2019年密码与安全新技术讲座-课程总结报告
课程讲座总结
网络(web)安全与内容安全
信息化的发展使得信息安全越发重要。在网络中由于存在威胁方-防护方技术、成本、风险、主题的非对称性,维护信息安全的难度非常之高,没有哪一个系统敢说自己是绝对安全的,但起码应该对常见的威胁做出应对,避免系统被很容易的攻破。
目前WEB应用中存在很多漏洞,常见的WEB漏洞如下:
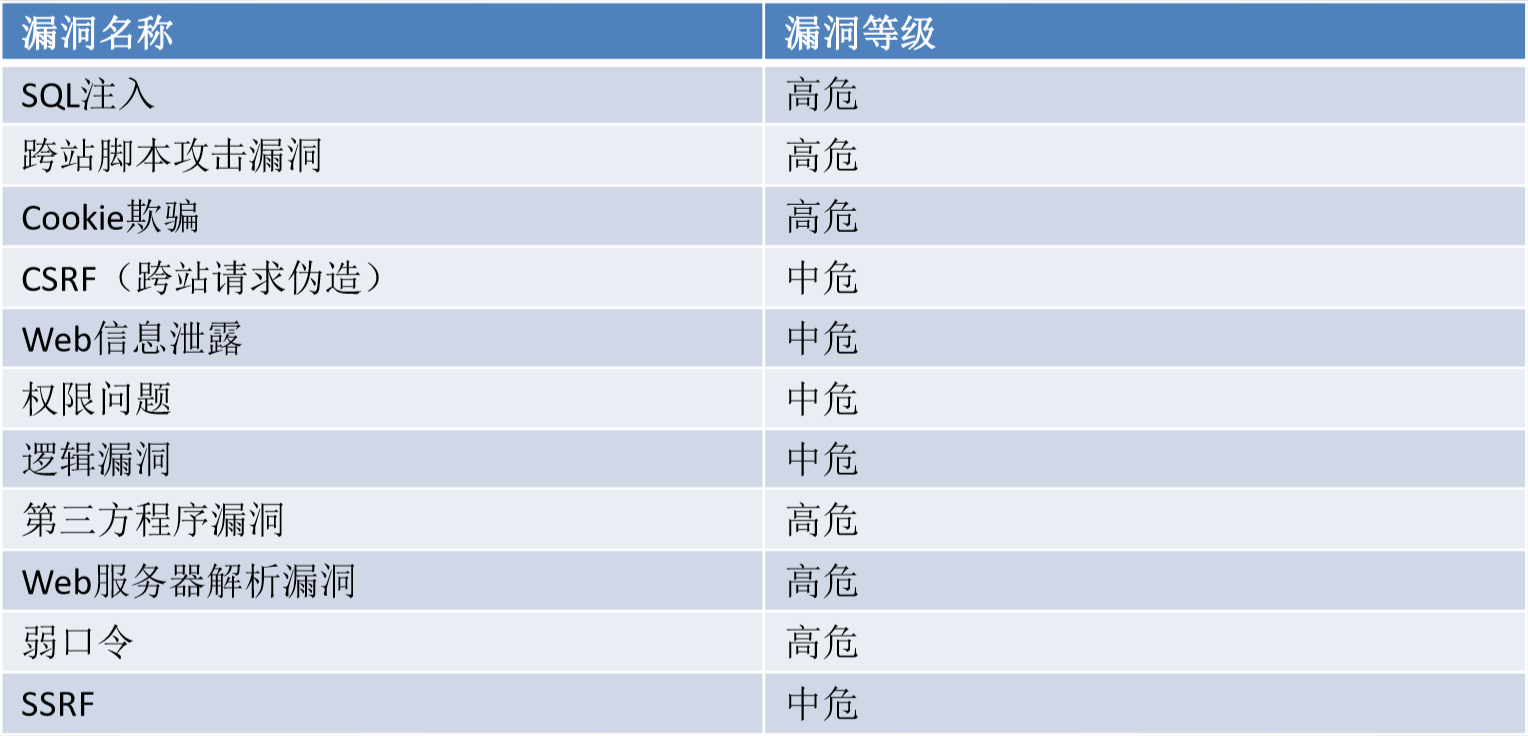
SQL注入攻击
不管用什么语言编写的Web应用,它们都用一个共同点,具有交互性并且多数是数据库驱动。在网络中,数据库驱动的Web应用随处可见,由此而存在的SQL注入是影响企业运营且最具破坏性的漏洞之一。
SQL注入攻击是通过将恶意的 Sql 查询或添加语句插入到应用的输入参数中,再在后台 Sql 服务器上解析执行进行的攻击。
黑客们能通过SQL注入进行攻击基于一种SQL语言的技术基础——构造动态字符串。这种技术可以概括为以下几点:
- SQL命令可查询、插入、更新、删除等,命令的串接。而以分号字符为不同命令的区别。(原本的作用是用于SubQuery或作为查询、插入、更新、删除……等的条件式)
- SQL命令对于传入的字符串参数是用单引号字符所包起来。(但连续2个单引号字符,在SQL数据库中,则视为字符串中的一个单引号字符)
- SQL命令中,可以注入注解(连续2个减号字符 -- 后的文字为注解,或“/”与“/”所包起来的文字为注解)
- 因此,如果在组合SQL的命令字符串时,未针对单引号字符作转义处理的话,将导致该字符变量在填入命令字符串时,被恶意窜改原本的SQL语法的作用。
具体来说,在应用程序中若有下列状况,则可能应用程序正暴露在SQL Injection的高风险情况下:
- 在应用程序中使用字符串联结方式或联合查询方式组合SQL指令。
- 在应用程序链接数据库时使用权限过大的账户(例如很多开发人员都喜欢用最高权限的系统管理员账户(如常见的root,sa等)连接数据库)。
- 在数据库中开放了不必要但权力过大的功能(例如在Microsoft SQL Server数据库中的xp_cmdshell延伸存储程序或是OLE Automation存储程序等)
- 太过于信任用户所输入的数据,未限制输入的特殊字符,以及未对用户输入的数据做潜在指令的检查。
SQL注入攻击可通过以下措施预防:
- 在设计应用程序时,完全使用参数化查询(Parameterized Query)来设计数据访问功能。
- 在组合SQL字符串时,先针对所传入的参数加入其他字符(将单引号字符前加上转义字符)。
- 如果使用PHP开发网页程序的话,需加入转义字符之功能(自动将所有的网页传入参数,将单引号字符前加上转义字符)。
- 使用php开发,可写入html特殊函数,可正确阻挡XSS攻击。
- 其他,使用其他更安全的方式连接SQL数据库。例如已修正过SQL注入问题的数据库连接组件,例如ASP.NET的SqlDataSource对象或是 LINQ to SQL。
- 使用SQL防注入系统。
- 增强WAF的防御力
XSS跨站脚本攻击
XSS攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。这些恶意网页程序通常是JavaScript,但实际上也可以包括Java,VBScript,ActiveX,Flash或者甚至是普通的HTML。攻击成功后,攻击者可能得到更高的权限(如执行一些操作)、私密网页内容、会话和cookie等各种内容。
通过XSS攻击,攻击者期待达到以下目的:
- 盗用cookie,获取敏感信息。
- 利用植入Flash,通过crossdomain权限设置进一步获取更高权限;或者利用Java等得到类似的操作。
- 利用iframe、frame、XMLHttpRequest或上述Flash等方式,以(被攻击)用户的身份执行一些管理动作,或执行一些一般的如发微博、加好友、发私信等操作。
- 利用可被攻击的域受到其他域信任的特点,以受信任来源的身份请求一些平时不允许的操作,如进行不当的投票活动。
- 在访问量极大的一些页面上的XSS可以攻击一些小型网站,实现DDoS攻击的效果。
避免XSS最根本的方法是关闭浏览器的Javascript选项,但这可能使一些网页无法正确执行,一般来说使用更新比较频繁的浏览器能获得更好的安全保证。从技术手段上来说,避免XSS攻击的方法主要是将用户所提供的内容进行过滤,许多语言都有提供对HTML的过滤:
- PHP的htmlentities()或是htmlspecialchars()。
- Python的cgi.escape()。
- ASP的Server.HTMLEncode()。
