原文地址:https://arxiv.org/pdf/1603.01360.pdf
摘要
命名实体识别的最先进系统严重地依赖手工生产特征和特定领域的知识,以便有效地从现有的小型、有监督的训练语料库中学习。 本文介绍了基于双向LSTMS和条件随机场的两种新的神经结构,另一种是使用基于转换的方法构造和标记片段,这种方法是受Shift-Reducer解析器启发的。我们的模型依赖于关于单词的两个信息来源:基于字符的词表示从监督语料库中学习,而非监督词表示从无标注语料库中学习。 我们的模型获得最先进的表现,以NER四种语言,而不求助于任何特定语言的知识或资源,如地名录。
1、引言
命名实体识别 是一项极具挑战的学习问题。一方面,在大多数语言和领域,只有很少的监督训练数据可用。另一方面,对可以命名的字的种类有很少的限制,所以从这个小的数据样本中概括起来是很困难的。因此,精心构建的字形特征和特定语言的知识资源,如地名录,被广泛用于解决这一任务。不幸的是,在新的语言和新领域中,语言的资源和功能是昂贵的,使NER适应不同情况的挑战。为不加标注的语料库进行无监督学习提供了一种替代策略,可以从少量的监督中获得更好的泛化能力。然而,即使是大量依赖无监督特性的系统也使用这些特性来扩充而不是取代手工设计的特性和专门的知识库。(例如关于特定语言中的资本化模式和字符类的知识)
在本文中,我们提出了新的神经结构,它不使用特定于语言的资源或特征,只使用少量有监督的训练数据和未标记的语料库。我们的模型是为了捕捉两种直觉而设计的。首先,由于名称通常由多个标记组成,因此对每个标记联合使用标签决定 是很重要的。
在这里,我们比较了两个模型:(I)双向LSTM,它上面有一个顺序的条件随机层(LSTM-CRF;§2);(Ii)一种新的模型,它使用一种基于转换的解析算法构造和标记输入句子块,其状态由堆栈Lstms表示(s-LSTM;§3)。 第二,“是否是一个名字”的令牌级证据包括正交证据(词被标记为名称的是什么?))和分布证据(标记词在语料库中的位置?)。 为了捕获正交灵敏度,我们使用基于字符的词表示模型(ling等人,2015b)来捕获分布灵敏度,我们将这些表示与分布表示相结合(mikolov等人,2013b)。我们的词表示法将这两者结合在一起,而dropout训练被用来鼓励模型学会信任这两种证据来源(第4节)。
用英语、荷兰语、德语和西班牙语进行的实验表明,我们能够以荷兰、德国和西班牙语的lstm-crf模式获得最新的ner性能,并且非常接近英语的最新水平,而无需任何手工设计的功能或地名录(第5节)。基于转换的算法同样优于以前在几种语言中发表的最佳结果,尽管它的性能不如LSTM-CRF模型。
2、LSTM-CRF模型
2.1、LSTM
递归神经网络(Rnns)是一类对序列数据进行操作的神经网络。它们以向量序列(x1,x2...xn)作为输入,并返回另一个序列(h1,h2,...hn)表示输入中每一步的序列的一些信息。尽管Rnns理论上可以学习长期依赖关系,但在实践中它们却没有这样做,而且倾向于偏向于它们在序列中的最新输入(Bengio等人,1994年)。长短期记忆网络(Lstms)已经被设计成通过包含内存单元来解决这个问题,并且已经被证明能够捕获长期依赖关系。他们使用几个门来控制输入给记忆细胞的比例,以及从先前状态到遗忘的比例(Hochreiter和Schmidhuber,1997)。我们用一下公式进行描述:
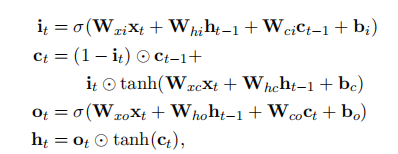
