hadoop来说,运行效率显著降低 |
| MapR Hadoop |
运行效率高;节点之间可以通过NFS直接访问 |
MapR Hadoop没有像CDH那样的用户界面 |
| HDP |
唯一一个能运行在Windows上的Haoop系统 |
Ambari管控界面功能比较简单,不够丰富 |
表1 商业版比较
3.1 Cloudera
Cloudera 是Hadoop领域知名的公司和市场领导者,提供了市场上第一个Hadoop商业发行版本。它拥有350多个客户并且活跃于Hadoop生态系统开源社区。在多个创新工具的贡献着排行榜中,它都名列榜首。它的系统管控平台——Cloudera Manager,易于使用、界面清晰,拥有丰富的信息内容。Cloudera 专属的集群管控套件能自动化安装部署集群并且提供了许多有用的功能,比如:实时显示节点个数,缩短部署时间等。同时,Cloudera 也提供咨询服务来解决各类机构关于在数据管理方案中如何使用Hadoop技术以及开源社区有哪些新内容等疑虑。美国电商“高朋”公司是CDH的用户。
3.2 MapR
MapR的Hadoop商业发行版紧盯市场需求,能更快反应市场需要。一些行业巨头如思科、埃森哲、波音、谷歌、亚马逊都是MapR的Hadoop的用户。与Cloudera和Hortonworks不同的是, MapR Hadoop不依赖于Linux文件系统,也不依赖于HDFS,而是在MapRFS文件系统上把元数据保存在计算节点,快速进行数据的存储和处理。其架构图如下所示:
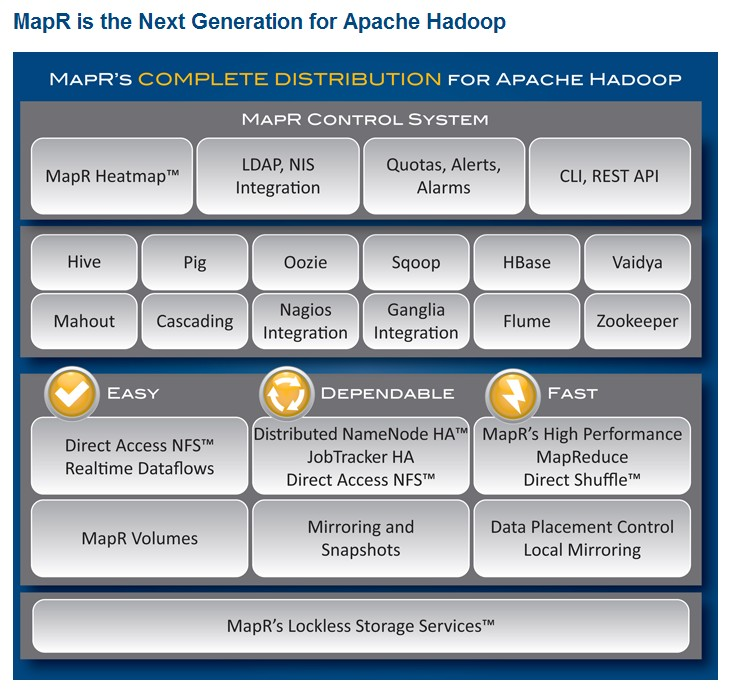
图7 MapR架构图
3.3 Hortonworks
Hortonworks是由一些雅虎的工程师创立的公司,提供针对Hadoop的技术服务。与其它公司不同的是,它提供完全开源的Hadoop数据平台并且用户可以免费使用。用户可以很方便得下载Hortonworks 的Hadoop发行版HDP并把它集成到各种应用中。Ebay、三星、彭博、Spotify 都是HDP的用户。Hortonworks 也是第一个基于Hadoop 2.0提供满足生产环境需要的Hadoop版本。尽管CDH在其早期的版本中包含了Hadoop 2.0的部分功能,但这些功能无法满足生产环境需要。HDP 也是目前唯一能支持Windows的Hadoop版本。用户可以在Azure 上通过HDInsight 服务部署Windows上的 Hadoop。
四、Hadoop的技术应用
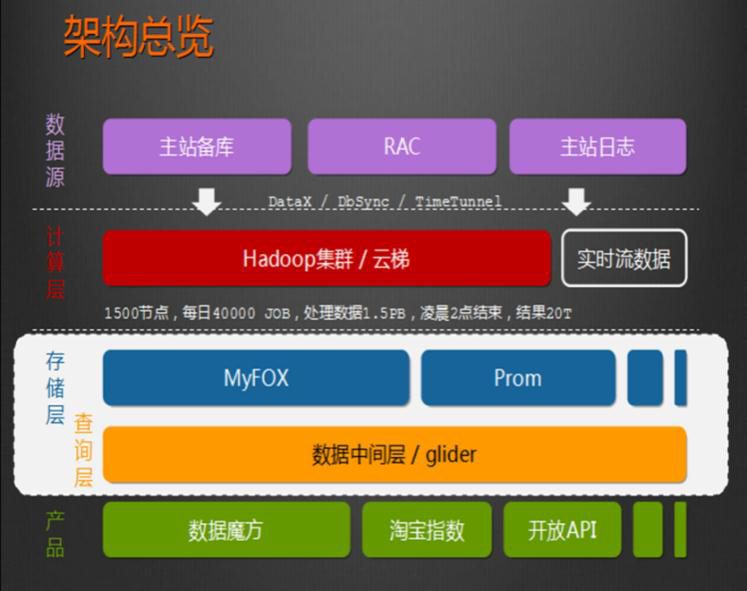
4.1 Hadoop应用于数据服务基础平台建设
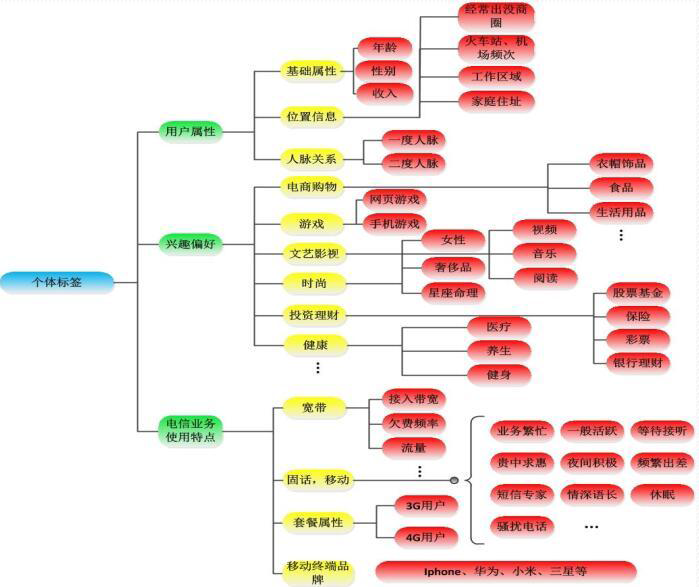
4.2 Hadoop用于用户画像
4.3 Hadoop用于网站点击流日志数据挖掘