- ASP.NET的Server.HtmlEncode()或功能更强的Microsoft Anti-Cross Site Scripting Library
- Java的xssprotect (Open Source Library)。
- Node.js的node-validator。
CSRF跨站请求伪造
跨站请求伪造(英语:Cross-site request forgery),也被称为 one-click attack 或者 session riding,通常缩写为 CSRF 或者 XSRF, 是一种挟制用户在当前已登录的Web应用程序上执行非本意的操作的攻击方法。[1] 跟跨网站脚本(XSS)相比,XSS 利用的是用户对指定网站的信任,CSRF 利用的是网站对用户网页浏览器的信任。是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并运行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去运行。这利用了web中用户身份验证的一个漏洞:简单的身份验证只能保证请求发自某个用户的浏览器,却不能保证请求本身是用户自愿发出的。
伪基站诈骗
伪基站,又称假基站、假基地台,是一种利用GSM单向认证缺陷的非法无线电通信设备,主要由主机和笔记本电脑组成,能够搜取以其为中心、一定半径范围内的GSM移动电话信息,并任意冒用他人手机号码强行向用户手机发送诈骗、推销等垃圾短信,通常安放在汽车或者一个比较隐蔽的地方发送。伪基站运行时,用户手机信号被强制连接到该设备上,无法连接到公用电信网络,以影响手机用户的正常使用。
思考
张健毅老师的课生动简洁,为我们讲述了当前针对各种安全漏洞的攻击方式,更是结合不少实际的例子加深我们的认识。其中震网病毒和XCodeGhost给我很深的印象。如今我们使用的手机、电脑、各种工业设备,核心部分从源头上说都是国外掌握,像win10系统市场占有率早已超过50%,但我们对其核心代码一无所知,也很难对可能的安全漏洞进行测试和防护;像我们日常使用的编译器visual studio、XCode等也都不是开源,它们在编译中到底有没有做什么别的我们也无从得知。
尤其是我国许多机密要害部分,使用这些不明不白的产品难保不会有什么安全问题,核心技术还是掌握在自己手中才能放心,操作系统等的国产化还是尽快推进为上。
量子密码
量子与量子态
微观世界的某些物理量不能连续变化而只能取某些 分立值,相邻分立值的差称为该物理量的一个量子 。
在量子力学里,量子态(quantum state)指的是量子系统的状态。态矢量可以用来抽象地表示量子态。采用狄拉克标记,态矢量表示为右矢|?>;其中,在符号内部的?可以是任何符号,字母,数字,或单字。例如,在计算氢原子能谱时,能级与主量子数n有关,所以,每个量子态的态矢量可以表示为 |?>。
一般而言,量子态可以是纯态或混合态。上述案例是纯态。混合态是由很多纯态组成的概率混合。不同的组合可能会组成同样的混合态。当量子态是混合态时,可以用密度矩阵做数学描述,这密度矩阵实际给出的是概率,不是密度。纯态也可以用密度矩阵表示。
哥本哈根诠释以操作定义的方法对量子态做定义:量子态可以从一系列制备程序来辨认,即这程序所制成的量子系统拥有这量子态。例如,使用z-轴方向的施特恩-格拉赫实验仪器,可以将入射的银原子束,依照自旋的z-分量S_z分裂成两道,一道的S_z为上旋,量子态为|↑>或|Z+,另一道的S_z为下旋,量子态为|↓>或|Z->,这样,可以制备成量子态为|↑>的银原子束,或量子态为|↓>的银原子束。银原子自旋态矢量存在于二维希尔伯特空间。对于这纯态案例,相关的态矢量 |ψ= α|↑+ β|↓>是二维复值矢量 (α , β),长度为1。
在测量一个量子系统之前,量子理论通常只给出测量结果的概率分布,这概率分布的形式完全由量子态、相关的可观察量来决定。对于纯态或混合态,都可以从密度矩阵计算出这概率分布。
另外,还有很多种不同的量子力学诠释。根据实在论诠释,一个量子系统的量子态完整描述了这个量子系统。量子态囊括了所有关于这系统的描述。实证诠释阐明,量子态只与对于量子系统做观察所得到的实验数据有关。按照系综诠释,量子态代表一个系综的在同样状况下制备而成的量子系统,它不适用于单独量子系统。
量子态的可叠加性带来一系列特殊性质 :
- 量子计算的并行性,强大的计算能力。
- 测不准原理,未知量子态不可准确测量。
- 不可克隆定理,未知量子态不可克隆。
- 对未知量子态的测量可能会改变量子态。
量子态的测量
- 每个力学量都对应一个厄米算符(矩阵)
- 测量某个力学量时,测量结果为此力学量对应厄米 算符的本征值(特征值)
- 测量后量子态塌缩到此本征值对应的本征态(特征向量)