其中σ是按元素方向的Sigmoid函数,以及是元素的乘积。对于给定的句子(x1,x2,。。。,xn)包含n个单词,每个单词表示为d维向量,LSTM在每个单词t处计算句子左上下文的表示ht。当然,生成正确上下文ht的表示也应该添加有用的信息。 这可以通过使用第二个LSTM来实现,第二个LSTM以相反的方式读取相同的序列。我们将前者称为前向LSTM,后者称为后向LSTM。这是两个不同的网络,具有不同的参数。 这种前后向LSTM对称为双向LSTM。
使用该模型表示一个单词的方法是将它的左右上下文表示连接起来,![]() 这些表示有效地包括了上下文中单词的表示,这对于许多标记应用程序都很有用。
这些表示有效地包括了上下文中单词的表示,这对于许多标记应用程序都很有用。
2.2、CRF标记模型
一个非常简单但却非常有效的标签模型是使用ht作为特性,为每个输出yt做出独立的标记决策。 尽管该模型在pos标签等简单问题上取得了成功,但当输出标签之间存在很强的依赖关系时,它的独立分类决策将受到限制。NER就是一个这样的任务,因为特征标签间序列的“语法”强加了几个难以用独立假设建模的硬约束。因此,我们没有独立地建模标记决策,而是使用条件随机场对它们进行了联合建模(Laffdy等人,2001年)。输入句子 :

![]()
我们认为p是双向LSTM网络输出的分数矩阵。p的大小为n×k,其中k是不同标记的数目,pij对应于句子中第i个单词的第j个标记的分数。对于预测序列:
![]()
我们把它的分数定义为 :

其中A是转换分数的矩阵,使得Aij表示从标记i到标签j的转换的分数。y0和yn是句子的开始和结束标记,我们将其添加到一组可能的标记中。因此,a是k+2大小的方阵。在所有可能的标记序列上,Softmax会产生序列y的概率:
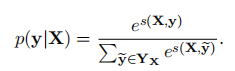
在训练期间,我们最大限度地提高正确标记序列的对数似然:
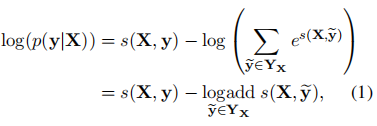
其中,Yx表示一个句子X的所有可能的标记序列(甚至那些不验证IOB格式的标记序列)。从上面的表述来看,很明显,我们鼓励我们的网络产生一个有效的输出标签序列。 在解码过程中,我们预测输出序列,该输出序列获得以下所给出的最大分数:
![]() (2)
(2)
因为我们只是在模拟输出之间的两个词的交互作用,所以都是在等式中求和。(1)是最大后验序列y*。(2)采用动态规划方法进行计算。
2.3、参数化与训练
与每个标记决策相关的分数(即pi,y‘s)被定义为由双向LSTM计算的Wordin上下文嵌入之间的点积,与ling等人的pos标记模型完全相同。(2015B)与Bigram兼容性分数(即Y0,Y0)相结合。这个体系结构如图1所示。圆代表观察变量,菱形是其父母的确定性函数,双圆是随机变量。

图1:网络的主要架构。给出了双向LSTM的字嵌入。Li代表I和它的左上下文,ri代表I和它的右上下文。将这两个向量连接在一起,就可以在其上下文Ci中表示单词I。
因此,该模型的参数是Bigram兼容性评分矩阵A,以及产生矩阵P的参数,即双向LSTM的参数、线性特征权重和单词嵌入。与第2.2部分一样,让xi表示一个句子中每个单词的嵌入顺序,而yi是它们的关联标记。我们将在第4节中讨论如何创建词嵌入xi。单词嵌入序列作为双向LSTM的输入,该LSTM返回每个单词的左和右上下文的表示,如2.1中所解释的那样。
这些表示被连在一起(Ci)并线性投影到一个大小等于不同标签数量的层上。我们没有使用这个层的Softmax输出,而是像前面描述的那样使用CRF来考虑相邻的标记,为每个单词yi做出最终的预测。此外,我们还观察到在ci和CRF层之间添加一个隐藏层可以稍微改进我们的结果。这个模型所报告的所有结果都包含了这个额外的层。对参数进行训练,使方程(1)达到最大,在标注语料库中观察到的NER标记序列,给出观察到的单词。