提高量子密码性能
- 提高效率:可重用基、纠缠增强、双光子、双探测器
- 提高抗干扰能力:无消相干子空间、量子纠错码
- 提高实际系统抗攻击能力:诱骗态、设备无关
感想
量子力学与相对论一起被称为现代物理学的两大支柱,可以解释微观系统内的物理现象,从我对量子力学的了解来看,量子力学堪称是为人类打开了新世界的大门。
就我个人对物理的兴趣来说,从大学之前的有点感兴趣,到大学因为种种原因的完全不感兴趣,再到现在对量子力学有初步了解后,到了非常感兴趣的程度。科学技术是第一生产力,科技的发展已经大幅改变了人类的生活。科技发展到今天,有可能对人类生活方式产生根本性影响的在我看来只有两点:一是对原子能的利用,二是对量子力学的研究与应用。 对量子力学的初步了解让我感到震惊,量子力学仿佛存在了无限的可能性。
基于深度学习的密码分析与设计初探
机器学习的分类
1.有监督学习
监督学习涉及一组标记数据。计算机可以使用特定的模式来识别每种标记类型的新样本。监督学习的两种主要类型是分类和回归。在分类中,机器被训练成将一个组划分为特定的类。
2.无监督学习
在无监督学习中,数据是无标签的。由于大多数真实世界的数据都没有标签,这些算法特别有用。无监督学习分为聚类和降维。聚类用于根据属性和行为对象进行分组。
3.强化学习
强化学习研究学习器在与环境的交互过程中,如何学习到一种行为策略,以最大化得到的累积奖赏。与前面我们提到的其它学习问题的不同在于,强化学习处在一个对学习器的行为进行执行和评判的环境中:环境将执行学习器的输出,发生变化,并且反馈给学习器一个奖赏值;同时学习器的目标并不在于最大化立即获得的奖赏,而是最大化长期累积的奖赏。
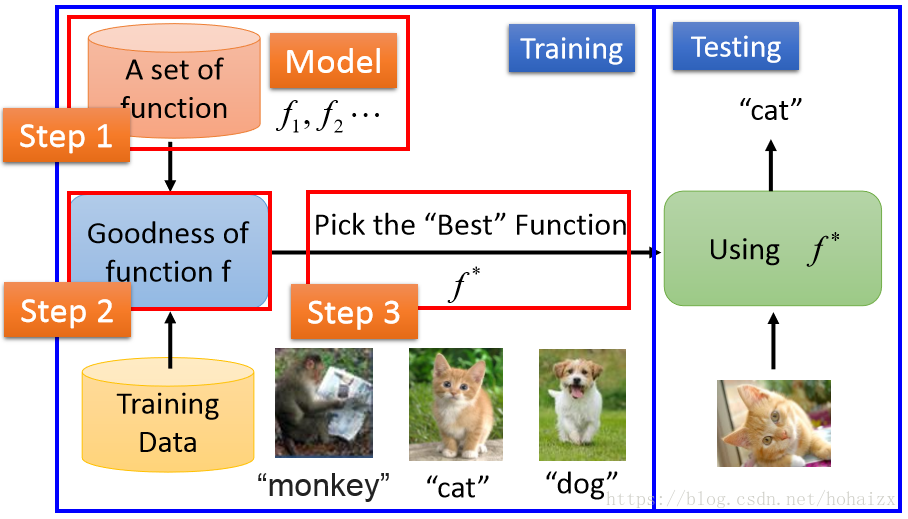
机器学习的步骤
- 选择一个合适的模型,这通常需要依据实际问题而定,针对不同的问题和任务需要选取恰当的模型,模型就是一组函数的集合。
- 判断一个函数的好坏,这需要确定一个衡量标准,也就是我们通常说的损失函数(Loss Function),损失函数的确定也需要依据具体问题而定,如回归问题一般采用欧式距离,分类问题一般采用交叉熵代价函数。
- 找出“最好”的函数,如何从众多函数中最快的找出“最好”的那一个,这一步是最大的难点,做到又快又准往往不是一件容易的事情。常用的方法有梯度下降算法,最小二乘法等和其他一些技巧(tricks)。
学习得到“最好”的函数后,需要在新样本上进行测试,只有在新样本上表现很好,才算是一个“好”的函数。
深度学习
深度学习的实质,是通过构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性。因此,“深度模型”是手段,“特征学习”是目的。区别于传统的浅层学习,深度学习的不同在于:1)强调了模型结构的深度,通常有5层、6层,甚至10多层的隐层节点;2)明确突出了特征学习的重要性,也就是说,通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,从而使分类或预测更加容易。与人工规则构造特征的方法相比,利用大数据来学习特征,更能够刻画数据的丰富内在信息。
<deep learning采用了神经网络相似的分层结构,系统由包括输入层、隐层(多层)、输出层组成的多层网络,只有相邻层节点之间有连接,同一层以及跨层节点之间相互无连接,每一层可以看作是一个logistic regression模型;这种分层结构,是比较接近人类大脑的结构的。

深度学习与密码分析
1.基于卷积神经网络的侧信道攻击:
- TemplateAttack
- MachineLearning
- DeepLearning
2.基于循环神经网络的明文破译:
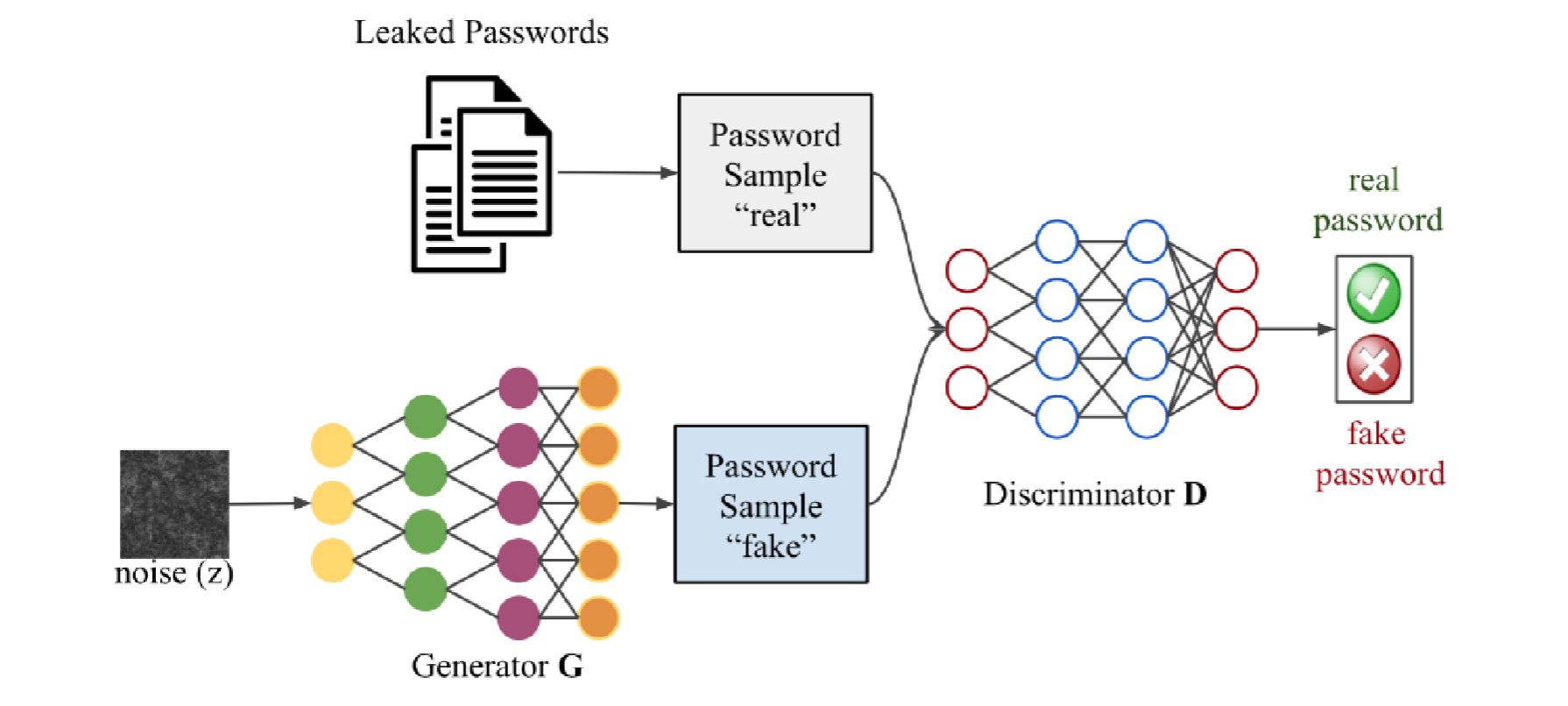
3.基于生成对抗网络的口令破解:
4.基于深度神经网络的密码基元识别:
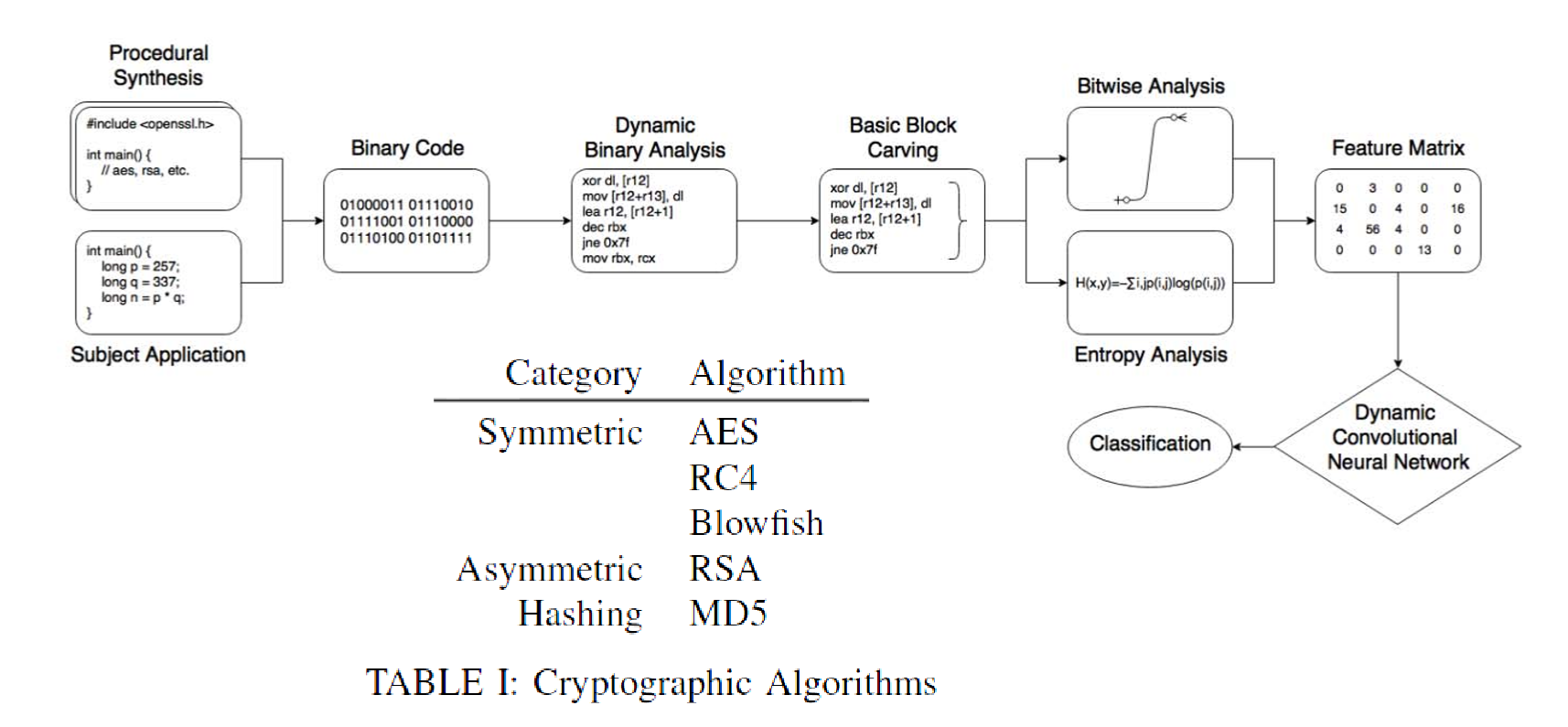
深度学习与密码设计
两大重点科学问题包括“组件化可变密码算法设计与安全性评估”和“密文可编程数据安全存储与计算”。因此未来对于新密码算法的设计需求将与日剧增,然而目前密码算法的设计还停留在人工设计阶段,较为耗时耗力,难以适应未来对密码算法设计的需求。
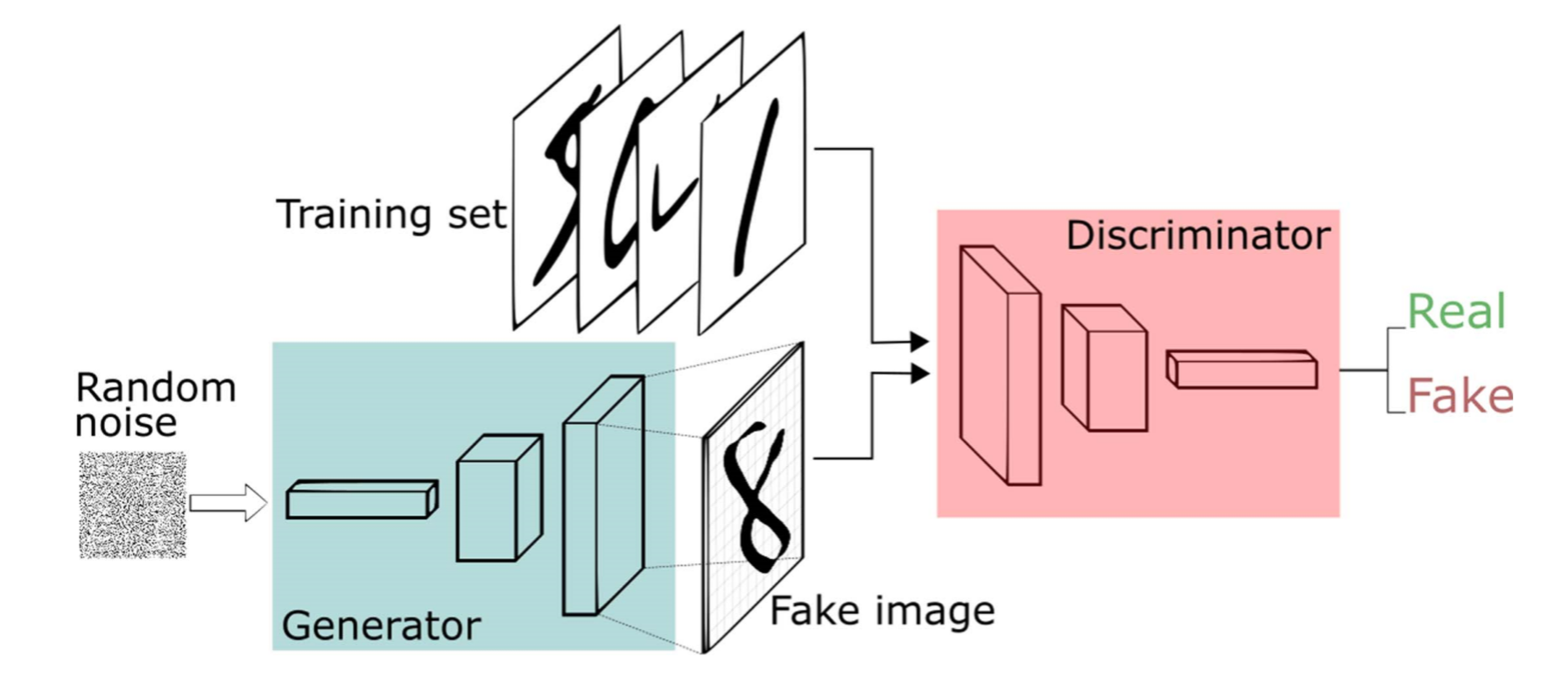
生成对抗网络GAN(Generative Adversarial Network):
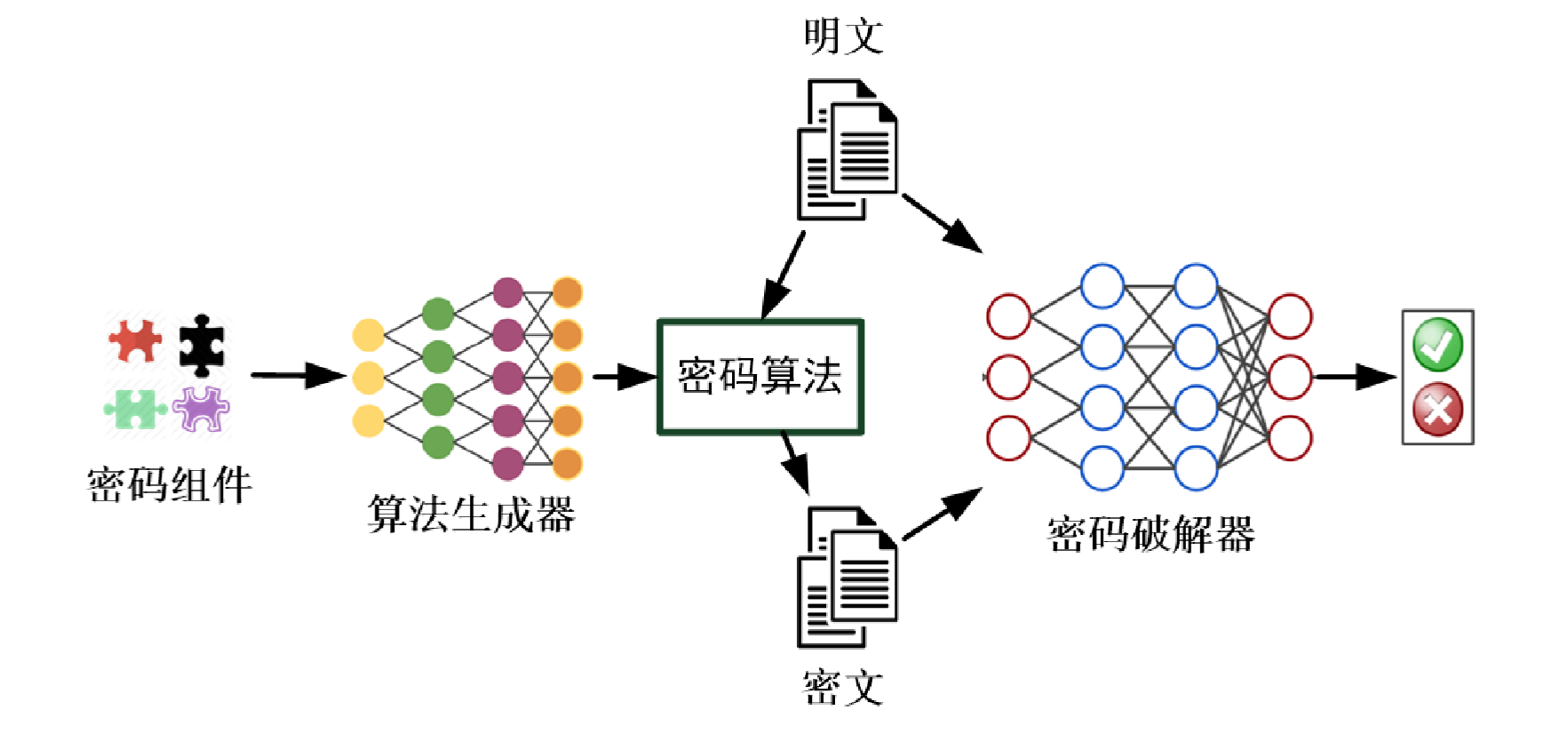
机器生成密码算法的思路:
感想
我们应该正确认识AI能够在当前取得的成就,才可以解决更加复杂的问题。我们不能忽略:对于自然语言理解,虽然经过了数十年的发展,依然没有人工智能系统可以做到完全正确地理解人类的语言(包括语音识别和机器翻译);在机器人领域,即使工业机器人发展迅速,我们依然没有看到具有常识和推理能力的智能家庭机器人;在计算机视觉领域,即使我们在人脸识别和图片分类上取得了不小的成就,但是对于关系理解和完整的场景认知,现在系统能做到的还很有限。
正如卡内基梅陇大学机器学习系Alex Smola教授认为:AI技术在未来确实有可能对流水线工人、卡车司机、保洁员等相对低技能要求的工种造成冲击,然而解决的办法只能是提高整个社会的教育水平。其次,我认为社会也在对人工智能技术的发展产生各种积极的约束:譬如,用户对于技术的安全性和稳定性的要求;用户对于数据隐私的要求;用户对于产品的道德约束。总而言之,当前是人工智能发展的一个令人兴奋的时期,机器学习技术对于整个人类的发展,也是具有不可估量的潜力。我们应该正视科学技术发展的进步,理性看待所取得的结果。
信息隐藏
信息隐藏是指将特定用途的消息隐蔽地藏于其他载体(Cover)中,使得它们难以被发现或者消除,通过可靠提取隐藏的信息,实现隐蔽通信、内容认证或内容保护功能。信息隐藏的技术手段主要包括水印、可视密码、隐写等。
鲁棒水印
鲁棒水印是重要的数字产权管理与安全标识技术之一, 指将与数字媒体版权或者购买者有关的信息嵌入数字 媒体中,使攻击者难以在载体不遭到显著破坏情况下 消除水印,而授权者可以通过检测水印实现对版权所 有者或者内容购买者等表示信息的认定。
相比于其他隐藏技术,鲁棒水印有以下两个特点:
- 对于覆盖信号所做的改变应该不会被人类的感官察觉到
- 即使随后改变了水印层,也应该可以恢复隐藏的信息
从根本上说,鲁棒水印是对应于所有信息隐藏技术的优势与稳健性与嵌入率权衡的不同折衷。早在1954年就有了早期的鲁棒水印,20世纪90年代,当娱乐业面临越来越多的盗版行为时,技术发展更为迅速。 鲁棒水印已被视为补充传统基于密码学的内容保护的候选技术。

可视密码
可视密码技术是Naor和Shamir于1994年首次提出的,其主要特点是恢复秘密图像时不需要任何复杂的密码学计算,而是以人的视觉即可将秘密图像辨别 出来。其做法是产生n张不具有任何意义的胶片,任取其中t张胶片叠合在一起即可还原出隐藏在其中的秘密信息。可视密码方案实际上是一种秘密共享方案,即使是一个具有无穷计算能力的攻击者,也不能在拥有的子秘密数量少于一个给定值时获得关于秘密图像的任何信息。

隐写
隐写是基于信息隐藏的隐蔽通信或者隐蔽存储方法,将秘密消息难以感知地隐藏在内容可公开的载体中,保护保密通信或者保密存储这些行为事实。
隐写的信息通常用一些传统的方法进行加密,然后用某种方法修改一个“伪装文本”(covertext),使其包含被加密过的消息,形成所谓的“隐秘文本”(stegotext)。例如,文字的大小、间距、字体,或者掩饰文本的其他特性可以被修改来包含隐藏的信息。只有接收者知道所使用的隐藏技术,才能够恢复信息,然后对其进行解密。
隐写包括多种方法,包括:
- 自适应隐写
- LSB嵌入
- 矩阵嵌入
隐写分析
隐写分析(steganalysis)是指在已知或未知嵌入算法的情况下,从观察到的数据检测判断其中是否存在秘密信息,分析数据量的大小和数据嵌入的位置,并最终破解嵌入内容的过程。
隐写分析的发展历程:
- Li Bin的“Auto-Encoder”,比RichModel还差14%-15% 。
- Qian系列:系统地提出了“GNCNN”,真正开创了CNN应用于Steganalysis,比RichModel差2%-3%。
- XuNet系列,第一层卷积层后用了Absolute(ABS)层以利用残差图像符号的对称性,激活函数选取上,部分层用tanh函数。
- NiJQ最新:YeNet,新结构。
- XuGuanShuo:Res on J-UNIWARD,新的网络结构,比featur-based method好一点(在low payload时不明显)。
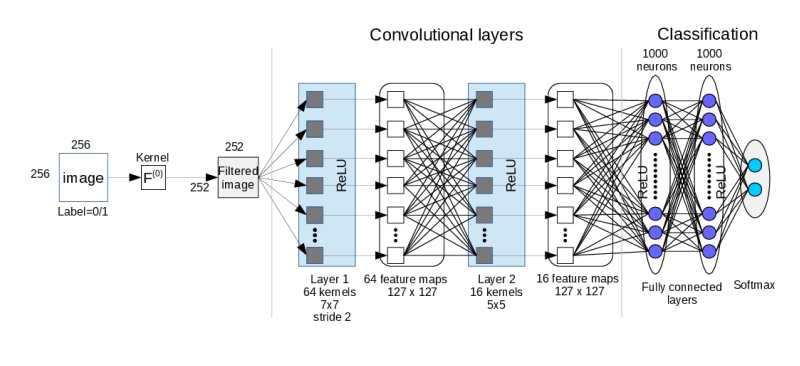
一般性的运用深度学习进行隐写分析的过程如下:
感想
信息隐藏这方面的内容在之前的学会或者生活中其实一直被我忽视了,但现在想想信息隐藏其实占有很重要的地位,有很大的发展空间和应用前景,首先就是版权保护方面,数字水印技术如果能得到有效发展和应用,对于版权法追权十分重要;当今互联网的发展状况无论是云存储还是各种新媒体的出现都位隐藏信息的传播提供了十分便捷的途径,这也为我们对有害隐藏信息的检测提出了更高的要求。更广义的信息隐藏,如之前出现过的植入xcode和易语言编译器的后门程序,如果不能被有效检测将带来很大的安全威胁,再比如我们从网上下载资料,会不会不知不觉就成为了病毒或者违法信息的传播者?