2.4、标记方案
命名实体识别的任务是为句子中的每个单词指定一个命名实体标签。 一个命名实体可以在一个句子中跨越多个标记。句子通常以IOB格式(内部、外部、开始)表示,如果令牌是命名实体的开始,则标记为b标签;如果标记在命名实体内,则为i标签,而不是命名实体内的第一个标记,否则为O。然而,我们决定使用iobes标记方案,这是IOB的一个常见的用于命名实体识别的变体,它编码关于单个实体的信息,并显式地标记命名实体(E)的结束。使用此方案,当I-标签带有高度自信地标记一个单词时,将缩小对后续单词I标签或E标签的选择,然而,IOB计划只能确定后续单词不能是另一个标签的内部。Ratinov和roth(2009)、Dai等人(2015)显示,使用更有表现力的标记方案(如iobes)可以略微提高模型性能。然而,我们并没有观察到与IOB标记方案相比有显著的改善。
3 基于过渡的分块模型
作为上一节讨论的LSTM-CRF的替代方案,我们探索了一种新的体系结构,它使用类似于基于转换的依赖分析的算法来标记输入序列。该模型直接构造多标记名称的表示(例如,名称标记Watney由单个表示组成)。该模型依赖于堆栈数据结构来增量地构造输入块。为了获得用于预测后续行为的堆栈表示,我们使用Dyer等人提出的堆栈-LSTM。(2015),其中LSTM增加了一个“堆栈指针”。当顺序lstms模型序列从左到右时,堆栈lstms允许嵌入添加到(使用推送操作)和从(使用POP操作)中删除的对象堆栈。这允许堆栈-LSTM像维护其内容的“概要嵌入”的堆栈一样工作。 为了简单起见,我们将这个模型称为堆栈LSTM或s-LSTM模型。
最后,我们请感兴趣的读者参考原始论文(dyer等人,2015),以获得关于stacklstm模型的详细信息,因为在本文中,我们只是通过下面一节介绍的一种新的基于转换的算法来使用相同的体系结构。
3.1、分块算法
我们设计了一个转换清单,如图2所示,它受到基于转换的解析器的启发,特别是Nivre(2004)的弧形标准解析器。在该算法中,我们使用两个堆栈(指定输出和堆栈分别表示已完成的块和划痕空间)和一个包含尚未处理的单词的缓冲区。 过渡清单包含以下过渡:Shift转换将一个单词从缓冲区移动到堆栈,Out转换将一个单词从缓冲区直接移动到输出堆栈中,而REDUCE(Y)转换从堆栈顶部弹出所有项,创建一个“块”,用标签y标记这个项,并将该块的表示推到输出堆栈上。当堆栈和缓冲区都为空时,算法将完成。该算法如图2所示,它显示了处理所访问的Mars的语句标记Watney所需的操作序列。
给定堆栈、缓冲区和输出的当前内容以及所执行操作的历史,通过在每个时间步骤定义对动作的概率分布来参数化模型。跟踪Dyer等人。(2015),我们使用堆栈lstms计算其中每一个的固定维嵌入,并对这些嵌入进行级联以获得完整的算法状态。此表示用于定义可在每个时间步骤执行的可能操作的分布。该模型通过训练使给定输入句子的参考动作序列(从标记训练语料库中提取)的条件概率最大化。为了在测试时间标记一个新的输入序列,贪婪地选择最大概率动作,直到算法达到终止状态。虽然这并不一定能找到一个全局最优方案,但在实践中是有效的。由于每个标记要么直接移动到输出(1操作),要么首先移动到堆栈,然后输出(2个操作),所以长度n的序列的动作总数最大为2n。

图2:堆栈-LSTM模型的转换,指示应用的操作和结果状态。粗体符号表示单词和关系的嵌入,脚本符号表示对应的单词和关系。
0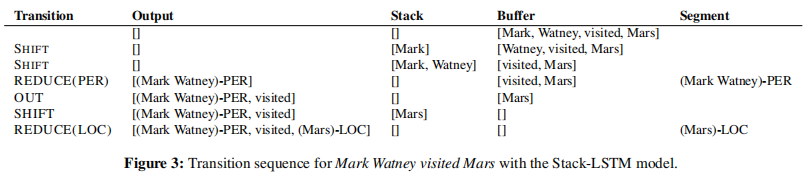