区块链
狭义来讲,区块链是一种按照时间顺序将数据区块以顺序相连的方式组合成的一种链式数据结构,并以密码学方式保证的不可篡改和不可伪造的分布式账本。
广义来讲,区块链技术是利用块链式数据结构来验证与存储数据、利用分布式节点共识算法来生成和更新数据、利用密码学的方式保证数据传输和访问的安全、利用由自动化脚本代码组成的智能合约来编程和操作数据的一种全新的分布式基础架构与计算方式。
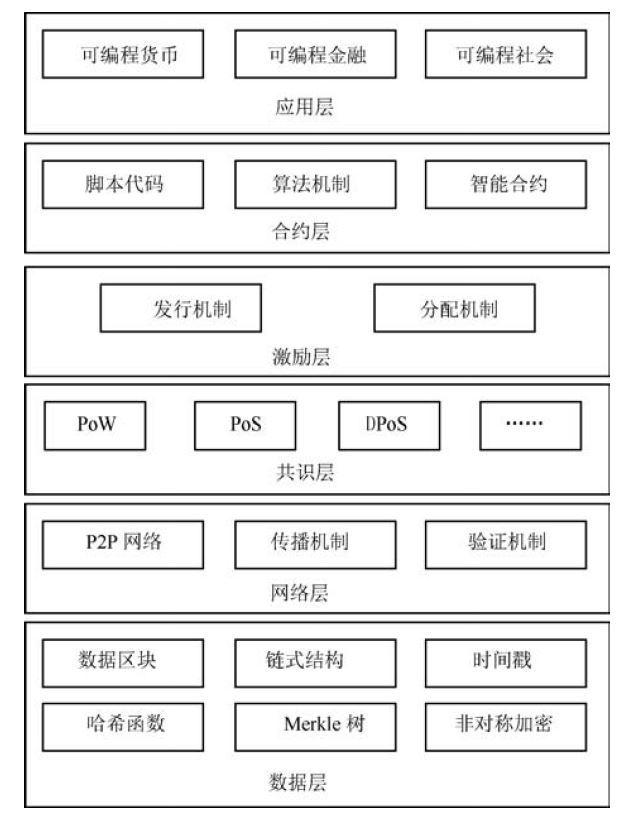
区块链架构模型
一般说来,区块链系统由数据层、网络层、共识层、激励层、合约层和应用层组成。 其中,数据层封装了底层数据区块以及相关的数据加密和时间戳等基础数据和基本算法;网络层则包括分布式组网机制、数据传播机制和数据验证机制等;共识层主要封装网络节点的各类共识算法;激励层将经济因素集成到区块链技术体系中来,主要包括经济激励的发行机制和分配机制等;合约层主要封装各类脚本、算法和智能合约,是区块链可编程特性的基础;应用层则封装了区块链的各种应用场景和案例。该模型中,基于时间戳的链式区块结构、分布式节点的共识机制、基于共识算力的经济激励和灵活可编程的智能合约是区块链技术最具代表性的创新点。
比特币
比特币也是区块链支付系统和虚拟计价工具,由于其采用密码技术来控制货币的生产和转移,而没有中央的发行机构,无法任意增发,交易在全球网络中运行,有特殊的隐秘性,加上不必经过第三方金融机构,因此得到越来越广泛的应用,也成了非法交易的介质。用户利用个人计算机和智能手机中的加密钱包软件,无需任何银行、信用卡、在线支付公司等中介机构,可随时随地在网络上直接交换物品、服务。 根据剑桥大学2017年的研究,全球有多达580万个加密钱包活跃用户,其中大多数使用比特币。同时,有观点认为,比特币技术得到了广泛的认可和使用,使人类迎来了区块链时代。
新增的数据块总能链接到上一个区块,即整条区块链的尾部。比特币点对点网络将所有的交易历史都存储在“区块链”(blockchain)中,所以区块链可以看作记录着比特币交易的账本。区块链是一群分散的客户端节点,并由所有参与者组成的分布式数据库,是对所有比特币交易历史的记录。中本聪预计,当数据量增大之后,用户端希望这些数据并不全部存储自己的节点中。为了实现这一目标,他采用引入散列函数机制。这样客户端将能够自动剔除掉那些自己永远用不到的部分,比方说极为早期的一些比特币交易记录。
感想
技术改变世界,绝不是一句空话。
编程作为一种技术,可以说是改变世界中成本最低的一种方式。
但技术永远是双刃剑,像区块链技术可以大大方便人们的生活,却也为不法分子的违法活动提供了方便。
作为技术的开发者或持有者,我们要坚守道德底线,帮助技术在对社会有益的方向发挥作用。
安全漏洞利用与挖掘
在计算机的所有设备中,硬件设备是最容易受到网络漏洞的攻击和破坏的,例如防火墙、路由器等。不同的设备所产生的漏洞类型有所不同,产生漏洞的原因也有较大的差异。计算机网络安全漏洞还有一个显著的特点,就是具有一定的时效性,从计算机开始运行起,网络中就会不断产生新的漏洞,因此在日常的使用过程中要不断更新补丁或对系统进行升级,只有这样才能有效的加强对漏洞的防范。与此同时,一些已经进行修补的漏洞有可能会发生新的变化,因此也需要引起注意。
安全漏洞分类
** 网络中的协议漏洞
就拿最我们应用最广泛的TCP/IP协议组来说吧,它是置于可信的环境之下设计的,只考虑到网络互连和开放性问题,而没有过多的考虑安全性。造成了TCP/IP协议组本身在应用方面并不安全,因此导致基于TCP/IP协议的一系列网络服务安全性及其脆弱。
应用软件系统的漏洞
任何一款软件由于设计上的缺陷都或多或少存在一定的漏洞,这种漏洞可以造成系统本身的脆弱。通常该漏洞分为两种:一是由于操作系统本身设计缺陷造成的安全漏洞,并影响到运行在该系统上的应用程序;二是应用程序本身设计漏洞。
配置不当引起的漏洞 **
由于安全策略设置的不完整,系统有时候会在安全策略未发挥作用的时候运行,而管理人员很难发现,直到系统出现问题才有所觉察。
漏洞挖掘技术
1.人工分析
人工分析是一种灰盒分析技术。针对被分析目标程序,手工构造特殊输入条件,观察输出、目标状态变化等,获得漏洞的分析技术。输入包括有效的和无效的输入,输出包括正常输出和非正常输出。非正常输出是漏洞出现的前提,或者就是目标程序的漏洞。非正常目标状态的变化也是发现漏洞的预兆,是深入挖掘的方向。人工分析高度依赖于分析人员的经验和技巧。人工分析多用于有人机交互界面的目标程序,Web漏洞挖掘中多使用人工分析的方法。
2.Fuzzing技术
Fuzzing技术是一种基于缺陷注入的自动软件测试技术,它利用黑盒分析技术方法,使用大量半有效的数据作为应用程序的输入,以程序是否出现异常为标志,来发现应用程序中可能存在的安全漏洞。半有效数据是指被测目标程序的必要标识部分和大部分数据是有效的,有意构造的数据部分是无效的,应用程序在处理该数据时就有可能发生错误,可能导致应用程序的崩溃或者触发相应的安全漏洞。
根据分析目标的特点,Fuzzing可以分为三类:
动态Web页面Fuzzing,针对ASP、PHP、Java、Perl等编写的网页程序,也包括使用这类技术构建的B/S架构应用程序,典型应用软件为HTTP Fuzz;
文件格式Fuzzing,针对各种文档格式,典型应用软件为PDF Fuzz;
协议Fuzzing,针对网络协议,典型应用软件为针对微软RPC(远程过程调用)的Fuzz。
Fuzzer软件输入的构造方法与黑盒测试软件的构造相似,边界值、字符串、文件头、文件尾的附加字符串等均可以作为基本的构造条件。Fuzzer软件可以用于检测多种安全漏洞,包括缓冲区溢出漏洞、整型溢出漏洞、格式化字符串和特殊字符漏洞、竞争条件和死锁漏洞、SQL注入、跨站脚本、RPC漏洞攻击、文件系统攻击、信息泄露等。
与其它技术相比,Fuzzing技术具有思想简单,容易理解、从发现漏洞到漏洞重现容易、不存在误报的优点。同时它也存在黑盒分析的全部缺点,而且具有不通用、构造测试周期长等问题。
常用的Fuzzer软件包括SPIKE Proxy、Peach Fuzzer Framework、Acunetix Web Vulnerability Scanner的HTTP Fuzzer、OWASP JBroFuzz、WebScarab等。