图3:MarkWatney使用堆栈-LSTM模型访问mars的转换序列。 值得注意的是,该算法模型的性质使得它不知道所使用的标记方案,因为它可以直接预测标记块。
3.2、表示标记块
在执行REDUCE(Y)操作时,该算法将标记序列(连同它们的向量嵌入)从堆栈转移到输出缓冲区,作为一个完整的块。为了计算这个序列的嵌入,我们在其组成标记的嵌入上运行一个双向LSTM,同时运行一个表示所标识的块类型的标记(i.e,y)。此函数设为g(u,v,ry),其中ry是标记类型的学习嵌入。因此,输出缓冲区包含单个向量表示,用于生成的每个标记块,而不管其长度如何。
4、输入字嵌入
两个模型的输入层都是单个单词的矢量表示。从有限的NER训练数据中学习单词类型的独立表示是一个困难的问题:有太多的参数无法可靠地估计。由于许多语言都有拼写或形态学证据证明某物是一个名称(或不是一个名称),我们需要对单词拼写敏感的表示。因此,我们使用一个模型,该模型根据由(4.1)组成的字符的表示来构造单词的表示。我们的第二个直觉是,名称,可能是个别的,相当多的变化,出现在大语料库的规则上下文中。因此,我们使用从大语料库中学习到的对语序敏感的嵌入(4.2)。最后,为了防止模型对一种或另一种表现形式的依赖性过强,我们使用了dropout训练,发现这对于良好的泛化性能至关重要(4.3)。

图4:单词“mars”的字符嵌入给双向lstm。我们将它们的最后输出连接到一个查找表的嵌入中,以获得这个词的表示。
4.1、基于字符的词语模型
我们的工作与以往大多数方法的一个重要区别是,我们学习字符级的特征,同时训练,而不是手工工程前缀和后缀信息的单词。学习字符级嵌入具有学习表示特定于当前任务和领域的优点。它们对于形态丰富的语言和处理诸如词性标注和语言建模(ling等人,2015b)或依赖分析(Ballesteros等人,2015年)等任务的词汇外问题很有用。 图4描述了从其字符中为一个单词生成一个单词嵌入的体系结构。随机初始化的字符查找表包含每个字符的嵌入。对应于一个词中每个字符的字符嵌入是以正反向顺序给出的,给出了Foward和反向LSTM。 由字符派生的词的嵌入是双向LSTM的前向和后向表示的级联。 然后,这个字符级表示与单词查找表中的字级表示连接起来. 在测试过程中,在查找表中没有嵌入的单词被映射到事件嵌入。为了训练事件嵌入,我们用概率为0.5的事件嵌入替换了单个节点。在我们所有的实验中,正向和后向字符lstm的隐维分别为25,这导致了我们基于字符的单词表示为50维。 因此,我们期望前向LSTM的最终表示能够准确地表示单词的后缀,而反向LSTM的最终状态将更好地表示它的前缀。另一种方法-尤其是卷积网络-已被提议用来从文字中学习单词的表征(Zhang等人,2015年;Kim等人,2015年)。 然而,convnets的设计是为了发现它们的输入的位置不变特征。我们认为重要的信息是位置依赖的(例如前缀和后缀编码的信息与词干不同),这使得lstms成为一个更优先的函数类,用于建模单词与它们的字符之间的关系。
4.2、预训练嵌入
科洛伯特等人。(2011),我们使用预先训练过的字嵌入来初始化查找表。我们观察到使用预先训练过的字嵌入比随机初始化的有显著的改进。嵌入是使用Skip-n-gram(ling等人,2015A)预先训练的,后者是Word2vec(mikolov等人,2013年a)的一个变体,解释了词序。这些嵌入在训练期间进行了精细的调整。
西班牙语、荷兰语、德语和英语的单词嵌入分别使用西班牙gigaword第3版、Leipzig语料库、2010年机器翻译讲习班的德语单语培训数据和英语gigaword第4版(删除la Times和NY Time部分)进行训练。我们使用的嵌入维数为100,其他语言为64,最小词频截止为4,窗口大小为8。