3.补丁比对技术
补丁比对技术主要用于黑客或竞争对手找出软件发布者已修正但未尚公开的漏洞,是黑客利用漏洞前经常使用的技术手段。
安全公告或补丁发布说明书中一般不指明漏洞的准确位置和原因,黑客很难仅根据该声明利用漏洞。黑客可以通过比较打补丁前后的二进制文件,确定漏洞的位置,再结合其他漏洞挖掘技术,即可了解漏洞的细节,最后可以得到漏洞利用的攻击代码。
简单的比较方法有二进制字节和字符串比较、对目标程序逆向工程后的比较两种。第一种方法适用于补丁前后有少量变化的比较,常用的于字符串变化、边界值变化等导致漏洞的分析。第二种方法适用于程序可被反编译,且可根据反编译找到函数参数变化导致漏洞的分析。这两种方法都不适合文件修改较多的情况。
复杂的比较方法有Tobb Sabin提出的基于指令相似性的图形化比较和Halvar Flake提出的结构化二进制比较,可以发现文件中一些非结构化的变化,如缓冲区大小的改变,且以图形化的方式进行显示。
常用的补丁比对工具有Beyond Compare、IDACompare、Binary Diffing Suite(EBDS)、BinDiff、NIPC Binary Differ(NBD)。此外大量的高级文字编辑工具也有相似的功能,如Ultra Edit、HexEdit等。这些补丁比对工具软件基于字符串比较或二进制比较技术。
4.静态分析技术
静态分析技术是对被分析目标的源程序进行分析检测,发现程序中存在的安全漏洞或隐患,是一种典型的白盒分析技术。它的方法主要包括静态字符串搜索、上下文搜索。静态分析过程主要是找到不正确的函数调用及返回状态,特别是可能未进行边界检查或边界检查不正确的函数调用,可能造成缓冲区溢出的函数、外部调用函数、共享内存函数以及函数指针等。
对开放源代码的程序,通过检测程序中不符合安全规则的文件结构、命名规则、函数、堆栈指针可以发现程序中存在的安全缺陷。被分析目标没有附带源程序时,就需要对程序进行逆向工程,获取类似于源代码的逆向工程代码,然后再进行搜索。使用与源代码相似的方法,也可以发现程序中的漏洞,这类静态分析方法叫做反汇编扫描。由于采用了底层的汇编语言进行漏洞分析,在理论上可以发现所有计算机可运行的漏洞,对于不公开源代码的程序来说往往是最有效的发现安全漏洞的办法。
但这种方法也存在很大的局限性,不断扩充的特征库或词典将造成检测的结果集大、误报率高;同时此方法重点是分析代码的“特征”,而不关心程序的功能,不会有针对功能及程序结构的分析检查。
5.动态分析技术
动态分析技术起源于软件调试技术,是用调试器作为动态分析工具,但不同于软件调试技术的是它往往处理的是没有源代码的被分析程序,或是被逆向工程过的被分析程序。
动态分析需要在调试器中运行目标程序,通过观察执行过程中程序的运行状态、内存使用状况以及寄存器的值等以发现漏洞。一般分析过程分为代码流分析和数据流分析。代码流分析主要是通过设置断点动态跟踪目标程序代码流,以检测有缺陷的函数调用及其参数。数据流分析是通过构造特殊数据触发潜在错误。
比较特殊的,在动态分析过程中可以采用动态代码替换技术,破坏程序运行流程、替换函数入口、函数参数,相当于构造半有效数据,从而找到隐藏在系统中的缺陷。
常见的动态分析工具有SoftIce、OllyDbg、WinDbg等。
感想
各类计算机产品和技术不断深入人们的生活,其可能的安全漏洞和安全风险也应得到相应的重视。计算机安全风险,小到危害个人隐私,大到危害国家安全,我们不得不慎重对待。要想防范安全风险,首先要知道风险出现在什么地方,因此漏洞挖掘技术就体现出其应用价值。尤其是现在移动端设备与人们生活关系越发紧密,针对移动端漏洞的挖掘与修复更因该引起重视。
汇报总结
本小组汇报
论文题目:Spectre Attacks: Exploiting Speculative Execution
论文来源:39th IEEE Symposium on Security and Privacy(Oakland)
作者信息:
- Paul Kocher
- Independent
- Daniel Genkin
- University of Pennsylvania and University of Maryland
- Daniel Gruss
- Graz University of Technology
- Werner Haas
- Cyberus Technology
- Mike Hamburg
- Rambus, Cryptography Research Division
- Moritz Lipp
- Graz University of Technology
- Stefan Mangard
- Graz University of Technology
- Thomas Prescher
- Cyberus Technology
- Michael Schwarz
- Graz University of Technology
- Yuval Yarom
- University of Adelaide and Data
本文发表时间不到一年半,引用次数已经达到了416次。
Spectre Attacks(幽灵攻击)
现代处理器使用分支预测和推测执行来最大化性能。 例如,如果分支的目标取决于正在读取的内存值,则CPU将尝试获取目标并尝试提前执行。 当内存值最终到达时,CPU丢弃或提交推测计算。 推测逻辑在执行方式上是不忠实的,可以访问受害者的内存和寄存器,并且可以执行具有可测量副作用的操作。
幽灵攻击涉及诱使受害者以规范的方式执行在正确的程序执行期间不会发生的操作以及泄漏受害者的操作,可以通过侧信道向外界提供的机密信息。幽灵攻击结合了来自侧信道攻击,故障攻击和回归导向编程的方法,可以从受害者的内存中读取任意任意位置的内容。 更广泛地说,推测性执行实施违反了支持数字软件安全机制的安全假设,包括操作系统进程分离,静态分析,容器化,即时(JIT)编译以及对缓存的定时/侧通道攻击的对策。 这些攻击对实际系统构成严重威胁,因为在用于数百万台设备的英特尔,AMD和ARM的微处理器中发现了预测执行的功能的漏洞。
幽灵攻击就像字面所说的意思一样,来无影去无踪,当攻击发生时受害者在毫无察觉的情况下就被CPU的预测执行功能“出卖”了。
Speculative Execution(预测执行)