4.3、Dropout training
初步实验表明,字符级嵌入与预先训练的字表示结合使用,并没有提高我们的整体性能。为了鼓励模型依赖于这两种表示,我们使用了辍学培训(Hinton等人,2012年),在图1中的双向LSTM输入之前将一个辍学掩码应用到最终的嵌入层。我们观察到在使用dropout后,我们的模型的性能有了显著的改善(见表5)。
5、Experiments
这一部分介绍了我们用来训练我们的模型的方法,我们在各种任务上得到的结果,以及我们的网络配置对模型性能的影响。
5.1、Training
对于这两种模型,我们使用反向传播算法训练我们的网络,在每个训练示例中每次更新我们的参数,使用随机梯度下降(SGD),学习速率为0.01,梯度剪裁为5.0。为提高SGD的绩效,提出了几种方法,例如,addelta(Zeiler,2012年)或Adam(Kingma和ba,2014年)。虽然我们使用这些方法观察到更快的收敛性,但没有一种方法的性能比采用梯度裁剪的SGD更好。
我们的LSTM-CRF模型使用一个单层的正向和后向lstm,其尺寸设置为100。调优此维度对模型性能没有显著影响。我们把辍学率定为0.5。使用较高的比率会对我们的结果产生负面影响,而较小的比率会导致更长的训练时间。
堆栈-LSTM模型为每个堆栈使用两个维度各为100的层.组合函数中使用的动作的嵌入分别有16维,输出嵌入为20维。我们对不同的辍学率进行了实验,并报告了每种语言采用最佳辍学率的分数。3这是一个贪婪的模型,在整个句子被处理之前应用局部最优动作,通过波束搜索(Zhang and Clark,2011)或探索训练(Ballesteros等人,2016)可以得到进一步的改进。
5.2、 Data Sets
我们在不同的数据集上测试我们的模型以进行命名实体识别。为了证明我们的模型具有推广到不同语言的能力,我们介绍了conll-2002和conll-2003数据集(Tjong Kim SUN,2002;Tjong Kim SUN和de Meulder,2003)的结果,其中包含英语、西班牙语、德语和荷兰语的独立命名实体标签。所有数据集都包含四种不同类型的命名实体:位置、人员、组织和杂项实体,这些实体不属于上述三个类别中的任何一个。虽然pos标记可以用于所有数据集,但我们没有将它们包括在我们的模型中。除了用英文NER数据集中的零替换每一个数字之外,我们没有执行任何数据集预处理。
5.3 Results
表1给出了我们与其他英文命名实体识别模型的比较。 为了使我们的模型与其他模型之间的比较公平,我们报告了其他模型的分数,包括是否使用了外部标记数据,如地名录和知识库。我们的模型不使用地名录或任何外部标记的资源。关于这一任务的最佳成绩是罗等人所报道的。(2015年)。他们通过联合建模NOR和实体链接任务获得了91.2的F1(Hoffart等人,2011年)。他们的模型使用了很多手工设计的功能,包括拼写功能、Wordnet集群、棕色集群、pos标记、块标记,以及词干和外部知识库(如FreeBase和Wikipedia)。我们的LSTM-CRF模型优于所有其他系统,包括使用外部标记数据(如地名录)的系统。除了Chiu和Nichols(2015)介绍的模型外,我们的stacklstm模型还优于以前所有不包含外部特性的模型。
表2、表3和表4分别列出了德国、荷兰和西班牙与其他模型的比较结果。在这三种语言上,LSTM-CRF模型的性能明显优于以前的所有方法,包括使用外部标记数据的方法。唯一的例外是荷兰,在荷兰,Gillick等人的模型。(2015年)可以通过利用来自其他可再生能源技术数据集的信息来更好地发挥作用。与不使用外部数据的系统相比,堆栈LSTM还始终呈现最新(或接近)结果。