预测执行简单来说是一些具有预测执行能力的新型处理器,可以估计即将执行的指令,采用预先计算的方法来加快整个处理过程。
预测执行的设计理念是:加速大概率事件。
预测执行是高速处理器使用的一种技术,通过考虑可能的未来执行路径并提前地执行其中的指令来提高性能。例如,当程序的控制流程取决于物理内存中未缓存的值时,可能需要几百个时钟周期才能知道该值。除了通过空闲浪费这些周期之外,过程还会控制控制流的方向,保存其寄存器状态的检查点并且继续在推测的路径上推测性地执行该程序。当值从存储器中偶然到达时,处理器检查最初猜测的正确性。如果猜测错误,则处理器将寄存器状态恢复为存储的检查点并丢弃(不正确的)预测执行,如果猜测是正确的,则该部分代码已被执行过,不需要再次执行,因此带来了显著的性能增益。
可以发现,如果预测错误,即便程序真正执行到这里时错误结果被丢弃,但错误的结果还是短暂的出现在寄存器中,在被丢弃之前,这部分数据就很容易被泄露。
欺骗分支预测器
下面是一段可能被分支预测器错误预估的代码:

对于这段代码,攻击者首先使用有效的x调用相关代码,训练分支预测器判断该if为真。在执行过几次之后,if判断连续为真,在下一次需要从低速缓存加载array1_size时,为了不造成时钟周期的浪费,CPU的预测执行开始工作,此时它有理由判断if条件为真,因为之前均为真(加速大概率事件),于是直接执行下面的代码,也就是说此时即便x的值越界了,我们依然很有可能在高速缓存中查询到内存中array1[x]和array2[array1[x]*256]的值,当CPU发现预测错误时我们已经得到了需要的信息。
攻击过程及结果
攻击流程图如下:

获取目标内存地址的技术本论文没有介绍,个人以为可以堆内存地址进行监控,选择频繁被修改的地址。
攻击示例程序中的受害代码采用上面的例子,交替输入有效和恶意的参数:

在通过直接读取该处cache中的值确定攻击是否命中,当读取速度小于某个经验值时,则认为该数据在高速缓存中,判断为命中。当命中某个数值达到一定次数时判定命中结果:

本文作者声称这种攻击可以获取信息的速率在一定环境下可达10KB/s(10KB/second on an i7 Surface Pro 3)。
相似的攻击手段:meltdown
Meltdown是一种类似的微体系结构攻击,它利用无序执行来泄漏目标的物理内存。 Meltdown在两个主要方面与Spectre Attacks截然不同。 首先,与Spectre不同,Meltdown不使用分支预测来实现推测执行。 相反,它依赖于观察,当一条指令导致一个软中断时,正在无序执行的指令中止。第二,Meltdown利用特定于英特尔处理器的特权升级漏洞,由此 推测执行的指令可以绕过内存保护。 结合这些问题,Meltdown从用户空间访问内核内存。 此访问会导致软中断,但在发出软中断之前,访问后面的代码会通过缓存通道泄漏所访问内存的内容。与Meltdown不同,Spectre攻击适用于非Intel处理器,包括AMD和ARM处理器。 此外,KAISER补丁已被广泛应用于对Meltdown攻击的缓解,但不能防止幽灵攻击。
复现过程
- 实验环境:
- win10 专业版1809 64位、 win7旗舰版32位(VMware14 pro虚拟机)
- CPU: i5-8300H。
- 内存: 分别为16G,4G。
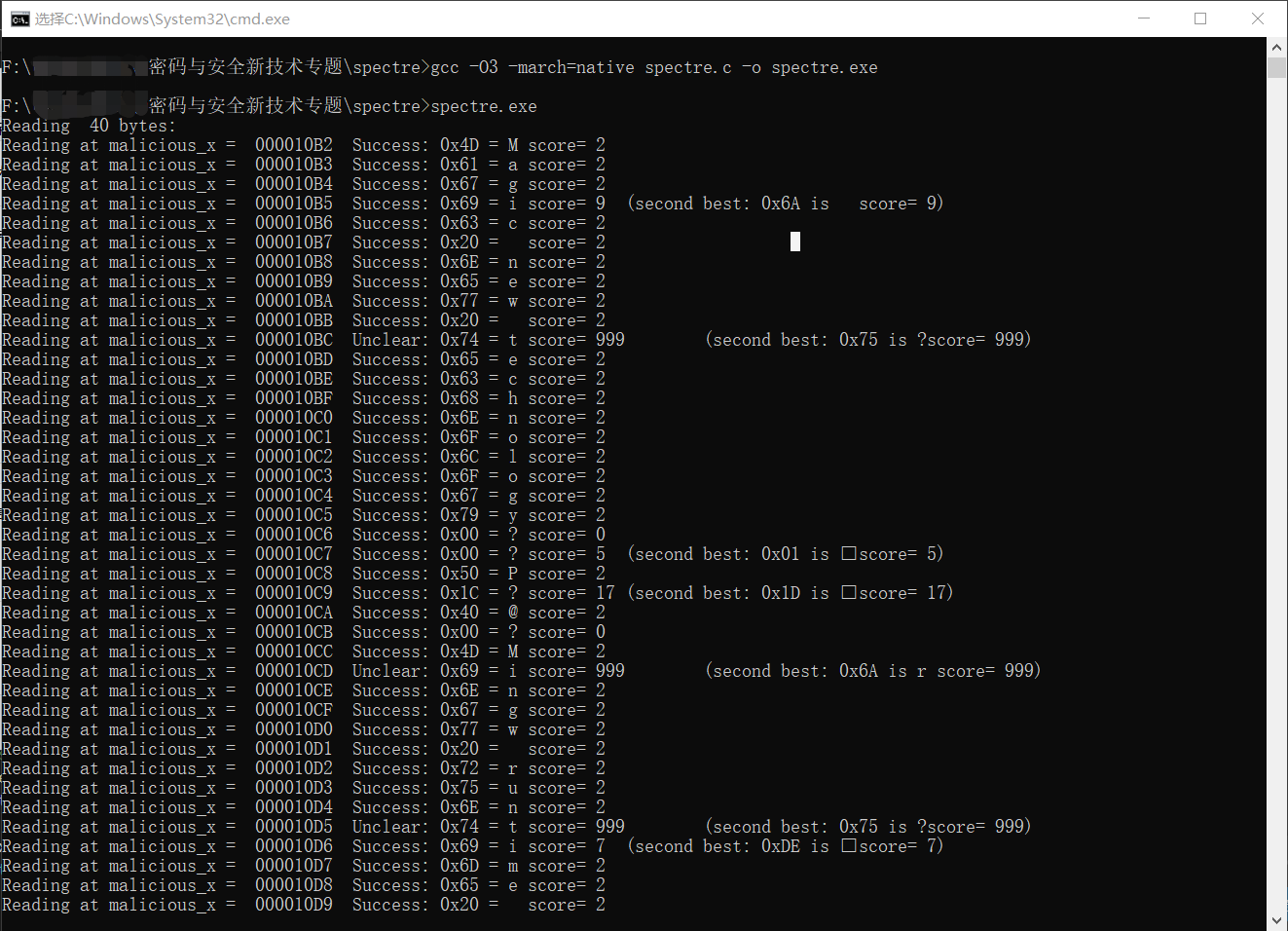
代码修改:原论文附录中提供的代码存在些许瑕疵,对于观察期望输出存在一定阻碍。
运行结果如图:
其他小组汇报总结
Finding Unknown Malice in 10 Seconds: Mass Vetting for New Threats at the Google-Play Scale
本文开发了一种名为MassVet的新技术,用于大规模审查应用程序,而无需了解恶意软件的外观和行为方式。与通常使用重量级程序分析技术的现有检测机制不同,文中所用的方法只是将提交的应用程序与已经在市场上的所有应用程序进行比较,重点关注那些共享类似UI结构(表示可能的重新打包关系)和共性的区别。一旦公共库和其他合法代码重用被删除,这种差异/通用程序组件就会变得非常可疑。研究中,本文在一个有效的相似性比较算法之上构建了这个“DiffCom”分析,该算法将应用程序的UI结构或方法的控制流图的显著特征映射到一个快速比较的值。在流处理引擎上实施了MassVet,并评估了来自全球33个应用市场的近120万个应用程序,即Google Play的规模。最后研究表明,该技术可以在10秒内以低错误检测率审核应用程序。此外,它在检测覆盖率方面优于VirusTotal(NOD32,赛门铁克,迈克菲等)的所有54台扫描仪,捕获了超过10万个恶意应用程序,包括20多个可能的零日恶意软件和数百万次安装的恶意软件。仔细观察这些应用程序可以发现有趣的新观察结果:例如,谷歌的检测策略和恶意软件作者的对策导致某些Google Play应用程序的神秘消失和重新出现。
核心技术结构:

v-core:
All Your GPS Are Belong To Us: Towards Stealthy Manipulation of Road Navigation Systems
这篇论文主要探讨了对道路导航系统进行隐身操纵攻击的可行性目标是触发假转向导航,引导受害者到达错误的目的地而不被察觉。其主要想法是略微改变GPS位置,以便假冒的导航路线与实际道路的形状相匹配并触发实际可能的指示。为了证明可行性,该论文首先通过实施便携式GPS欺骗器并在真实汽车上进行测试来执行受控测量。然后,该论文设计一个搜索算法来实时计算GPS移位和受害者路线。该论文使用追踪驾驶模拟(曼哈顿和波士顿的600辆出租车道路)进行广泛的评估,然后通过真实驾驶测试(攻击我们自己的车)来验证完整的攻击。最后,该研究组在美国和中国使用驾驶模拟器进行欺骗性用户研究,结果显示95%的参与者遵循导航没有意识到这种攻击就到了错误的目的地。
这种攻击在实施中应用了GPS设备的一个关键特征,即GPS设备在工作中根据频段和信号强度选择信号来源,没有对信号源进行身份验证。因此安全技术在日常生活中还存在很大的应用空间。
With Great Training Comes Great Vulnerability: Practical Attacks against Transfer Learning
本文提出了一个新的针对迁移学习的对抗性攻击,即对教师模型白盒攻击,对学生模型黑盒攻击。攻击者知道教师模型的内部结构以及所有权重,但不知道学生模型的所有权值和训练数据集。
本文的攻击思路:首先将target图狗输入到教师模型中,捕获target图在教师模型第K层的输出向量。之后对source图加入扰动,使得加过扰动的source图(即对抗样本)在输入教师模型后,在第K层产生非常相似的输出向量。由于前馈网络每一层只观察它的前一层,所以如果我们的对抗样本在第K层的输出向量可以完美匹配到target图的相应的输出向量,那么无论第K层之后的层的权值如何变化,它都会被误分类到和target图相同的标签。
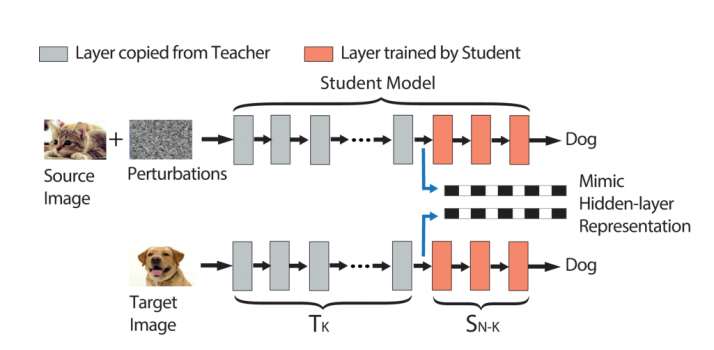
本文通过求解一个有约束的最优化问题来计算扰动。目标是是模拟隐藏层第K层的输出向量,约束是扰动不易被人眼察觉。即在扰动程度perturb_magnitude小于一定约束值(扰动预算P)的前提下,最小化对抗样本(扰动后的source image)第K层的输出向量与target image 第K层的输出向量的欧式距离。前人计算扰动程度都是使用Lp范数,但是它无法衡量人眼对于图像失真程度的感知。所以本文使用DSSIM计算扰动程度,它是一种对图像失真度的客观测量指标。

SafeInit: Comprehensive and Practical Mitigation of Uninitialized Read Vulnerabilities
由于C/C++不会像C#或JAVA语言,确保变量的有限分配,要求在所有可能执行的路径上对它们进行初始化。所以,C/C++代码可能容易受到未初始化的攻击读取。同时C/C++编译器可以在利用读取未初始化的内存是“未定义行为”时引入新的漏洞。
在本文中,提出了一种全面而实用的解决方案,通过调整工具链来确保所有栈和堆分配始终初始化,从而减轻通用程序中的这些错误。 SafeInit在编译器级别实现。
SafeInit通过强制初始化堆分配(在分配之后)和所有栈变量(无论何时进入范围)来减轻未初始化的值问题。这是通过修改编译器直接在所有点插入初始化调用来完成的。为了提供实用和全面的安全性,此工具必须在编译器本身内完成。 只需在编译过程中传递额外的加固标记即可启用SafeInit。SafeInit在首次使用之前初始化所有局部变量,作为新分配变量的作用域处理。SafeInit通过修改编译器编译代码的中间表示(IR),在每个变量进入作用域后进行初始化(例如内置memset)。
SafeInit的强化分配器可确保在返回应用程序之前将所有新分配的内存清零。我们通过修改现代高性能堆分配器tcmalloc来实现我们的强化分配器。同时还修改了LLVM,以便在启用SafeInit时将来自新分配的内存的读取视为返回零而不是undef。 同时,我们在安全分配器中执行覆盖所有堆分配函数以确保始终使用强化的分配器函数(对初始化堆分配是在分配之后进行强制初始化)。编译器知道我们的强化分配器正在使用中; 任何已分配内存的代码都不再使用未定义行为,并且编译器无法修改或删除。
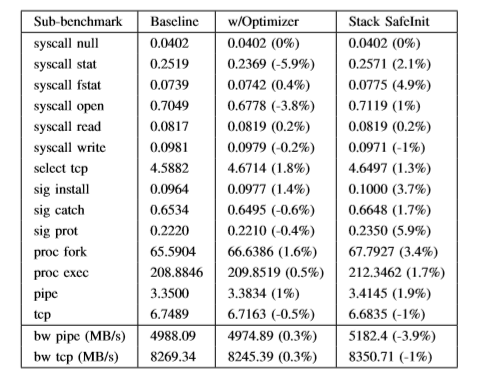
最后,通过优化器和无效存储消除提高SageInit的性能和安全性。运行结果如下:
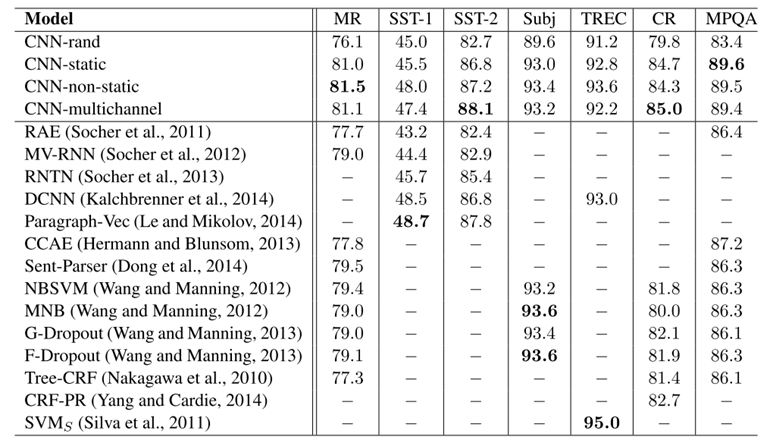
Convolutional Neural Networks for Sentence Classification
传统的文本分类方法主要是基于统计的机器学习方法,使用向量空间模型(vector space model,VSM)或者叫做词袋模型(bag of words),抽取文本中的单词特征,并利用TF-IDF方法计算每个单词的权重。这样,得到一个单词-文档矩阵,矩阵的行为不同的文档,矩阵的列为不同的单词特征。将这个矩阵输入至相应的文本分类器(e.g. SVM,NB,...),就可以实现文本的分类任务。这类方法使用的特征是单词的出现与否(较强一点是单词的词频),忽略了单词的顺序、单词构成的词组(n-grams)和单词与单词之间的语义相似度关系。在工程实践中实现较为容易,但是缺点也较为明显。
本文所提到的方法,将文本转换为类似图像的矩阵,采用CNN来完成文本分类任务,则更多的利用到单词的顺序和语义特征。
网络结构如下所示:

数据集:

实验结果:
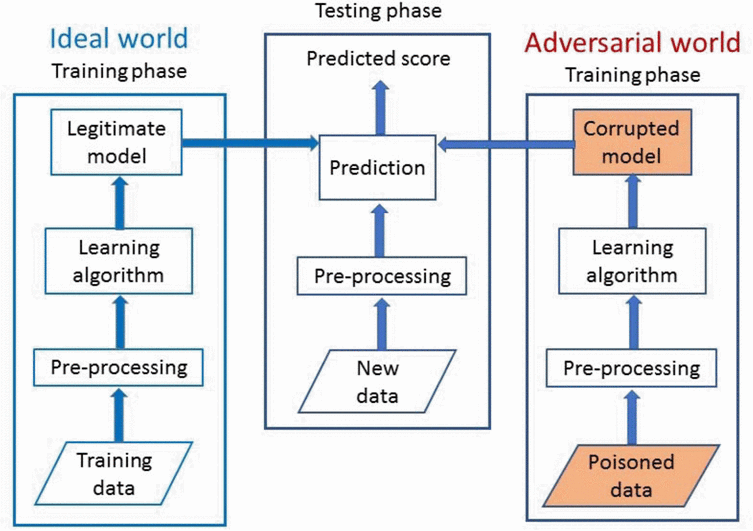
Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning
本文对线性回归模型的中毒攻击及其对策进行了第一次系统研究,提出了一个针对中毒攻击和快速统计攻击的新优化框架,该框架需要对培训过程的了解很少。
本文还采用原则性方法设计一种新的鲁棒防御算法,该算法在很大程度上优于现有的稳健回归方法。在医疗保健,贷款评估和房地产领域的几个数据集上广泛评估作者提出的攻击和防御算法。在案例研究健康应用中证明了中毒攻击的真实含义。
系统架构:
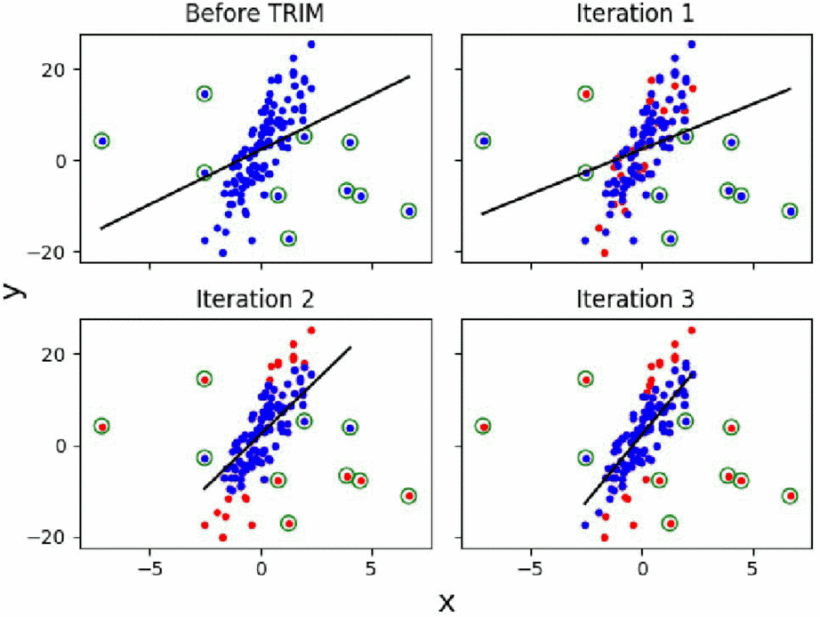
Trim算法及成果:
感想和体会
通过本课程的学习,我的视野得到了很大的扩展,对以前很多都知识听过名字的技术有了比较全面的了解。尤其是每次讲座后的论文阅读,让我从权威、专业的角度了解相关领域的前沿课题,对我今后的学习科研有很大的导向性帮助。期末深入学习并复现顶会论文的过程更是获益良多。幽灵攻击这个课题让我非常感兴趣,之前从没有想过看似神奇的CPU背后居然还有这种“龌龊”事,这也不得不引起我们进一步思考,许多现在运行看似良好的系统,是不是从机制上就存在着根本性的致命漏洞呢?对已知漏洞的防范较为简单,那么在面对未知漏洞时,如何做到即使不知道是否存在漏洞、存在什么样的漏洞,也能在漏洞被利用是尽可能减小损失呢?
对本课程的建议
顶会论文的深入学习及复现过程建议尽早展开,时间充足的情况下一方面选题可以更从容,尽量选到自己感兴趣的题目;其次复现过程也能做到更全面详细。就拿幽灵漏洞这个例子来说,时间更充足的话我还想深入了解一下微软针对幽灵漏洞发布的补丁,以及安卓、IOS等是否有针对幽灵漏洞的补丁。