从表中可以看出,堆栈-lstm模型更依赖于基于字符的表示来实现竞争性能;我们假设lstm-crf模型需要较少的正交信息,因为它从双向lstms中获取更多的上下文信息;然而,堆栈-lstm模型一个接一个地消耗单词,并且它只是在分词时依赖于单词表示。
5.4网络架构
我们的模型有几个组件,我们可以调整以了解它们对整体性能的影响。 我们探讨了CRF、字符级表示、单词嵌入预训练和退出对我们的lstmcrf模型的影响。 我们观察到,预先训练我们的词嵌入给了我们最大的改善,在总体表现为7.31在F1。CRF层增加了1.79,而使用辍学导致了1.17的差异,最终学习字符级的词嵌入增加了0.74左右。对于堆栈LSTM,我们进行了类似的实验。表5给出了不同结构的结果。
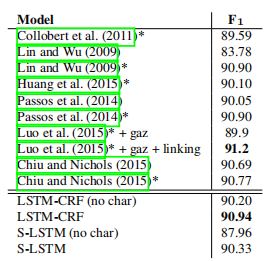
表1:英语NER测试结果(conll-2003测试集)。*指示使用外部标记数据进行培训的模型

表2:德国NER测试结果(conll-2003测试集)。*指示使用外部标记数据进行培训的模型

表5:使用不同配置的英语NER模型的结果。“预训练”指的是包含预先训练过的单词嵌入的模型,“char”是指包括基于字符的词建模的模型,“下拉”指的是包含辍学率的模型。
6相关工作
在conll-2002共享任务中,carrera等人。(2002)在荷兰和西班牙都取得了最好的结果之一,通过合并几个小的固定深度决策树。明年,在conll-2003共享任务中,弗洛里安等人。(2003)通过综合四个不同分类器的输出,在德语上获得了最好的分数。齐等人(2009)后来,通过对大规模的无标记语料库进行无监督学习,神经网络对此进行了改进。以前已经提出了几种新的神经结构。例如,Colobert等人。(2011)使用CNN对一系列字嵌入,在顶部有一个CRF层。这可以被认为是我们的第一个模型,没有字符级嵌入和双向LSTM被一个CNN取代。最近,Huang等人。(2015年)提出了一个类似于我们的LSTM-CRF的模型,但使用手工拼写功能。周和徐(2015)也使用了类似的模型,并将其适用于语义角色标注任务。Lin和Wu(2009)使用线性链CRF和L2正则化,他们加入了从网络数据和拼写特征中提取的短语聚类特征。Passos等人(2014年)还使用了具有拼写特征和地名录的线性链通用报告格式。Cucerzan和Yarowsky(1999;2002)提出了半监督的自举算法,通过共同训练字符级(字-内)和标记级(上下文)特征来识别命名实体。Eisenstein等人(2011)在几乎没有监督的情况下,使用贝叶斯非参数化技术构建命名实体的数据库。Rateinov和Roth(2009)定量比较了几种方法,并利用正则化平均感知器和聚合上下文信息建立了自己的监督模型。最后,目前人们对使用基于字母的表示法的NER模型很感兴趣.Gillick等人(2015)将顺序标注的任务建模为序列学习问题的序列,并将基于字符的表示纳入其编码器模型。Chiu和Nichols(2015)采用了一种与我们类似的体系结构,但使用CNN学习字符级的特性,其方式类似于Santos和Guimaraes(2015)的工作。
7 Conclusion
本文提出了两种用于序列标注的神经结构,即使与使用外部资源的模型(如地名录)进行比较,也提供了标准评估设置中所报告的最好的NER结果。我们的模型的一个关键方面是,它们通过简单的crf体系结构建模输出标签依赖关系,或者使用基于转换的算法显式地构造和标记输入块。词表示法也是成功的关键:我们使用预先训练过的词表示和捕捉形态和拼写信息的“基于字符”的表示。为了防止学习者过分依赖一个表示类,使用了辍学。